Полное руководство по John the Ripper. Ч.5: атака на основе правил
Оглавление
1. Знакомство и установка John the Ripper
2. Утилиты для извлечения хешей
3. Как запустить взлом паролей в John the Ripper (как указать маски, словари, хеши, форматы, режимы)
4. Практика и примеры использования John the Ripper
5.1 Что такое Атака на основе правил в John the Ripper
5.2 Примеры Атаки на основе правил в John the Ripper
5.3 Правила John the Ripper, совместимые с Hashcat
5.6 Команды грамматики английского языка
5.7 Команды конверсии наборов символов
5.10 Класс символов и команды подобия
5.12 Числовые константы и переменные
5.14 Команды с произвольными символами
5.16 Практические примеры атаки на основе правил в John
5.16.1 Добавление произвольных символов в произвольные места
5.16.3 Отбор паролей, соответствующих определённой политике
5.16.4 На клавиатуре пользователя сломана кнопка
5.16.5 Пользователь заменяет символы
6. Брут-форс нестандартных хешей
7. Johnny — графический интерфейс для John the Ripper
8.
9.
Что такое Атака на основе правил в John the Ripper
Атака на основе правил — это модификация словарей на высоком уровне, когда они создаются и изменяются не только с помощью добавления новых символов, но и таких недоступным с помощью масок действий как:
- замена регистра всех или отдельных букв как в указанных позициях, так и в любых местах
- перевод всего слова в верхний или нижний регистр
- переключение регистра на противоположный
- удвоение и любое количество повторений слова
- обратный порядок слова
- обрезка слова
- удаление определённого диапазона символов
- замена определённых символов
- повторение, удаление или перезапись любых символов
- удаление слов, не удовлетворяющих указанным критериям (наличию или отсутствию символов или наборов символов; повторению символа или набора символов определённое количество раз, недостаточная или избыточная длина и прочее)
То есть правила позволяют изменять, создавать новые пароли, а также отклонять кандидаты в пароли по определённым многочисленным критериям.
Это мощный (и в своей основе не такой уж сложный) движок, который может вам пригодиться в каких-нибудь необычных ситуациях.
Примеры Атаки на основе правил в John the Ripper
Атака на основе правил есть и в Hashcat (будет статья!). Если вы уже освоили Атаку на основе правил в Hashcat, то там нужно создавать файлы с правилами и указывать их с помощью опций. У John the Ripper тоже есть опция —rules и инстинктивно можно попробовать подставить туда файл с правилами, но это не сработает. Все правила нужно указывать в конфигурационном файле. Большая статья по конфигурации и оставшимся опциям John уже на подходе, пока просто отмечу, что конфигурационный файл в операционной системе Linux называется john.conf. Если вы установили John the Ripper из исходного кода, то этот файл находится в той же папке, что и исполнимый файл john. Если вы установили из стандартного репозитория вашего дистрибутива, то этот файл находится в папке /etc/john/john.conf, а также продублирован в /usr/share/john/john.conf. Файл также может находиться в текущей рабочей директории или во всех местах сразу. Файлы не дополняют друг друга — последний загруженный файл перезаписывает предыдущие. В Windows файл называется john.ini.
Чтобы понять, что нет ничего страшного в этих правилах, начнём с быстрой демонстрации.
Итак, если у вас Linux, то откройте файл /usr/share/john/john.conf:
sudo gedit /usr/share/john/john.conf
Ближе к концу добавьте туда следующие строки:
[List.Rules:Toggle] T0 T1 T2 T0T1 T1T2 T0T2 T0T1T2 [List.Rules:Double] d p5 [List.Rules:Reflect] f [List.Rules:Reverse] r
В этих строках мы установили четыре набора правил, они называются Toggle (меняет регистр одной из трёх первых букв, затем двух из трёх первых, а затем всех трёх первых букв), Double (удваивает слово, а также записывает слово 5 раз подряд), Reflect (отражает содержимое слова и добавляет к имеющемуся), Reverse (перезаписывает слово задом наперёд). Значение всех букв и цифр мы ещё разберём, но вы могли уже и догадаться что они означают в правилах выше. Названия правил взяты произвольно, можно выбрать любые.
Сохраните конфигурационный файл.
Создайте файл passwords.txt с паролями для тестов, пример моего файла:
craig666 Craig688
Теперь john нужно запускать с опциями:
- —rules — после неё указывается название набора применяемых правил
- —wordlist — путь до словаря
- —stdout — просто означает выводить созданные пароли в стандартный вывод
Запускаем первую команду:
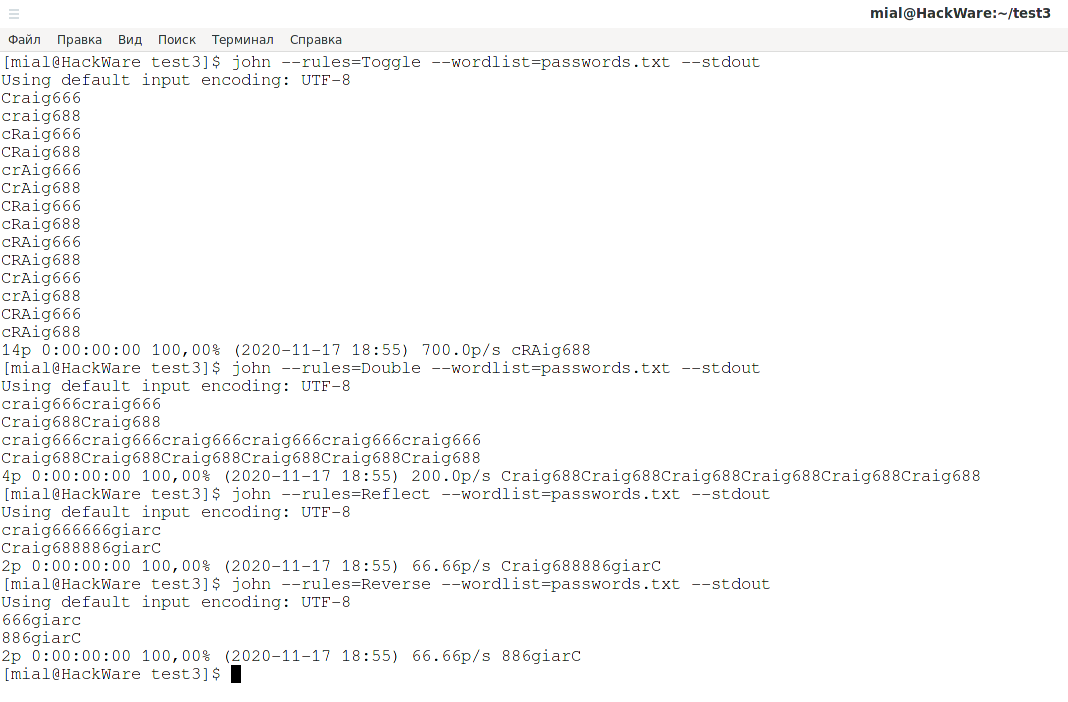
john --rules=Toggle --wordlist=passwords.txt --stdout
Получаем:
Craig666 craig688 cRaig666 CRaig688 crAig666 CrAig688 CRaig666 cRaig688 cRAig666 CRAig688 CrAig666 crAig688 CRAig666 cRAig688
Пробуем второй набор правил:
john --rules=Double --wordlist=passwords.txt --stdout
Получаем:
craig666craig666 Craig688Craig688 craig666craig666craig666craig666craig666craig666 Craig688Craig688Craig688Craig688Craig688Craig688
Третий набор:
john --rules=Reflect --wordlist=passwords.txt --stdout
Вывод:
craig666666giarc Craig688886giarC
Последний, в котором слова пишутся задом наперёд:
john --rules=Reverse --wordlist=passwords.txt --stdout
Получаем:
666giarc 886giarC
Группа правил может быть собрана как в одну строку, так и распределена по нескольким строкам.
Каждая строка может содержать как одно правило, так и множество. Много правил пишутся подряд и не разделяются никакими знаками, либо их можно разделить пробелами, обе записи (с пробелами и без) являются равнозначными.
Правила на одной строке применяются к словам одновременно. То есть если нужно сделать сразу несколько последовательных преобразований и получить один результат из одного слова, то запишите правила в одну строку.
Если нужно сделать несколько преобразований и сохранить результат каждого из них, то запишите правила на отдельных строках.
Например,
T0 T1 T2
Это три правила, они меняют регистр в первом, втором и третьем символах слова и затем сохранят все три варианта. То есть из одного слова получается ещё три модификации и каждая из них сохраняется.
А правило
T0T1T2
точно также меняет регистр в первом, втором и третьем символах слова, но сохраняет только одно результирующее слово.
Можно сочетать в одном наборе правил строки из одного правила и строки из множества правил.
В этих примерах опция —stdout использовалась только для наглядности, при реальном взломе эта опция не нужна. Либо вы можете использовать её для генерации словарей по указанным правилам.
Вы можете указать в конфигурационном файле любое количество наборов правил и использовать их в любое время или не использовать вовсе.
Пример использование правил: сделать словарь подходящим под известную политику требований к паролям; или сделать так, чтобы все пароли начинались с заглавной буквы, а другие буквы были прописными.
Как вы можете убедиться, ничего сложного. Теперь давайте рассмотрим значения всех правил (функций).
Правила John the Ripper, совместимые с Hashcat
Следующие функции на 100% совместимы с Hashcat (кроме WN).
| Имя | Функция | Описание | Пример правила | Слово на входе | Слово на выходе |
|---|---|---|---|---|---|
| Ничего | : | ничего не делать | : | p@ssW0rd | p@ssW0rd |
| Нижний регистр | l | Сделать строчными все буквы | l | p@ssW0rd | p@ssw0rd |
| Верхний регистр | u | Сделать заглавными все буквы | u | p@ssW0rd | P@SSW0RD |
| Капитализация | c | Сделать заглавной первую букву, а остальные маленькими | c | p@ssW0rd | P@ssw0rd |
| Обратная капитализация | C | Сделать маленькой первую букву, а остальныме заглавными | C | p@ssW0rd | p@SSW0RD |
| Переключить регистр | t | Изменить на противоположный регистр всех символов в слове | t | p@ssW0rd | P@SSw0RD |
| Переключить @ | TN | Переключить регистр символа в позиции N | T3 | p@ssW0rd | p@sSW0rd |
| Как SHIFT | WN | Переключить символ в позиции N как это делает клавиша SHIFT | W1 | p@ssW0rd | p2ssW0rd |
| Обратить | r | Обратить всё слово | r | p@ssW0rd | dr0Wss@p |
| Дублицировать | d | Продублировать всё слово | d | p@ssW0rd | p@ssW0rdp@ssW0rd |
| Дублицировать N | pN | Добавить дубликаты слова N раз | p2 | p@ssW0rd | p@ssW0rdp@ssW0rdp@ssW0rd |
| Отразить | f | Дублицировать обратное слово | f | p@ssW0rd | p@ssW0rddr0Wss@p |
| Повернуть влево | { | Повернуть слово влево | { | p@ssW0rd | @ssW0rdp |
| Повернуть вправо | } | Повернуть слово вправо | } | p@ssW0rd | dp@ssW0r |
| Добавить символ | $X | Добавить символ X в конец | $1 | p@ssW0rd | p@ssW0rd1 |
| Предварить символом | ^X | Добавить символ X в начало | ^1 | p@ssW0rd | 1p@ssW0rd |
| Обрезать слева | [ | Удалить первый символ | [ | p@ssW0rd | @ssW0rd |
| Обрезать справа | ] | Удалить последний символ | ] | p@ssW0rd | p@assW0r |
| Удалить @ N | DN | Удаляет символ в позиции N | D3 | p@ssW0rd | p@sW0rd |
| Извлечь диапазон | xNM | Извлекает M символов, начиная с позиции N | x04 | p@ssW0rd | p@ss |
| Пропустить диапазон | ONM | Удаляет M символов, начиная с позиции N | O12 | p@ssW0rd | psW0rd |
| Вставить @ N | iNX | Вставляет символ X в позицию N | i4! | p@ssW0rd | p@ss!W0rd |
| Переписать @ N | oNX | Перезаписывает символ в позиции N на X | o3$ | p@ssW0rd | p@s$W0rd |
| Обрезать @ N | 'N | Обрезает слово на позиции N | '6 | p@ssW0rd | p@ssW0 |
| Заменить | sXY | Заменяет все вхождения X на Y | ss$ | p@ssW0rd | p@$$W0rd |
| Стереть | @X | Стирает все вхождения X | @s | p@ssW0rd | p@W0rd |
| Дублицировать первый N | zN | Дублицирует первый символ N раз | z2 | p@ssW0rd | ppp@ssW0rd |
| Дублицировать последний N | ZN | Дублицирует первый символ N раз | Z2 | p@ssW0rd | p@ssW0rddd |
| Дублицировать всё | q | Дублицирует каждый символ | q | p@ssW0rd | pp@@ssssWW00rrdd |
| Извлечь память | XNMI | Вставляет подстроку длиной M начиная с позиции N слова, сохранённого в памяти, на позиции I | lMX428 | p@ssW0rd | p@ssw0rdw0 |
| Добавить память | 4 | Добавляет слово, сохранённое в памяти, к текущему слову | uMl4 | p@ssW0rd | p@ssw0rdP@SSW0RD |
| Предварить памятью | 6 | Слово, сохранённое в памяти, ставит перед текущим словом | rMr6 | p@ssW0rd | dr0Wss@pp@ssW0rd |
| Запомнить | M | Запоминает текущее слово | lMuX084 | p@ssW0rd | P@SSp@ssw0rdW0RD |
WN — это надмножество TN. В то время как TN переключает только регистр букв алфавита, например. «a» ↔ «A», команда WN также будет переключать с помощью Shift. Это похоже на использование Shift (или её отключение) на клавиатуре США, например. «1» ↔ «!».
Все они поддерживают кодировку. Например, если движок правил работает под управлением CP737, он также будет правильно распознавать греческие буквы и заглавные/строчные буквы.
Флаги отклонения правил
| Фнукция | Описание |
|---|---|
| -: | no-op: не отклонять |
| -c | отклонить это правило, если текущий тип хэша не чувствителен к регистру |
| -8 | отклонить это правило, если текущий тип хэша не использует 8-битные символы |
| -s | отклоняет это правило, если некоторые хэши паролей не были разделены при загрузке |
| -p | отклонить это правило, если в настоящее время не разрешены команды пар слов |
| -u | отклонить это правило, если механизм правил не работает в режиме UTF-8 (внутренняя кодовая страница не настроена) |
| -U | отклонить это правило, если механизм правил работает в режиме UTF-8 |
| ->N | отклоняет это правило, если не поддерживается длина N или более |
| -<N | отклонить это правило, если не поддерживается длина N или меньше (—min-length) |
Команды управления длиной
| Функция | Описание |
|---|---|
| <N | отклонить слово, если оно не короче N символов |
| >N | отклонить слово, если оно не превышает N символов |
| _N | отклонить слово, если оно не состоит из N символов |
| 'N | обрезать слово до длины N |
| aN | отклонить слово, если оно не будет передавать минимальную/максимальную длину после добавления N символов. Используется для раннего отказа |
| bN | отклоняет слово, если оно не пройдёт через минимальную/максимальную длину после удаление N символов |
Команды грамматики английского языка
| Функция | Описание |
|---|---|
| p | во множественном числе: "crack" -> "cracks" и т. д. (только строчные буквы) |
| P | в прошедшем времени: "crack" -> "cracked" и т. д. (только строчные буквы) |
| I | инговая форма: "crack" -> "cracking" и т. д. (только строчные буквы) |
Команды конверсии наборов символов
| Функция | Описание |
|---|---|
| S | сдвиг регистра: "Crack96" -> "cRACK(^" |
| V | строчные гласные, прописные согласные: "Crack96" -> "CRaCK96" |
| R | сдвинуть каждый символ вправо с помощью клавиатуры: "Crack96" -> "Vtsvl07" |
| L | сдвигает каждый символ влево с помощью клавиатуры: "Crack96" -> "Xeaxj85" |
ПРИМЕЧАНИЕ, из них только S и V поддерживают кодировки.
Команды доступа к памяти
| Функция | Описание |
|---|---|
| M | запомнить слово (для использования с «Q», «X» или для обновления «m») |
| Q | запрашивает память и отклоняет слово, если оно не изменилось |
| XNMI | извлекает из памяти подстроку NM и вставляет в текущее слово в I |
Если «Q» или «X» используются без предшествующей «M», они читаются с начального «слова». Другими словами, вы можете предположить, что в начале каждого правила подразумевается «M», и нет необходимости когда-либо начинать правило с «M» («M» не несёт действия). Единственное разумное использование "M" — это середина правила, после того как некоторые команды, возможно, изменили слово.
Предполагаемое использование команды «Q» — помочь избежать дублирования паролей-кандидатов, которые могут возникнуть из-за нескольких схожих правил. Например, если у вас есть правило «l» (нижний регистр) где-то в вашем наборе правил, и вы хотите добавить правило «lr» (нижний регистр и обратный порядок символов), вы можете вместо этого записать последнее как «lMrQ», чтобы избежать дублирования возможных пароли для палиндромов.
Команда «X» извлекает подстроку из памяти (или из начального слова, если «M» никогда не использовалось), начиная с позиции N (в запомненном или начальном слове) и продолжая до M символов. Он вставляет подстроку в текущее слово в позиции I. Целевая позиция может быть "z" для добавления подстроки, "0" чтобы поставить её перед словом, или это может быть любая другая допустимая числовая константа или переменная. В некоторых примерах использования, предполагая, что мы находимся в начале правила или после буквы «M», будет «X011» (дублировать первый символ), «Xm1z» (дублировать последний символ), «dX0zz» (трижды повторить слово), «<4X011X113X215» (дублировать каждый символ в коротком слове), «>9x5zX05z» (повернуть длинные слова налево на 5 символов, аналогично «>9vam4Xa50'l» (повернуть вправо на 5 символов, то же самое, что и «>9}}}}}»).
Числовые команды
| Функция | Описание |
|---|---|
| vVNM | обновляет "l" (длину), затем вычитает M из N и присваивает переменной V |
«l» устанавливается равным текущей длине слова, и его новое значение может использоваться этой же командой (если N или/и M также равно «l»).
V должен быть от "a" до "k". N и M могут быть любыми допустимыми числовыми константами или инициализированными переменными. Можно ссылаться на одну и ту же переменную в одной команде более одного раза, даже три раза. Например, «va00» и «vaaa» оба установят переменную «a» в ноль (но для последнего потребуется, чтобы «a» была предварительно инициализирована), тогда как «vil2» установит для переменной «i» текущее значение длины слова минус 2. Если "i" затем используется в качестве позиции символа перед дальнейшим изменением слова, оно будет относиться ко второму символу с конца. Нормально, чтобы промежуточные значения переменных становились отрицательными, но такие значения не должны использоваться напрямую как позиции или длины. Например, если мы последуем нашему «vil2» где-нибудь позже в том же правиле с «vj02vjij», мы установим «j» равным «i» плюс 2, или длину слова на момент обработки командой «vil2» ранее в правиле.
Класс символов и команды подобия
| Функция | Описание |
|---|---|
| sXY | заменить все символы X в слове на Y |
| s?CY | заменить все символы класса C в слове на Y |
| @X | удалить все символы X из слова |
| @?C | удалить все символы класса C из слова |
| !X | отклонить слово, если оно содержит символ X |
| !?C | отклонить слово, если оно содержит символ из класса C |
| /X | отклонить слово, если оно не содержит символа X |
| /?C | отклонить слово, если оно не содержит символа в классе C |
| =NX | отклонить слово, если символ в позиции N не равен X |
| =N?C | отклонить слово, если символ в позиции N не находится в классе C |
| (X | отклоняет слово, если его первым символом не является X |
| (?C | отклонить слово, если его первый символ не находится в классе C |
| )X | отклоняет слово, если его последний символ не X |
| )?C | отклонить слово, если его последний символ не находится в классе C |
| %NXX | отклоняет слово, если оно не содержит хотя бы N экземпляров X |
| %N?C | отклоняет слово, если оно не содержит хотя бы N символов класса C |
| U | отклонить слово, если оно не является допустимым UTF-8 (используйте с -u rule reject) |
| eC | регистр заголовка, где C — разделительный знак |
| e?C | регистр заголовка с символами из класса C в качестве разделительных символов |
ПРИМЕЧАНИЕ. Смотрите правило «E» для hashcat, которое устанавливает общий регистр для заголовков с пробелами. Правило «е» также посвящено этому.
Обратите внимание, что U принимает простой ASCII. Он будет отклонять только слова, которые содержат 8-битные символы, но не могут быть проанализированы как UTF-8. Его можно использовать для отклонения неверных входных слов или для отклонения неверных выходных слов после применения других команд.
Классы символов
| Функция | Описание |
|---|---|
| ?? | соответствует "?" |
| ?v | соответствует гласным: "aeiouAEIOU" |
| ?c | соответствует согласным: "bcdfghjklmnpqrstvwxyzBCDFGHJKLMNPQRSTVWXYZ" |
| ?w | соответствует пробелам: пробелам и символам горизонтальной табуляции |
| ?p | соответствует пунктуации: ".,:;'?!`" и символу двойной кавычки |
| ?s | соответствует символам "$%^&*()-_+=|\<>[]{}#@/~" |
| ?l | соответствует строчным буквам [a-z] |
| ?u | соответствует прописным буквам [A-Z] |
| ?d | соответствует цифрам [0-9] |
| ?a | соответствует буквам [a-zA-Z] |
| ?x | соответствует буквам и цифрам [a-zA-Z0-9] |
| ?o | соответствует управляющим символам |
| ?y | соответствует допустимым символам |
| ?z | соответствует всем символам |
| ?b | соответствует символам с 8-битным набором (мнемоника "b для бинарного") |
| ?N | де N это 0…9 — классы символов, определяемые пользователем. Они соответствуют символами, определённым в john.conf в разделе [UserClasses] |
Дополнение к классу можно указать, набрав его имя в верхнем регистре. Например, «?D» соответствует всему, кроме цифр.
Если вы скомпилировали John с поддержкой кодировок, соответствующие национальные символы добавляются в соответствующие классы. Таким образом, в режиме ISO-8859-1 обозначение ?l будет включать àáâãäåæçèéêëìíîïðñòóôõöøùúûüýþßÿ, тогда как в режиме ASCII это только a-z.
Числовые константы и переменные
Можно указывать числовые константы и ссылаться на переменные с помощью следующих символов:
| Функция | Описание |
|---|---|
| 0…9 | означает 0…9 |
| A…Z | означает 10…35 |
| # | означает min_length |
| @ | означает (min_length — 1) |
| $ | означает (min_length + 1) |
| * | означает max_length |
| — | означает (max_length — 1) |
| + | означает (max_length + 1) |
| a…k | определяемые пользователем числовые переменные (с помощью команды "v") |
| l | начальная или обновлённая длина слова (обновляется всякий раз, когда используется "v") |
| m | позиция начального или последнего символа запомненного слова |
| p | позиция последнего символа, найденного с помощью команд "/" или "%" |
| z | "бесконечная" позиция или длина (после конца слова) |
Здесь min/max_length — это минимальная/максимальная длина пароля, поддерживаемая для текущего типа хэша (возможно, переопределена параметрами —min/max-len).
Они могут использоваться для указания позиций символов, длины подстроки и других числовых параметров для правил команд, соответствующих данной команде. Позиции символов нумеруются, начиная с 0. Так, например, начальное значение «m» (позиция последнего символа) на единицу меньше, чем «l» (длина).
Строковые команды
| Функция | Описание |
|---|---|
| AN"STR" | вставить строку STR в слово в позиции N |
Чтобы добавить строку в конце слова, укажите позицию «z». Чтобы строку поставить перед словом, укажите в качестве позиции «0».
Хотя использование символа двойных кавычек удобно для чтения, вы можете использовать любой другой символ, не найденный в STR. Это особенно полезно, когда STR содержит символ двойной кавычки. Невозможно экранировать символ кавычки в строке (не позволяя ему закончить строку и команду), но вы можете добиться того же эффекта, указав несколько команд одну за другой. Например, если вы решили использовать косую черту в качестве символа кавычки, но, тем не менее, он встречается в строке, и вы не хотите пересматривать свой выбор, вы можете написать «Az/yes/$/Az/no/», который добавит строку «yes/no». Конечно, проще и эффективнее использовать, скажем, «Az,yes/no,» для того же эффекта.
Команды с произвольными символами
Можно использовать любой 8-битный символ внутри Ax"str", а $c или ^c или в настройках препроцессора $[c…] или ^[c…]. Метод, используемый в john, похож на создание произвольного символа в языке C. Это синтаксис \xhh, где hh — это 2 шестнадцатеричных символа. Итак, Az"\x1b[2J" добавит тогда escape-последовательность ansi, чтобы очистить экран до конца текущего пароля. Или что-то вроде $\x0a добавит символ новой строки в конец слова. Эти экранированные символы также правильно работают во всех командах классов символов.
Препроцессор правил
Препроцессор используется для объединения похожих правил в одну строку исходного кода. Например, если вам нужно заставить John пробовать слова в нижнем регистре с добавлением цифр, вы можете написать правило для каждой цифры, всего 10 правил. А теперь представьте добавление двузначных чисел — файл конфигурации станет большим и некрасивым.
С препроцессором вы можете сделать это проще. Просто напишите одну исходную строку, содержащую общую часть этих правил, за которой следует список символов, которые вы бы поместили в отдельные правила, в квадратных скобках (как вы это делаете в регулярном выражении). Затем препроцессор сгенерирует для вас правила (при запуске John для проверки синтаксиса и ещё раз при взломе, но никогда не сохранит все расширенные правила в памяти). В приведённых выше примерах исходными строками будут «l$[0-9]» (нижний регистр и добавление цифры) и «l$[0-9]$[0-9]» (нижний регистр и добавление двух цифр). Эти исходные строки будут расширены до 10 и 100 правил соответственно. Между прочим, команды препроцессора обрабатываются справа налево, а списки символов обрабатываются слева направо, что приводит к естественному порядку чисел в приведённых выше примерах и в других типичных случаях. Обратите внимание, что допустимы произвольные комбинации диапазонов символов и списков символов. Например, «[aeiou]» будет использовать гласные, тогда как «[aeiou0-9]» будет использовать гласные и цифры. Если вам нужно, чтобы John попробовал гласные, за которыми следуют все другие буквы, вы можете использовать «[aeioua-z]» — препроцессор достаточно умён, чтобы не создавать повторяющиеся правила в таких случаях (хотя это поведение можно отключить с помощью «\r», магической escape-последовательности, описанная ниже).
В правилах есть некоторые специальные символы («[» запускает список символов препроцессора, «—» отмечает диапазон внутри списка и т. д.). Вы должны поставить перед ними обратную косую черту («\»), если вы хотите поместить их внутри правила без использования их особого значения. Конечно, то же самое относится и к самому символу "\". Кроме того, если вам нужно запустить список символов препроцессора в самом начале строки, вам нужно будет поставить перед ним префикс ":" (команда правила no-op), иначе он будет рассматриваться как начало нового раздела.
Наконец, препроцессор поддерживает некоторые магические escape-последовательности. Они начинаются с обратной косой черты и используют символы, которые обычно не нужно экранировать. В следующем абзаце, описывающем экранирование, слово «диапазон» относится к одному экземпляру комбинации списков символов и/или диапазонов, помещённых в квадратные скобки, как показано выше.
В настоящее время поддерживаются обозначения от «\1» до «\9» для обратных ссылок на предыдущие диапазоны (с диапазонами, пронумерованными от 1, слева направо, они будут заменены тем же символом, который в настоящее время найден ссылающимся диапазоном), «\0» для обратной ссылки на непосредственно предшествующий диапазон, «\p» перед диапазоном, чтобы этот диапазон обрабатывался «параллельно» со всеми предыдущими диапазонами, от "\p1" до "\p9" для обработки диапазона «параллельно» с конкретным указанным диапазоном, «\p0», чтобы диапазон обрабатывался «параллельно» с непосредственно предшествующим диапазоном, и «\r», чтобы позволить диапазону воспроизводить повторяющиеся символы. Последовательность «\r» полезна только в том случае, если диапазон «параллелен» другому или если есть хотя бы один другой диапазон, «параллельный» этому, потому что вы не должны фактически создавать повторяющиеся правила. Также экранирование \xhh корректно работает в препроцессоре, чтобы разрешить любой символ. Правило предварительной обработки [\x01-\xff] будет заменено 255 символами (отсутствует нулевой байт, который не может быть обработан JtR).
Практические примеры атаки на основе правил в John
1. Добавление произвольных символов в произвольные места
Предположим, пользователь шифровал файлы одним и тем же паролем, допустим это «long_password», но в какой-то момент решил усложнить пароль и добавил в него несколько символов (от 1 до 3). Пользователь помнит, что это какие-то строчные буквы, но какие именно и в какие места пароля он их добавил — не помнит.
Задача: составить правила модификации пароля на основе указанных условий.
Воспользуемся функцией «iNX», которая вставляет символ X в позицию N.
Правило, которое добавляет маленькие буквы ([a-z]) в позиции от 0 до 13-ой:
i[0-9A-D][a-z]
Последней выбрана 13 позиция, поскольку в слове long_password всего 13 букв. Нулевая позиция — это перед словом, тринадцатая позиция — это после пароля.
В отличие от Hashcat, John the Ripper поддерживает диапазоны, поэтому символы для вставки указаны как диапазон — [a-z].
Позиции для вставки символов также указаны как диапазон — [0-9A-D]. В ней «0-9» означает вставить в позицию от 0 до 9. А «A-D» означает вставить в позицию от 10-ой до 13-ой.
Предыдущее правило вставляет только одну букву. Для вставки двух любых маленьких букв в любое место слова используется следующее правило:
i[0-9A-D][a-z] i[0-9A-D][a-z]
Оно получено из предыдущего простым удвоением записи.
Следующее правило вставит любые три маленькие буквы в любые места слова:
i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z]
Итак, добавляем в файл /usr/share/john/john.conf
sudo gedit /usr/share/john/john.conf
следующие строки с нашими правилами:
[List.Rules:Add3SmallLet] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z]
Сохраним исходный пароль «long_password» в файл passwords.txt.
Написанный набор правил назван Add3SmallLet, наш исходный пароль помещён в файл passwords.txt, тогда команда для просмотра сгенерированных на основе правил паролей следующая:
john --rules=Add3SmallLet --wordlist=passwords.txt --stdout
Обратите внимание, что данные правила создадут, в том числе, и дубли паролей, если вы хотите создать словарь, то отфильтруйте дубли командой следующего вида:
john --rules=Add3SmallLet --wordlist=passwords.txt --stdout | sort | uniq
2. Добавление произвольных символов в произвольные места и замена символов в пароле на произвольные
Предположим, пользователь шифровал файлы одним и тем же паролем, допустим это «long_password», но в какой-то момент решил усложнить пароль и добавил в него несколько символов (от 1 до 3), а также решил заменить некоторые символы на цифры. Пользователь помнит, что он добавил какие-то строчные буквы, но какие именно и в какие места пароля он их добавил — не помнит. Также пользователь помнит, что заменил на цифры в пароле не более двух символов, возможно, что ни одного символа.
Задача: составить правила модификации пароля на основе указанных условий.
Воспользуемся уже рассмотренной функцией «iNX», которая вставляет символ X в позицию N.
Также воспользуемся функцией «oNX», которая перезаписывает символ в позиции N на X.
Для выполнения первой части условия (добавление 1-3 маленьких букв в произвольные места), воспользуемся правилами, составленными в предыдущей части.
i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z]
Правило, для замены одного символа в позициях от 0 до 13 на любую цифру следующее:
o[0-9A-D][0-9]
Для замены двух цифр, то есть для применения одного правила дважды, записываем полученное правило два раза:
o[0-9A-D][0-9] o[0-9A-D][0-9]
По условиям задачи, замена символов сопутствует добавлению символов или отсутствует вовсе.
Тогда набор правил для записи в файл /usr/share/john/john.conf следующий:
[List.Rules:AddAndReplace] i[0-9A-D][a-z] # добавление одной буквы i[0-9A-D][a-z] i[0-9A-D][a-z] # добавление двух букв i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] # добавление трёх букв i[0-9A-D][a-z] o[0-9A-D][0-9] # добавление одной буквы и замена одного символа на цифру i[0-9A-D][a-z] i[0-9A-D][a-z] o[0-9A-D][0-9] # добавление двух букв и замена одного символа на цифру i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] o[0-9A-D][0-9] # добавление трёх букв и замена одного символа на цифру i[0-9A-D][a-z] o[0-9A-D][0-9] o[0-9A-D][0-9] # добавление одной буквы и замена двух символов на цифры i[0-9A-D][a-z] i[0-9A-D][a-z] o[0-9A-D][0-9] o[0-9A-D][0-9] # добавление двух букв и замена двух символов на цифры i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] o[0-9A-D][0-9] o[0-9A-D][0-9] # добавление трёх букв и замена двух символов на цифры
Сохраним исходный пароль «long_password» в файл passwords.txt.
Написанный набор правил назван AddAndReplace, наш исходный пароль помещён в файл passwords.txt, тогда команда для просмотра сгенерированных на основе правил паролей следующая:
john --rules=AddAndReplace --wordlist=passwords.txt --stdout
Обратите внимание, что данные правила создадут, в том числе, и дубли паролей, если вы хотите создать словарь, то отфильтруйте дубли командой следующего вида:
john --rules=AddAndReplace --wordlist=passwords.txt --stdout | sort | uniq
3. Отбор паролей, соответствующих определённой политике
Известно, что в организации установлена следующая политика требований к паролям: в пароле должны быть как минимум одна большая буква; как минимум одна маленькая буква; как минимум одна цифра и как минимум один специальный символ. Длина пароля не может быть меньше 8 символов.
Задача — подготовить словарь для взлома хеша, в котором учтена политика требований к паролям и убраны не подходящие под критерии пароли.
Для этого нам понадобится два правила:
- /?C — означает отклонить слово, если оно не содержит символа в классе C.
- >N — означает отклонить слово, если оно не превышает N символов
Обратимся к таблице «Классы символов».
Этот набор правил отклоняет пароли в которых нет хотя бы одного из символов: строчная буква, прописная буква, цифра, знаки пунктуации:
/?l /?u /?d /?p
Поскольку в паролях могут быть другие специальные символы, то нужно составить ещё один набор правил:
/?l /?u /?d /?s
Этот второй набор правил отклоняет пароли в которых нет хотя бы одного из символов: строчная буква, прописная буква, цифра, специальный символ.
Внутри одной строки действует логическое «И», то есть будут отбросаны все пароли, в которых отсутствует хотя бы один класс символов.
Но между строками действует логическое «ИЛИ», то есть будут пропущены все пароли, которые соответствует критериям первой строки или критериям второй строки.
Также добавим правило, удаляющее слова, короче восьми символов, получаем:
/?l /?u /?d /?p >7 /?l /?u /?d /?s >7
В файл /usr/share/john/john.conf добавим следующие строки (набор правил назван StrongPass):
[List.Rules:StrongPass] /?l /?u /?d /?p >7 /?l /?u /?d /?s >7
Для проверки их работоспособности, скачаем словарь:
wget -U 'Chrome' https://kali.tools/files/passwords/leaked_passwords/rockyou.txt.bz2 7z e rockyou.txt.bz2
Проверим в нём количество паролей:
cat rockyou.txt | wc -l 14344391
То есть в файле 14.344.391 (четырнадцать миллионов) паролей.
А теперь проверим, сколько паролей будет отфильтровано:
john --rules=StrongPass --wordlist=rockyou.txt --stdout | wc -l
Вывод:
Using default input encoding: UTF-8 Press 'q' or Ctrl-C to abort, almost any other key for status 50785p 0:00:00:01 100,00% (2020-11-29 17:08) 35764p/s *7¡Vamos! 50785
Осталось всего 50785 кандидатов в пароли, подходящие под указанные условия! Это 50785÷14344391×100 = 0,35% от всего словаря!!! То есть если бы мы не использовали эту оптимизацию, 99,65% вычислений во время брут-форса были бы бессмысленными, поскольку проверяли бы заведомо неподходящие пароли.
4. На клавиатуре пользователя сломана кнопка
Известно, что от частой игры на компьютере у пользователя сломаны кнопки «a», «s», «d», «w». По этой причине пользователь при вводе паролей никогда не использует эти буквы.
Задачи: отфильтровать из словаря все кандидаты в пароли, которые содержат эти буквы. При этом исходить из того, что пользователь может вводить слова пропуская эти буквы.
Для выполнения указанного условия нам понадобится два правила:
- !X — означает отклонить слово, если оно содержит символ X
- @X — означает удалить все символы X из слова
Набор правил, который отклоняет все слова, если они содержат любой из указанных символов:
!a !s !d !w !A !S !D !W
Набор правил, который разрешает все слова, но удаляет из них указанные символы:
@a @s @d @w @A @S @D @W
Эти правила НЕ нужно использовать вместе, поскольку они создадут много дубликатов (подмножество кандидатов в пароли второго правила полностью включает в себя подмножество кандидатов в пароли первого правила).
Первое правило нужно применять если владелец неисправной клавиатуры не используется словами с указанными символами. Второе правило пригодится если владелец неисправной клавиатуры всё равно пользуется словами с указанными символами, но пропускает эти символы во время ввода.
5. Пользователь заменяет символы
Известно, что при вводе слов пользователь всегда заменяет символ I на 1, O на 0, а символ S на $.
Задача: изменить словарь таким образом, чтобы в нём была произведена замена указанных символов.
Для решения этой задачи нам понадобится одно правило:
- sXY — означает заменить все символы X в слове на Y
Набор правил, который делает замену трёх указанных символов:
sI1 sO0 sS$
В файл /usr/share/john/john.conf добавим следующие строки (набор правил назван Replace):
[List.Rules:Replace] sI1 sO0 sS$
Теперь мы можем убедиться, что во всех новых словах отсутствуют буквы I, O и S (заменены на 1, 0 и $):
john --rules=Replace --wordlist=rockyou.txt --stdout | grep -E 'I|O|S'
Вывод будет пустым, поскольку не будет найдено ни одного слова с I, O и S.
Важно помнить
Правила, которые создают новые слова (за счёт изменение регистра букв, добавления символов), обычно склонны генерировать дубликаты, особенно если используется несколько однотипных правил. Если вы создаёте словарь, то используйте для фильтрации дубликатов конструкцию «ВЫВОД john | sort | uniq > СЛОВАРЬ.txt».
Связанные статьи:
- Продвинутые техники создания словарей (98.1%)
- Как создать словари, соответствующие определённым политикам надёжности паролей (с помощью Атаки на основе правил) (78.8%)
- Виды атак Hashcat (75%)
- Генерация словарей по любым параметрам с pydictor (73.8%)
- Как установить драйверы для Hashcat в Windows (71.3%)
- Руководство по GPS метаданным в фотографиях (ч. 2): Как изменить GPS и другие метаданные в фотографии (RANDOM - 0.7%)