Как использовать Hashcat для взлома паролей, содержащих нелатинские символы (русские буквы в пароле, китайские иероглифы и пр.)
Если пароль содержит русские символы или любые другие нелатинские (неанглийские) символы, то его также можно взломать в Hashcat, но дополнительно требуется понимание устройства строк, особенно при запуске атаки по маске.
Рассмотрим два случая, когда пароль содержит русские буквы или любые другие не латинские символы и делается запуск:
1) атаки по словарю
2) атаки по маске
Я буду взламывать MD5 хеш очень короткого слова «нет»:
echo -n 'нет' | md5sum df28b6f9df132e3be4db5b102433d3b1 -
Если для расчёта хеша строки вы используете echo, то крайне важно указывать опцию -n, которая предотвращает добавление символа новой строки – иначе каждый хеш для строки будет неверным! Смотрите также статью «Хеши: определение типа, подсчёт контрольных сумм, нестандартные и итерированные хеши».
Итак, у меня есть MD5 хеш df28b6f9df132e3be4db5b102433d3b1, в Hashcat этот хеш имеет номер 0 (опция -m 0), я буду взламывать его двумя способами: по словарю (опция -a 0) и по маске (опция -a 3).
Атака по словарю Hashcat когда в пароле русские буквы
Этот вариант проще, по сравнению с атакой по маске — достаточно убедиться, что словарь в той же самой кодировке, в какой был взламываемый пароль во время вычисления хеша.
Как узнать, в какой кодировке пароль, когда вычислялся хеш? По хешу это сделать невозможно — нужно учитывать обстоятельства, при которых был сделан хеш. Если это хеш пароля веб-сайта, то скорее всего пароль был в той же кодировке, что и страницы веб-сайта.
Свой хеш я получил в терминале, у которого кодировка установлена на UTF-8, поэтому моя строка была в кодировке UTF-8.
Если бы терминал был в другой кодировке, например, в «Кириллица WINDOWS-1251», то я получил бы совершенно другой хеш.
Поскольку хешированная строка была в кодировке UTF-8, то я создаю файл словаря с именем dic.txt в кодировке UTF-8. Содержимое моего файла:
да нет возможно позднее вряд ли совсем нет
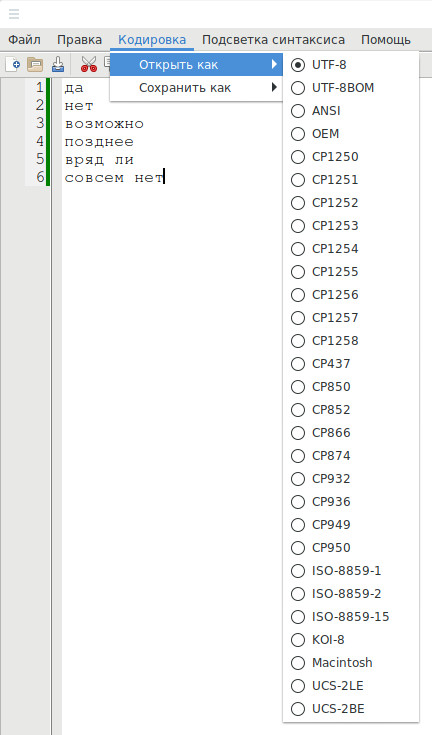
Теперь я запускаю атаку по словарю:
hashcat -m 0 -a 0 df28b6f9df132e3be4db5b102433d3b1 ./dic.txt
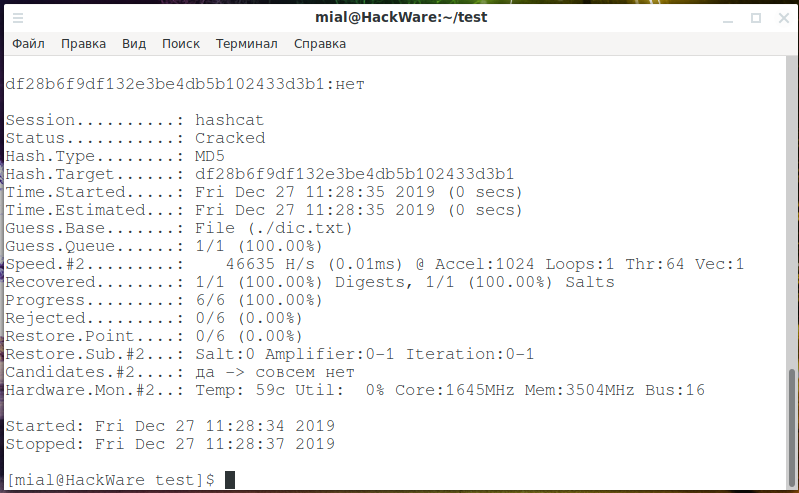
Пароль успешно взломан, об этом говорят строки:
df28b6f9df132e3be4db5b102433d3b1:нет Status...........: Cracked Recovered........: 1/1 (100.00%) Digests, 1/1 (100.00%) Salts
То есть при атаке по словарю ничего особо сложного — главное, чтобы словарь был в той же самой кодировке, в какой был пароль во время хеширования.
Поскольку я собираюсь продолжить свои опыты с этим же самым хешем, то из файла ~/.hashcat/hashcat.potfile я удаляю строку
df28b6f9df132e3be4db5b102433d3b1:нет
Иначе Hashcat вместо запуска нового брут-форса проверит, что хеш уже взломан и не запустит перебор паролей.
Атака по маске Hashcat когда в пароле русские буквы
А вот теперь всё немного сложнее. Интуитивно, на основе взлома по маске, когда в пароле только латинские символы и цифры, а также символы из однобайтовой кодировки (проще говоря, ASCII символы), можно составить следующую команду:
hashcat -m 0 -a 3 -1 тне df28b6f9df132e3be4db5b102433d3b1 ?1?1?1
Из нового в ней:
- -a 3 — означает атаку по маске
- -1 тне — пользовательский набор символов номер один — я специально расставил буквы в другом порядке.
- ?1?1?1 — маска, которая означает строку из трёх символов из первого пользовательского набора (это единицы, а не маленькие буквы L)
Результат:
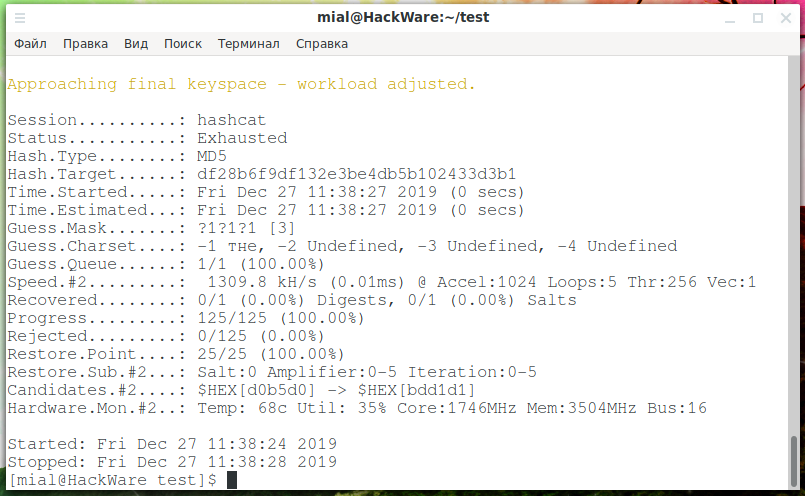
Пароль НЕ взломан. Обратите на одну интересную строку:
Progress.........: 125/125
Всего было перебрано 125 вариантов. Это слишком много. При длине маски в 3 символа, когда используется всего 3 буквы может быть только 33 = 27 вариантов. Откуда получилось 125?
Чтобы добавить ещё больше мистики, давайте запустим эту же самую команду, но теперь вместо маски из трёх символов, укажем маску из шести символов (хотя мы прекрасно помним, что мы взламываем хеш слова «нет», в котором ровно три символа):
hashcat -m 0 -a 3 -1 тне df28b6f9df132e3be4db5b102433d3b1 ?1?1?1?1?1?1
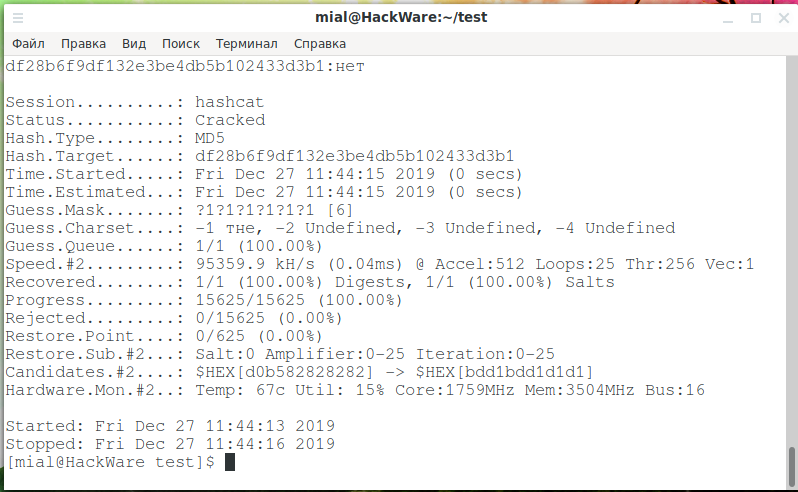
Внезапно, хеш взломан!
Вновь очищаем файл ~/.hashcat/hashcat.potfile, поскольку мы продолжим эксперименты.
Всё дело в том, что программам по взлому паролей (на самом деле, как и программам по хешированию и многим другим), нет никакого дела до используемой кодировки — они работают с байтами, с последовательностью байт.
Каждая буква нелатинского символа в кодировке UTF-8 состоит из двух байт. Поэтому когда мы указываем пользовательский набор символов следующим образом: -1 тне, то hashcat вместо трёх русских букв видим в этой строке шесть байт, а именно следующие:
- D1
- 82
- D0
- BD
- D0
- B5
Как вы можете убедиться, два байта являются повторяющимися — это D0. То есть имеется пять уникальных букв при длине слова в 3 символа, поэтому количество всех комбинаций равняется 53 = 125 — именно столько, как мы увидели в скриншоте выше, и было перебрано.
Когда мы указывали маску из трёх пользовательских символов, то составляемые кандидаты в пароли были длиной только в три байта, хотя слово «нет» длиной шесть байт — именно поэтому сработала маска в шесть символов.
Кстати, смотрите статью «ASCII и шестнадцатеричное представление строк. Побитовые операции со строками».
Итак, для запуска атаки по маске при взломе пароля из нелатинских символов (двухбайтовая кодировка) нужно удваивать длину маски. Что касается пользовательских наборов символов, то нужно учитывать кодировку консоли, либо сохранять символы пользовательских наборов в файлы с нужной кодировкой и указывать эти файлы с опциями -1, -2, -3 и -4.
Указанная схема будет работать, но есть серьёзное «но»: количество кандидатов в пароли увеличивается многократно, в том числе таких кандидатов в пароли, которые заведомо не подходят, т. к. складываются из байт в такие символы, которые отсутствуют в предполагаемом алфавите. Даже при трёх буквах в трёх буквенном слове мы получаем 125 / 27, то есть почти в 5 раз больше кандидатов в пароли. Причём ≈80% из них это просто мусор, состоящий из символов, которые не только не указаны для перебора, но вообще даже отсутствуют в русском алфавите. При увеличении длины слова и количестве букв, таких мусорных кандидатов в пароли будет ещё больше, а это означает многократное увеличение времени брут-форса.
Поэтому давайте подумаем, как можно оптимизировать процесс. Приглядимся к такой строке, которая содержит все символы русского алфавита:
АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдеёжзийклмнопрстуфхцчшщъыьэюя
Эта строка состоит из следующих байт:
D090 D091 D092 D093 D094 D095 D081 D096 D097 D098 D099 D09A D09B D09C D09D D09E D09F D0A0 D0A1 D0A2 D0A3 D0A4 D0A5 D0A6 D0A7 D0A8 D0A9 D0AA D0AB D0AC D0AD D0AE D0AF D0B0 D0B1 D0B2 D0B3 D0B4 D0B5 D191 D0B6 D0B7 D0B8 D0B9 D0BA D0BB D0BC D0BD D0BE D0BF D180 D181 D182 D183 D184 D185 D186 D187 D188 D189 D18A D18B D18C D18D D18E D18F
Обратите внимание, что в первой позиции всего два варианта D0 или D1.
Вернёмся к нашей строке «тне». В ней присутствуют следующие байты:
D182 D0BD D0B5
То есть в первой позиции будет только D0 или D1, а во второй позиции байтов могут быть 82, BD и B5. Создадим два пользовательских набора символов и явно укажем байты в каждом из них. Чтобы hashcat понимала, что мы указали байты, а не английские буквы и цифры, нужно использовать опцию —hex-charset. В результате получаем следующую команду:
hashcat -m 0 -a 3 -1 D0D1 -2 82BDB5 --hex-charset df28b6f9df132e3be4db5b102433d3b1 ?1?2?1?2?1?2
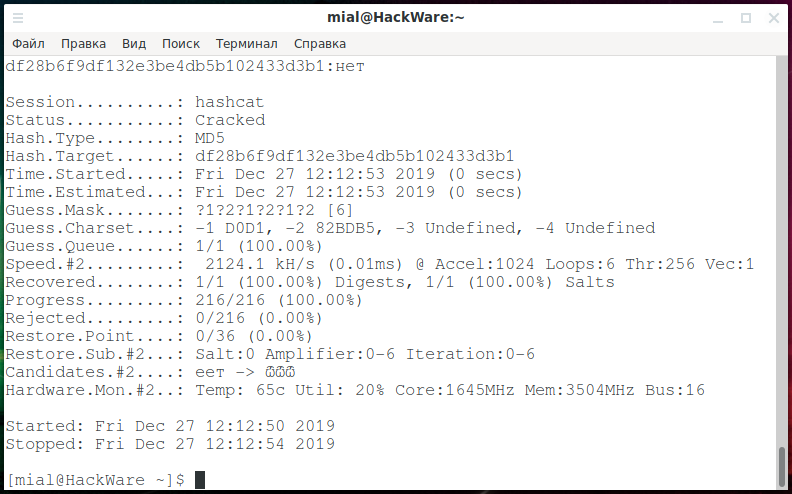
Напомню, в предыдущей команде запуска взлома хеша, когда мы указали маску из шести символов, было перебрано 15625 кандидатов в пароли (56 = 15625) — и это только для слова из трёх букв, когда известны все три буквы… Это слишком плохо.
Обратим на строку в последней команде запуска:
Progress………: 216/216 (100.00%)
Благодаря такой простенькой оптимизации количество кандидатов в пароли сократилось с 15625 до 216, то есть в 72 раза!
Думаю, суть идеи понятна, рассмотрим ещё несколько сопутствующих вопросов.
Как пользоваться файлами hashcat с алфавитами в различных кодировках
Вместе с hashcat поставляются файлы с расширением .hcchr — это файлы с символы определённых алфавитов в различных кодировках:
locate .hcchr
Пример русских символов в различных кодировках:
/usr/share/doc/hashcat/charsets/combined/Russian.hcchr /usr/share/doc/hashcat/charsets/special/Russian/ru_ISO-8859-5-special.hcchr /usr/share/doc/hashcat/charsets/special/Russian/ru_cp1251-special.hcchr /usr/share/doc/hashcat/charsets/standard/Russian/ru_ISO-8859-5.hcchr /usr/share/doc/hashcat/charsets/standard/Russian/ru_KOI8-R.hcchr /usr/share/doc/hashcat/charsets/standard/Russian/ru_cp1251.hcchr
Их можно использовать, не забывая удваивать длину масок для двухбайтовых кодировок. Но НЕ нужно их использовать, поскольку в этом случае будет проходить брут-форс без оптимизации, и большая часть перебираемых паролей будет заведомо не подходящими, что в разы увеличит время взлома.
Как узнать, какими байтами кодируется символ?
Следующая команда (замените слово «нет» на нужную строку или символ) покажет, из каких байт составлена строка:
echo -n "нет" | od -A n -t x1 d0 bd d0 b5 d1 82
С помощью команды iconv можно конвертировать строки и файлы в нужную кодировку:
iconv -f utf-8 -t iso-8859-1 < rockyou.txt | sponge rockyou.txt.iso
Если программа sponge не найдена в вашей системе, то установите пакет moreutils.
Также смотрите статью «Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux».
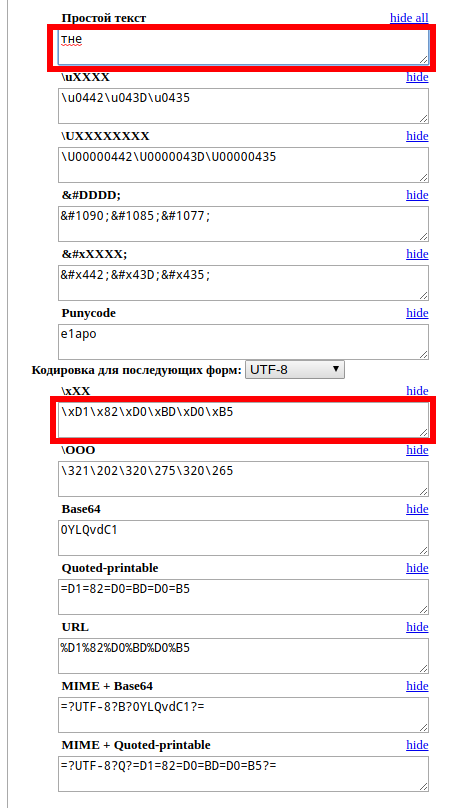
Дополнительно вы можете использовать онлайн сервис, который покажет байты, из которых составлен символ или строка: https://suip.biz/ru/?act=encoding-converter
Связанные статьи:
- Взлом рукопожатий (handshake) с использованием графического процессора в Windows (60.2%)
- Взлом паролей MS Office, PDF, 7-Zip, RAR, TrueCrypt, Bitcoin/Litecoin wallet.dat, htpasswd в Hashcat (60.2%)
- Базовое и продвинутое использование oclHashcat (Hashcat) для взлома WPA/WPA2 паролей из хендшейков (60.2%)
- Виды атак Hashcat (60.2%)
- Семейство программ *Hashcat: как научиться взламывать пароли, создавать и оптимизировать словари (60.2%)
- Использование файлов масок .hcmask в Hashcat для максимально гибкой замены символов (RANDOM - 57%)
Alexey, а в какой кодировке хэшируется NTLMv1/2 ? Пробую брутить по словарю сделаному в разных кодировках (ANSI, UTF8, cp1251 oem866), в кандидатах идёт перебор в HEX и … не находит.
(ИМХО Вопрос актуален, у многи стят руWin и пароли соотвутственно, а инфы на тему 0)
Приветствую! Вопрос очень интересный.
Как следует из Википедии:
То есть используется Unicode. Но проблема в том, что если в пароле используется русские символы, то hashcat не справляется. Я пробовал указывать шестнадцатеричные значения для латинских символов — всё работает, хеш взламывается. Если указывать шестнадцатеричные значения русских символов — не удаётся раскрыть пароль.
Я начинаю подозревать, что в hashcat какой-то баг.
Если вам интересно самим с этим повозиться, то вот этот файл написан на JavaScript и он генерирует NTLM хеш. Я экспериментировал с NTLM хешем, но, видимо, проблема у них одинаковая с NTLMv1/v2 хешами: https://hackware.ru/files/NTLM-hash-generator.zip
В конце файла вызов функции calculateHashes, в ней можете указать любой пароль, например:
calculateHashes("абвгде");Затем откройте этот файл в веб-браузере, во всплывающем окне будут показаны бинарные данные, в которые преобразована строка. После закрытия всплывающего окна на экран будет выведен NTLM хеш для этого пароля.
Я повозился пару часов и пришёл к мысли, что у меня на это не хватает мозгов )))))) Возможно, вы сможете разобраться — если да, то будет здорово, если вы напишите, что именно было не так.
Спасибо, но как то всё грустно. А с JrP тоже всё плохо? щас буду пробовать..
*JtR
Там utf-16le.
А JtR кириллицу норм ломает )).