Продвинутые техники создания словарей
Оглавление
3. Генерация словарей на основе информации о человеке
4. Составление списков слов и списков имён пользователей на основе веб-сайта
5. Как создать словарь по маске с переменной длиной
6. Когда о пароле ничего не известно (все символы)
7. Создание словарей, в которых обязательно используется определённые символы или строки
8. Как создавать комбинированные словари
9. Как комбинировать более двух словарей
10. Как создать все возможные комбинации для короткого списка строк
11. Комбинирование по алгоритму PRINCE
12. Гибридная атака — объединение комбинаторной атаки и атаки по маске
13. Как создать комбинированный словарь, содержащий имя пользователя и пароль, разделённые символом
14. Как извлечь имена пользователей и пароли из комбинированного словаря в обычные словари
17. Как создать словарь со списком дат
18. Как разбить генерируемые словари на части
В этой статье собраны возможные ситуации генерации словарей, с которыми можно столкнуться на практике, но которые ещё не описаны в других статьях. Некоторые примеры взяты из вопросов в комментариях или на форуме, с некоторыми задачами я сталкивался сам.
Будут рассмотрены не только уже знакомые нам инструменты, но и парочка новых. Для некоторых задач мы будем использовать не только специализированные инструменты — некоторые действия проще сделать с помощью стандартных утилит Linux или собственных скриптов.
Поскольку здесь не будут описываться основы генерации словарей, то начнём с перечня источников, где вы можете прочитать эти самые основы. Рекомендуется прочитать их, если вы ещё не сделали этого.
Азы генерации словарей
О том, как создавать словари по маскам программами Crunch, Hashcat и maskprocessor: Программы для создания словарей
Ещё много примеров составления масок в статье: Инструкция по hashcat: запуск и использование программы для взлома паролей
Атака на основе правил
Атака на основе правил — изменяет уже существующий словарь по указанному набору правил. Если с помощью атаки на основе правил вы хотите изменить поведение маски, то вначале нужно создать словарь по маске, а затем работать с ним.
Самый простой способ — использовать программу с графическим интерфейсом Mentalist, инструкция: Генерация и модификация словарей по заданным правилам.

Атака на основе правил в John the Ripper намного мощнее чем в hashcat, для данной атаки из этих двух программ рекомендую выбирать именно John: Полное руководство по John the Ripper. Ч.5: атака на основе правил
Ещё примеры атаки по маске в John: Как создать словари, соответствующие определённым политикам надёжности паролей
Атака на основе правил в Hashcat: https://hackware.ru/?p=283#rule_based_attack
Генерация словарей на основе информации о человеке
Если пароль составлен на основе данных пользователя, например, комбинация имени, фамилии, даты рождения, именах детей, номера телефона, этих же данных ближайших родственников, то такой пароль можно считать слабым. Рассмотренные выше инструменты не очень подходят для составления подобных словарей, основанных на информации о пользователе — разве что, комбинаторная атака в Hashcat, но она за раз принимает только 2 словаря.
Именно эту проблему решает утилита CUPP.
Установка CUPP в Kali Linux
sudo apt install cupp
Установка CUPP в BlackArch
sudo pacman -S cupp
Запустите программу в интерактивном режиме и введите известные данные пользователя:
cupp -i

Пример сгенерированных паролей:
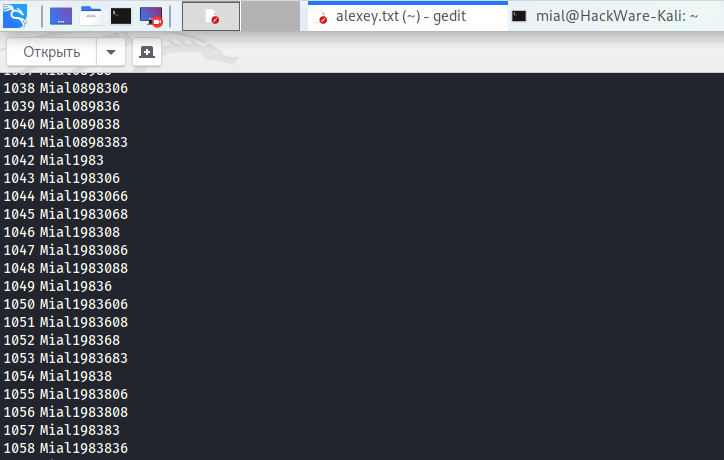
Если вам нужен перевод задаваемых вопросов, то вы найдёте его на странице карточки программы.
Составление списков слов и списков имён пользователей на основе содержимого веб-сайта
Познакомимся с ещё одним инструментом — CeWL. Эта программа обходит указанный сайт (можно указать глубину обхода) и все найденные на страницах сайта слова сортирует в порядке частоты их использования. Зачем нужен такой словарь? Автор предлагает использовать его для брут-форса. К тому же, программа умеет искать e-mail адреса, а также извлекать имена создателей офисных документов — поддерживаются файлы Word и PDF. Эти данные можно использовать для составления списка имён пользователей.
Ещё в комплекте с программой идёт утилита FAB, которая извлекает из уже скаченных документов Word и PDF имена авторов — их тоже можно использовать в качестве имён пользователей для брут-форса.
Установка CeWL в Kali Linux
Программа предустановлена в Kali Linux.
В минимальных версиях программа устанавливается следующим образом:
sudo apt install cewl
Установка в BlackArch
sudo pacman -S cewl gem install mime mime-types mini_exiftool nokogiri rubyzip spider
В карточке программы описаны дополнительные нюансы установки — рекомендуется ознакомиться.
Примеры запуска CeWL
Запуск сбора слов со страниц сайта https://site.ru, используя только страницы, ссылки на которые будут найдены на указанном адресе (-d 1), для составления словаря, который будет сохранён в файл dic.txt (-w dic.txt):
cewl https://site.ru -d 1 -w dic.txt
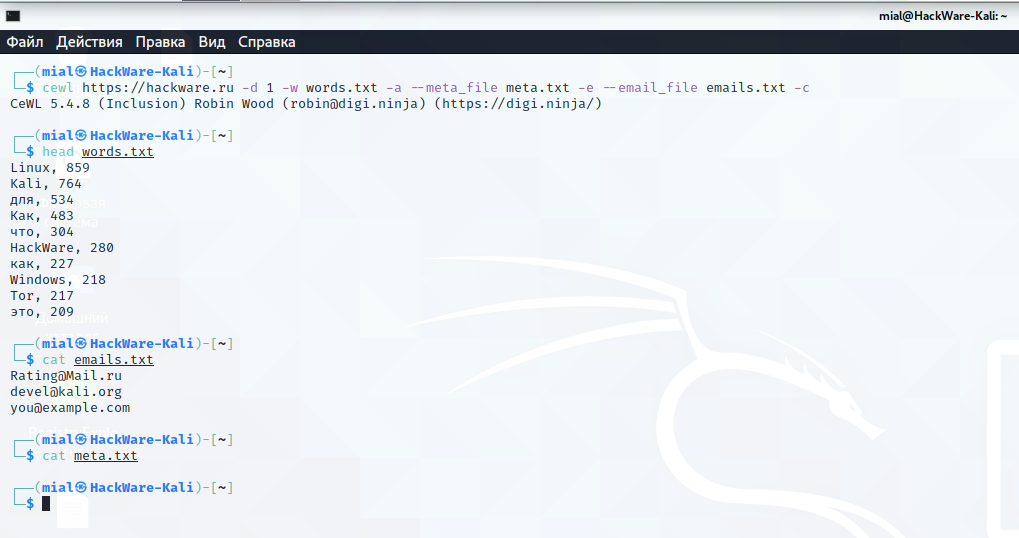
Запуск сбора слов со страниц сайта https://site.ru, используя страницы, ссылки на которые будут найдены на указанном адресе, а также на скаченных страницах (-d 2), для составления словаря, который будет сохранён в указанный файл (-w dic.txt), при этом для каждого слова будет показана частота, с которой он встречается (-c), также будет составлен список найденных email адресов (-e), которые будут сохраняться в указанный файл (—email_file emails.txt) и будет создан список на основе информации найденной в метатегах документов (-a), этот список будет сохранён в указанный файл (—meta_file meta.txt):
cewl https://site.ru -d 2 -w words.txt -a --meta_file meta.txt -e --email_file emails.txt -c
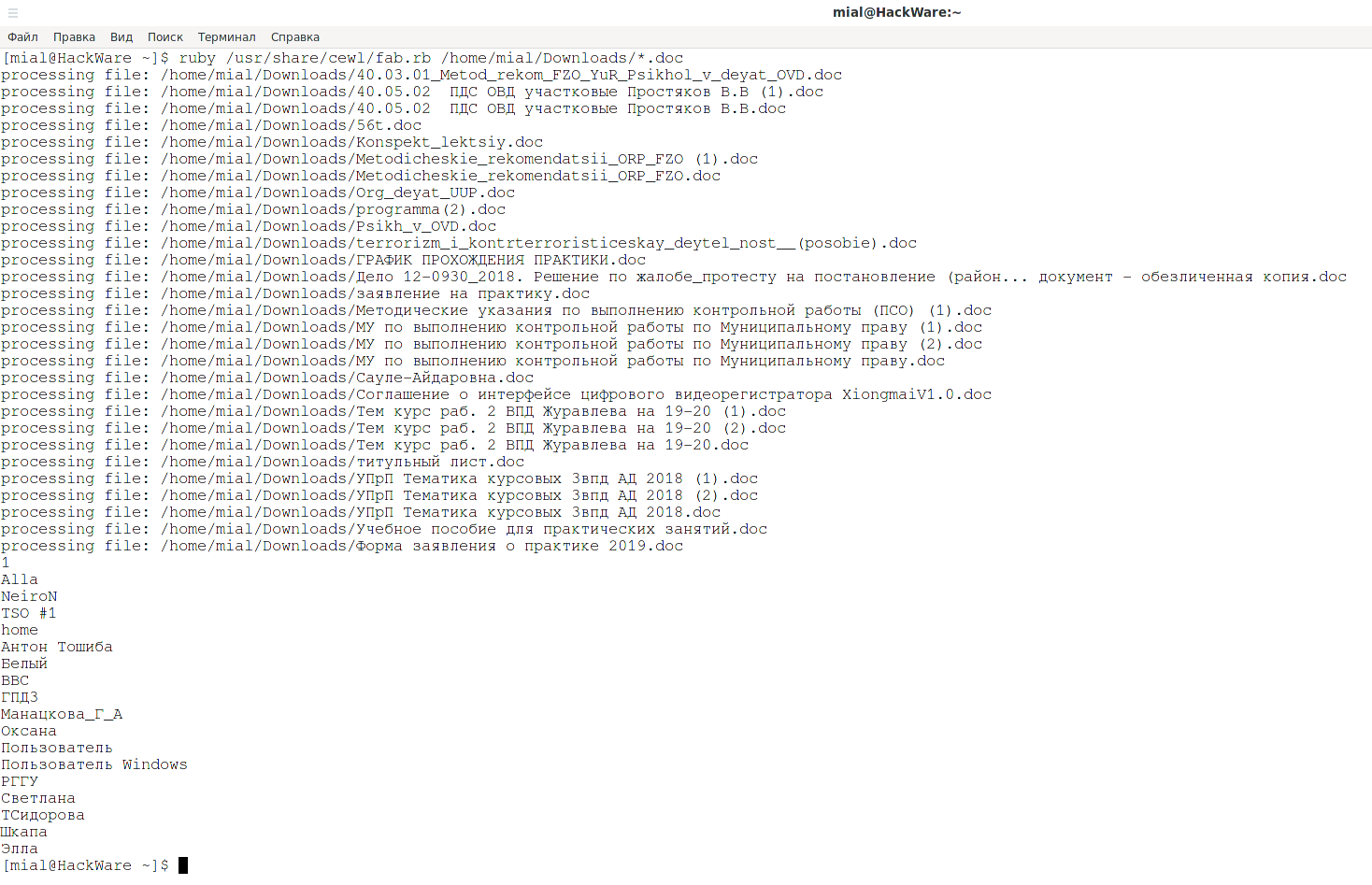
Запуск FAB, при котором будут проверены все документы *.doc в директории /home/mial/Downloads/, из метаинформации этих документов будет извлечено поле, содержащее имя автора документа, данные будут выведены на экран:
ruby /usr/share/cewl/fab.rb /home/mial/Downloads/*.doc
Как создать словарь по маске с переменной длиной
Рассмотрим генерацию списков слов различной длины на примере Hashcat и maskprocessor.
Удлиняющиеся пароли в Hashcat
Для того, чтобы генерировались пароли различной длины, имеются следующие опции:
-i, --increment | | Включить режим приращения маски |
--increment-min | Числ | Начать прирост маски на X | --increment-min=4
--increment-max | Числ | Остановить прирост маски на X | --increment-max=8
Опция -i является необязательной. Если она используется, то это означает, что длина кандидатов в пароли не должна быть фиксированной, она должна увеличиваться по количеству символов.
Опция —increment-min также является необязательной. Она определяет минимальную длину кандидатов в пароли. Если используется опция -i, то значением —increment-min по умолчанию является 1.
И опция —increment-max является необязательной. Она определяет максимальную длину кандидатов в пароли. Если указана опция -i, но пропущена опция —increment-max, то её значением по умолчанию является длина маски.
Правила использования опций приращения маски:
- перед использованием —increment-min и —increment-max необходимо указать опцию -i
- значение опции —increment-min может быть меньшим или равным значению опции —increment-max, но не может превышать его
- длина маски может быть большей по числу символов или равной числу символов, установленной опцией —increment-max, НО длина маски не может быть меньше длины символов, установленной —increment-max.
Итак, команда запуска для генерации паролей, которые имеют длину от шести до десяти символов:
hashcat -a 3 -i —increment-min=6 —increment-max=10 —stdout ?l?l?l?l?l?l?l?l?l?l
Удлиняющиеся пароли в maskprocessor
В maskprocessor имеется следующая опция приращения:
-i, --increment=ЧИСЛО:ЧИСЛО Включить режим приращения.
Первое ЧИСЛО=начало, второе ЧИСЛО=конец
Пример: -i 4:8 интересующая длинна 4-8 (включая)
Следующая команда составит словарь из чисел от 1 до 9999:
maskprocessor -i 1:4 ?d?d?d?d
Когда о пароле ничего не известно (все символы)
Про нюансы я уже писал, здесь только примеры команд.
Если нужно запустить полный перебор, когда в пароле могут быть большие и маленькие латинские буквы, а также цифры и длина пароля от 1 до 12, то нужно использовать следующие опции и маску:
-i --increment-min=1 --increment-max=12 -1 ?l?u?d ?1?1?1?1?1?1?1?1?1?1?1?1
Чтобы вывести все кандидаты в пароли или сохранить их в словарь:
hashcat --stdout -a 3 -i --increment-min=1 --increment-max=12 -1 ?l?u?d ?1?1?1?1?1?1?1?1?1?1?1?1
Если нужно запустить полный перебор, когда в пароле могут быть большие и маленькие латинские буквы, цифры, а также символы !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ и длина пароля от 1 до 12, то нужно использовать следующие опции и маску:
-i --increment-min=1 --increment-max=12 ?a?a?a?a?a?a?a?a?a?a?a?a
Чтобы вывести все кандидаты в пароли или сохранить их в словарь:
hashcat --stdout -a 3 -i --increment-min=1 --increment-max=12 ?a?a?a?a?a?a?a?a?a?a?a?a
Создание словарей, в которых обязательно используется определённые символы или строки
В комментариях к статьям о генерации паролей по маскам иногда спрашивают, а как создать словарь, содержащий определённые символы или слова, причём они могут быть в любом месте. На самом деле, именно маски для этого подходят плохо. Задачу можно решить с помощью Атаки на основе правил, особенно если речь идёт об отдельных символах или группах символов — выше уже даны ссылки на решение подобных случаев. Но если речь идёт о строках, то Атака на основе правил становится или слишком сложной и запутанной из-за необходимости создавать большое количество правил, или даже просто невозможной.
Рассмотрим несколько примеров.
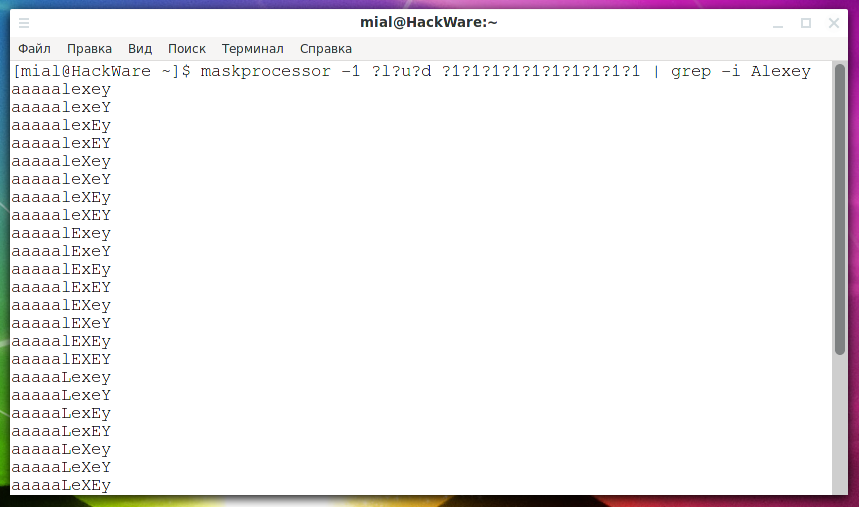
Предположим, известно, что в пароле, состоящим из любых символов (большие и маленькие буквы, а также цифры), обязательно присутствует слово «Alexey», которое может быть в любом месте пароля и в любом регистре. Для решения этой задачи вместо того, чтобы создавать безумное количество правил, можно создать словарь со всеми вариантами и просто отфильтровать слова, в которых есть искомая строка, например:
maskprocessor -1 ?l?u?d ?1?1?1?1?1?1?1?1?1?1 | grep -i Alexey
Смотрите также: Регулярные выражения и команда grep
На мой взгляд, это оптимальное решение. Оно также подходит, если вы не хотите создавать словарь, а хотите использовать атаку по маске — многие программы для брут-форса способны принимать кандидаты в пароли из стандартного ввода.
Ещё один вариант — искомое слово может быть в любом регистре, но точно расположено в начале пароля:
maskprocessor -1 ?l?u?d ?1?1?1?1?1?1?1?1?1?1 | grep -i -E '^Alexey'
Кстати, последний пример не особенно удачный — поскольку нам известно, что вначале возможны только 2 символа — „A“ или „a“, то лучше использовать пользовательский набор символов, включающих эти два символа. Аналогично и для других — хотя бы четырёх известных символов (по количеству возможных пользовательских наборов).
Как создать словарь, обязательно содержащий символы «e», «g», «D» и «t»? Для этого используйте команду вида:
maskprocessor -1 ?l?u?d ?1?1?1?1?1?1?1?1?1?1 | grep e | grep g | grep D | grep t
В ней вы можете добавлять цепочку из grep и отфильтровывать пароли с любым количеством необходимых символов.
Как создать словарь, в котором пароли в любом месте и в любом регистре содержат слово «Alexey» или слово «MiAl»? Используйте команду вида:
maskprocessor -1 ?l?u?d ?1?1?1?1?1?1?1?1?1?1 | grep -i -E '(Alexey)|(MiAl)'
Количество искомых строк может быть любым:
maskprocessor -1 ?l?u?d ?1?1?1?1?1?1?1?1?1?1 | grep -i -E '(Alexey)|(MiAl)|(OneMoreString)|(AnotherString)|(EvenMore)'
Пример команды, создающий словарь, в котором кандидаты в пароли состоят только из цифр, но в пароле обязательно должна быть последовательность «12345» расположенная в любом месте:
maskprocessor ?d?d?d?d?d?d?d?d?d?d | grep 12345
Думаю, идея понятно — вместо того, чтобы пытаться создать невозможную маску, создаём всё возможное и отфильтровываем то, что нам нужно.
Как создавать комбинированные словари
Комбинированными словарями обычно называют словари, включающие одновременно имя пользователя и пароль, разделённые определённым символом (обычно двоеточие или символ табуляции). Но в данном случае я имею в виду словари, которые составлены из слов разных словарей, путём объединения. Но и к «нормальным» комбинированным словарям мы ещё вернёмся.
Это называется комбинаторной атакой, её подробное описание: https://hackware.ru/?p=283#combinator_attack
Суть в том, что к каждому слову из первого словаря, добавляется каждое слово из второго словаря.
Словарь 1 (dict1.txt)
yellow green black blue
Словарь 2 (dict2.txt)
car bike
Запуск комбинаторной атаки (-a 1):
hashcat -a 1 --stdout dict1.txt dict2.txt
Вывод:
yellowcar yellowbike greencar greenbike blackcar blackbike bluecar bluebik
Мне почему-то казалось, что слова должны объединятся ещё и в обратном порядке (то есть первым идёт слово из второго словаря), но как вы можете убедиться, это не происходит. Поэтому для получения описанного эффекта, нужно запустить атаку ещё раз, поменяв словари местами:
hashcat -a 1 --stdout dict2.txt dict1.txt
Как комбинировать более двух словарей
Далее показан пример комбинации трёх словарей — суть в том, что каждое новое полученное слово состоит по одному слову из каждого из трёх словарей:
# создание промежуточных словарей, получаемых комбинацией каждой пары словарей hashcat -a 1 --stdout dict1.txt dict2.txt > tmp12.txt hashcat -a 1 --stdout dict2.txt dict1.txt > tmp21.txt hashcat -a 1 --stdout dict1.txt dict3.txt > tmp13.txt hashcat -a 1 --stdout dict2.txt dict3.txt > tmp23.txt hashcat -a 1 --stdout dict3.txt dict2.txt > tmp32.txt hashcat -a 1 --stdout dict3.txt dict1.txt > tmp31.txt # создание промежуточных словарей, получаемых комбинацией каждой пары «исходный словарь-комбинированный словарь». В результате будут созданы словари, являющиеся комбинацией всех трёх hashcat -a 1 --stdout dict12.txt dict3.txt > tmp123.txt hashcat -a 1 --stdout dict21.txt dict3.txt > tmp213.txt hashcat -a 1 --stdout dict13.txt dict2.txt > tmp132.txt hashcat -a 1 --stdout dict31.txt dict2.txt > tmp312.txt hashcat -a 1 --stdout dict23.txt dict1.txt > tmp231.txt hashcat -a 1 --stdout dict32.txt dict1.txt > tmp321.txt # собираем все полученные слова в один словарь: cat tmp123.txt tmp213.txt tmp132.txt tmp312.txt tmp231.txt tmp321.txt | sort | uniq > full.txt
Как комбинировать подобным образом 4 и более словарей? Мне трудно представить, что это может пригодиться в реальной ситуации, но для этого скорее всего придётся писать свой скрипт для автоматизации показанного выше алгоритма. Если вы знаете программы, которые умеют это делать, то пишите в комментариях.
И… в этом месте я вспомнил о программе combinator3. Она поставляется в пакете hashcat-utils. Эта команда служит для комбинации трёх словарей (для комбинации двух словарей используйте combinator).
Использование:
combinator3 file1 file2 file3
Эта программа умеет комбинировать по 3 указанных словаря, но опять же — если словарь идёт третьим, то слова из него всегда будут в конце.
Чтобы получить все возможные комбинации из трёх слов в любом порядке, то нужно использовать следующие команды:
combinator3 file1 file2 file3 > full.txt combinator3 file1 file3 file2 >> full.txt combinator3 file2 file1 file3 >> full.txt combinator3 file2 file3 file1 >> full.txt combinator3 file3 file1 file2 >> full.txt combinator3 file3 file2 file1 >> full.txt
Как создать все возможные комбинации для короткого списка строк
Утилита combipow создаёт все “уникальные комбинации” из короткого списка ввода. Эта программа также включена в hashcat-utils.
Использование:
combipow СЛОВАРЬ
Пример содержимого словаря с именем wordlist:
a b c XYZ 123
Запуск combipow с этим словарём:
combipow wordlist
Даст следующие результаты:
a b ab c ac bc abc XYZ aXYZ bXYZ abXYZ cXYZ acXYZ bcXYZ abcXYZ 123 a123 b123 ab123 c123 ac123 bc123 abc123 XYZ123 aXYZ123 bXYZ123 abXYZ123 cXYZ123 acXYZ123 bcXYZ123 abcXYZ123
Комбинирование по алгоритму PRINCE
Программа princeprocessor реализует алгоритм PRINCE. Подробнее об этом алгоритме вы можете узнать на странице карточки программы. Там же описана суть работы программы и её опции.
Примеры использования princeprocessor.
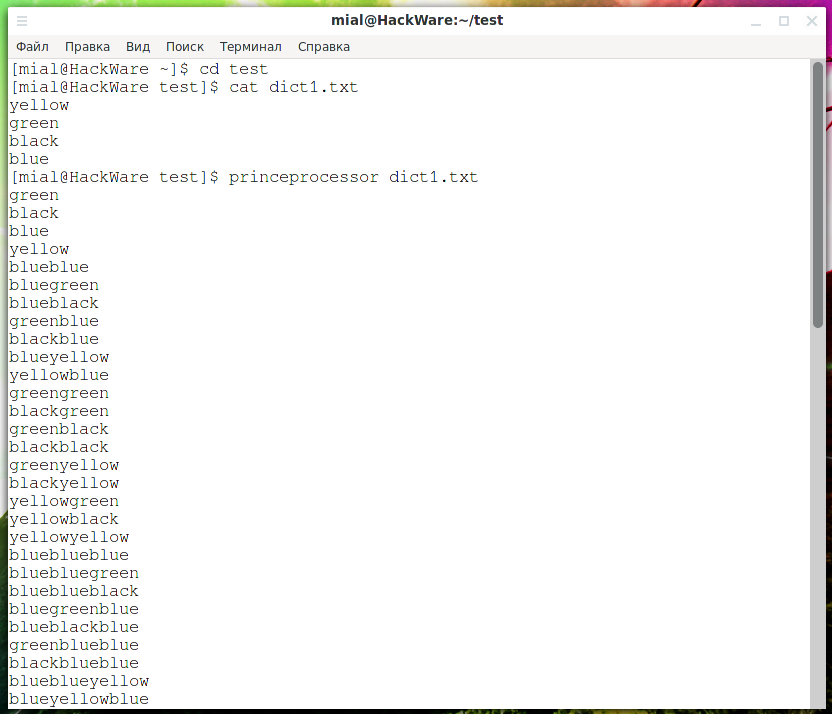
Чтобы создать все возможные цепи из содержимого файла dict1.txt:
princeprocessor dict1.txt
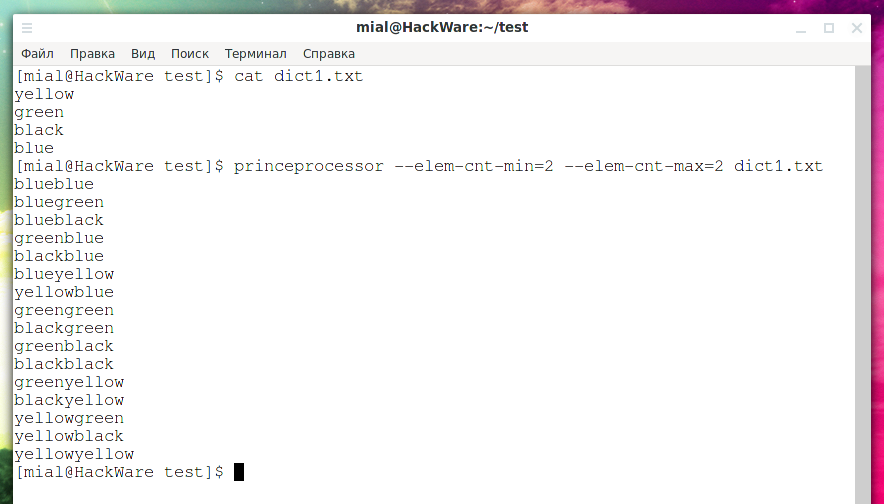
Используя слова из указанного словаря (dict1.txt) составить цепи минимальной длиной 2 элемента (—elem-cnt-min=2) и максимальной длиной 2 элемента (—elem-cnt-max=2), то есть в каждой цепи будет только по 2 слова:
princeprocessor --elem-cnt-min=2 --elem-cnt-max=2 dict1.txt
Гибридная атака — объединение комбинаторной атаки и атаки по маске
Эта атака совмещает атаку по словарю и атаку по маске — она принимает на входе словарь и маску и выдаёт гибридный пароль.
Справка по гибридной атаке: https://hackware.ru/?p=283#hybrid_attack
Если ваш example.dict содержит:
password hello
Опции:
... -a 6 example.dict ?d?d?d?d
генерируют следующие кандидаты в пароли:
password0000 password0001 password0002 . . . password9999 hello0000 hello0001 hello0002 . . . hello9999
Это работает и в противоположную сторону!
Опции:
... -a 7 ?d?d?d?d example.dict
генерируют следующие кандидаты в пароли:
0000password 0001password 0002password . . . 9999password 0000hello 0001hello 0002hello . . . 9999hello
Все возможности гибридной атаки можно реализовать с помощью Атаки на основе правил — поэтому если она вам нравится больше, то используйте её.
Как создать комбинированный словарь, содержащий имя пользователя и пароль, разделённые символом
Теперь возвращаемся к комбинированным словарям, содержащим одновременно имя пользователя и пароль.
В качестве примера посмотрите на фрагмент словаря (файл auth_basic.txt) программы Router Scan by Stas'M — в нём учётные данные разделены символом табуляции:
admin <empty> admin admin admin 1234 admin password Admin Admin <empty> admin root <empty> root admin root root root toor root public
А это пример комбинированного словаря, в котором имя пользователя и пароль разделены двоеточием:
admin:admin admin:1234 admin:password root:root root:toor
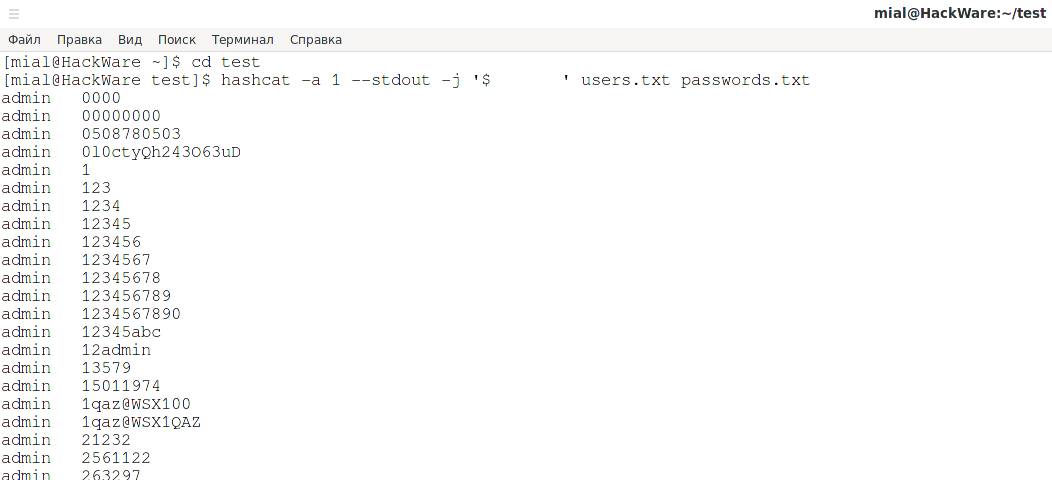
Чтобы создать комбинированный словарь, используйте команду вида:
hashcat -a 1 --stdout -j '$РАЗДЕЛИТЕЛЬ' users.txt passwords.txt
В этой команде:
- users.txt и passwords.txt — словари, из которых будут взяты имена пользователей и пароли и будут составлены все возможные комбинации.
- РАЗДЕЛИТЕЛЬ — символ, которым будут разделены логин и пароль
Например, в следующей команде разделителем является двоеточие:
hashcat -a 1 --stdout -j '$:' users.txt passwords.txt

Кстати, если в качестве разделителя нужно вставить символ табуляции, то нажмите Ctrl-v + Tab:
Кстати, если вы попытаетесь разобраться в приведённой выше команде hashcat, то выясните, что одновременно используется Комбинаторная атака и добавлено правило из Атаки на основе правил.
Рассмотрим частный случай: как создать файл парный словарь логинов и паролем такого типа: логин всегда постоянный, затем табуляция и пароль.
superadmin Zte531zTE@fn18131 superadmin Zte531zTE@fn18132 И т.д.
Конечно, в качестве первого словаря можно создать файл с одним текстовым полем — логином. Но есть и другой вариант с помощью мощнейшей команды sed:
sed -e 's/^/superadmin\t/' pass.txt > login_pass.txt
В этой команде:
- superadmin — строка, которую нужно вставить перед каждым паролем
- \t — символ табуляции, который будет разделять логин и пароль
- pass.txt — файл, откуда считывать пароли
- login_pass.txt — новый файл, куда будут сохранены пароли
Если не хотите создавать новый файл, а хотите изменить имеющийся, то уберите перенаправление и добавьте опцию -i:
sed -i -e 's/^/superadmin\t/' pass.txt
Как извлечь имена пользователей и пароли из комбинированного словаря в обычные словари
Если из комбинированного словаря нам нужно извлечь только имена пользователей и/или только пароли. Для этого мы воспользуемся (тоже мощнейшей) программой awk.
Смотрите также: Уроки по Awk
Для извлечения имён пользователей:
awk -F 'РАЗДЕЛИТЕЛЬ' '{print $1}' СЛОВАРЬ.txt | sort | uniq
Для извлечения паролей:
awk -F 'РАЗДЕЛИТЕЛЬ' '{print $2}' СЛОВАРЬ.txt | sort | uniq
В этих командах:
- РАЗДЕЛИТЕЛЬ — это символ, который разделяет логины и пароли. Если вам нужно указать там символ табуляции, то запишите «\t».
- СЛОВАРЬ.txt — комбинированный словарь из которого мы извлекаем списки слов
В принципе, команды только различаются в $1 (первое поле до разделителя) и $2 (второе поле после разделителя).
Как при помощи Hashcat можно сгенерировать словарь хешей MD5 всех шестизначных чисел от 000000 до 999999
Hashcat может делать радужные таблицы, но только для Wi-Fi.
Зато с помощью PHP эту задачу можно решить несколько строк:
<?php
for ($i = 0; $i <= 999999; $i++) {
echo md5 (str_pad( "$i", 6, "0", STR_PAD_LEFT )) . PHP_EOL;
}
Время выполнение — 1-4 секунды. За это время будут сгенерированы все md5 хеши для строк 000000…999999.
Сохраните приведённый выше код в файл md5-rb-gen.php, запускать так:
php md5-rb-gen.php
Чтобы сохранить полученные хеши в файл:
php md5-rb-gen.php > md5.txt
Смотрите, кстати «Как запустить PHP скрипт без веб-сервера».
Интересное наблюдение о скорости достижения задачи.
Следующие две команды делают ровно то же самое:
maskprocessor ?d?d?d?d?d?d > 6.txt
cat 6.txt | while read -r line ; do echo -n $line | md5sum | awk '{print $1}'; done > md5.txt
Но на среднем компьютере выполнение команд займёт до часа. PHP оказался быстрее, чем нативные Linux команды…
Удвоение слов
Как создать словарь 12 символьных слов, состоящих только из десятичных цифр (?d) формата abcdefabcdef, т.е шестизначное число написано два раза?
Можно использовать Атаку на основе правил, а можно написать небольшой скрипт Bash (все слова в из файла user.txt пишутся по 2 раза):
cat user.txt | while read -r line; do echo $line$line; done
Применительно к нашему заданию — удвоение шестизначных чисел, можно использовать следующую команду, которая сгенерирует числа из шести цифр и дважды запишет каждое число:
maskprocessor ?d?d?d?d?d?d | while read -r line; do echo $line$line; done
Как создать словарь со списком дат
Как создать список дат по шаблону ДД-ММ-ГГГГ, то есть соответствущий маске ?d?d-?d?d-?d?d?d?d но чтобы перебор был не в диапазоне 00-99, а 01-31, 01-12 и 1900-2021 соответственно?
Такие словари умеет создавать программа pydictor.
Но ещё проще словарь сделать следующим образом (он будет сохранён в файл dates.txt):
echo {01..31}.{01..12}.{1900..2021} | tr " " "\n" > dates.txt
Если хотите обойтись без создания словаря, то передавайте вывод предыдущие команды на стандартный ввод hashcat:
echo {01..31}.{01..12}.{1900..2021} | tr " " "\n" | hashcat ……..
Как разбить генерируемые словари на части
Можно ли как-то в maskprocessor разделить выходящий генерируемый словарь на несколько частей? Например, частями по 1Гб.
Да, вы можете разделить вывод maskprocessor, а также готовые словари на части. В Linux для этого удобно воспользоваться утилитой split, например:
maskprocessor ?l?l?l?l?l?l?l?l?l?l | split -C 10G
Подробности смотрите в статье «Как разбить большой файл (текстовый или бинарный) на файлы меньшего размера».
Заключение
Если я что-то пропустил или есть утилиты, которые делают показанные вещи проще или делают возможным то, о чём я написал что это невозможно, то пишите в комментариях — будет интересно узнать об этом и дополнить статью.
Также можете задавать ваши вопросы, связанные с генерацией словарей, учитывающих определённые условия.
Связанные статьи:
- Генерация словарей по любым параметрам с pydictor (75.5%)
- Генерация и модификация словарей по заданным правилам (64.9%)
- Виды атак Hashcat (62.9%)
- Как создать словари, соответствующие определённым политикам надёжности паролей (с помощью Атаки на основе правил) (60.3%)
- Как использовать предварительно вычисленные таблицы для взлома паролей Wi-Fi в Hashcat и John the Ripper (60%)
- Аудит безопасности IP камер (RANDOM - 0.3%)
Потрясающая статья, спасибо огромнейшее учитель!!!
если не затруднит, обьясните пожалуйста эту команду echo {01..31}.{01..12}.{1900..2021} | tr » » «\n» > dates.txt а именно вот это не понятно tr » » «\n»
Чтобы понять «echo {01..31}.{01..12}.{1900..2021}» посмотрите раздел «Раскрытие (Expansion)».
Если коротко, то выводятся все строки в диапазоне для цифр/букв в фигурных скобках. Если фигурных скобок несколько, то выводятся их общие сочетания.
Чтобы понять, для чего нужно «tr " " "\n"», запустите команду без этой части:
echo {01..31}.{01..12}.{1900..2021}Все сочетания будут выведены, но они будут записаны в одну строку и разделены пробелом. Команда tr, в данном случае, меняет все символы пробела на символ новой строки, который обозначается как «\n».
Вот так намного проще
printf "%s\n" {01..31}.{1..12}.{1900..2021}Приветствую! Действительно, более изящное решение.
Понял, благодарю!
Доброго дня.
Подскажите, так и не могу сообразить, как сгенерировать словарь, при известной части пароля и длины. Скажем имеется пароль длинной 11 символов. В середине есть фраза из 8 символов, которая "обрамлена" какими-то цифрами и символами.
Очень буду благодарен, за помощь.