Как генерировать кандидаты в пароли, соответствующих политикам надёжности паролей (фильтрация слов с помощью grep)
Недостатки Атаки на основе правил
Показанный в статье «Как создать словари, соответствующие определённым политикам надёжности паролей» способ фильтрации только подходящих кандидатов с помощью Атаки на основе правил не всегда удобен. Точнее говоря, он удобен при работе с существующими словарями. Если с помощью этого способа генерировать новые словари, то возникает проблема с сохранением промежуточного словаря, который может быть очень большим.
Можно использовать другой подход, со следующим алгоритмом:
- Программа maskprocessor генерирует все возможные кандидаты в пароли
- С помощью команды grep отфильтровываются только подходящие под нужные критерии
- Отфильтрованные пароли передаются на стандартных ввод hashcat для взлома хеша или сохраняются в файл — в зависимости от того, что вам нужно
Минусы данного подхода:
- Команда grep может стать узким местом, если пароли будут фильтроваться медленнее, чем hashcat вычисляет хеш
- Если вы передаёте пароли на стандартный ввод hashcat, то в случае необходимости остановить атаку, а затем запустить вновь, атака опять начнётся с первого кандидата в пароли
- Если вы генерируете словарь, его размер по-прежнему может быть весьма большим
Регулярные выражения для фильтрации паролей
Настоятельно рекомендуется изучить статью «Регулярные выражения и команда grep».
Примеры регулярных выражений, которые нам пригодятся:
Обязательно есть одна большая буква:
'.*[A-Z]{1,}.*'
Обязательно есть две больших буквы:
'.*[A-Z]{1,}.*[A-Z]{1,}.*'
Обязательно есть три больших буквы:
'.*[A-Z]{1,}.*[A-Z]{1,}.*[A-Z]{1,}.*'
Обязательно есть одна маленькая буква:
'.*[a-z]{1,}.*'
Обязательно есть две маленьких буквы:
'.*[a-z]{1,}.*[a-z]{1,}.*'
Обязательно есть три маленьких буквы:
'.*[a-z]{1,}.*[a-z]{1,}.*[a-z]{1,}.*'
Обязательно есть одна цифра:
'.*[0-9]{1,}.*'
Обязательно есть две цифры:
'.*[0-9]{1,}.*[0-9]{1,}.*'
Обязательно есть три цифры:
'.*[0-9]{1,}.*[0-9]{1,}.*[0-9]{1,}.*'
Сохранение в файл
Следующая команда сгенерирует пароли, в которых есть хотя бы две больших буквы, одна маленькая буква и одна цифра:
maskprocessor -1 ?l?u?d ?1?1?1?1?1?1?1?1 | grep -E '.*[A-Z]{1,}.*[A-Z]{1,}.*' | grep -E '.*[a-z]{1,}.*' | grep -E '.*[0-9]{1,}.*'
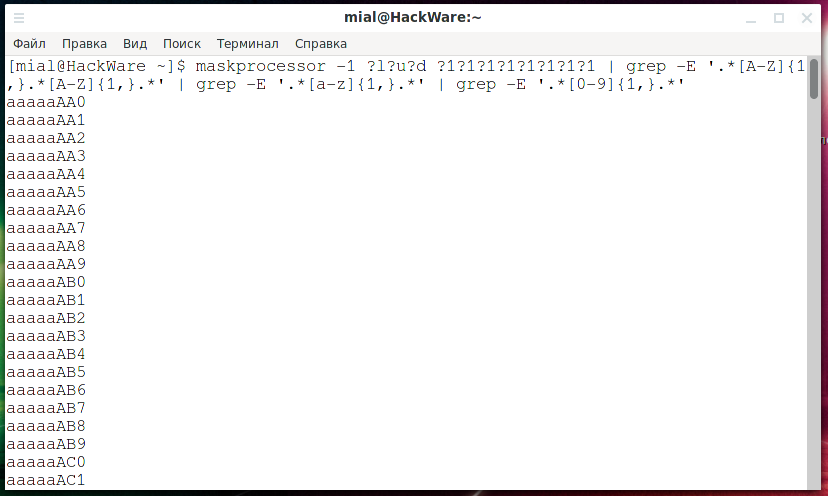
Сгенерированные пароли можно сохранить в файл:
maskprocessor -1 ?l?u?d ?1?1?1?1?1?1?1?1 | grep -E '.*[A-Z]{1,}.*[A-Z]{1,}.*' | grep -E '.*[a-z]{1,}.*' | grep -E '.*[0-9]{1,}.*' > llud.dic
Передача сгенерированных паролей в стандартный ввод hashcat
Создаваемые и отфильтрованные кандидаты в пароли можно использовать напрямую с hashcat, передавая их на стандартный ввод.
Сгенерируем хеш для взлома:
echo -n aaazaAD1 | md5sum f203600f24db0b34d3d568208c35cd4e
В hashcat в качестве типа атаки, нужно выбирать Атаку по словарю (-a 0).
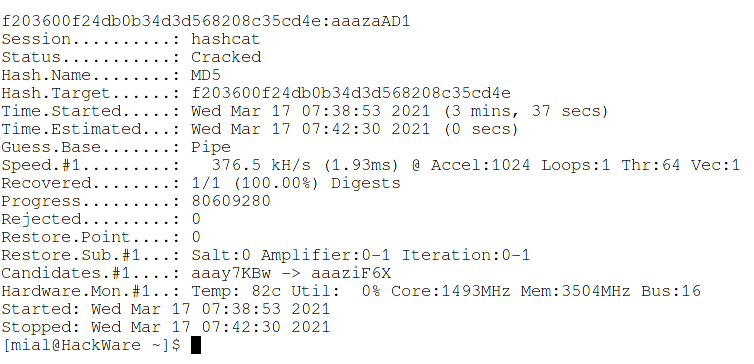
Пример команды, которая взламывает тестовый хеш:
maskprocessor -1 ?l?u?d ?1?1?1?1?1?1?1?1 | grep -E '.*[A-Z]{1,}.*[A-Z]{1,}.*' | grep -E '.*[a-z]{1,}.*' | grep -E '.*[0-9]{1,}.*' | hashcat -m 0 -a 0 f203600f24db0b34d3d568208c35cd4e
В этой команде первая половина такая же, как в командах выше, то есть maskprocessor генерирует все возможные варианты, а последовательность команд grep отфильтровывает только подходящие слова. Полученные слова передаются на стандартный ввод hashcat.
Фильтрация уже существующих словарей
Этот же способ можно использовать для отбора из уже существующих словарей только тех кандидатов в пароли, которые соответствуют заданным критериям.
Возьмём словарь для теста:
cat /usr/share/wordlists/rockyou.txt.gz | gunzip > ~/rockyou.txt
Посчитаем количество слов в нём:
cat ~/rockyou.txt | wc -l 14344392
Очистим словарь от нечитаемых символов:
iconv -f utf-8 -t utf-8 -c ~/rockyou.txt > ~/rockyou_clean.txt
Подробности о проблеме, которую решает предыдущая команда, вы найдёте в статье «Как из текстового файла найти и удалить символы, отличные от UTF-8».
Посчитаем строки в нём:
cat ~/rockyou_clean.txt | wc -l 14344392
Теперь вместо команды maskprocessor для генерации слов по маске, используем команду cat для чтения файла и с помощью | (труба, конвейер) передадим его для фильтрации командам grep (используются те же условия — минимум две большие буквы, минимум одна маленькая и минимум одна цифра):
cat ~/rockyou_clean.txt | grep -E '.*[A-Z]{1,}.*[A-Z]{1,}.*' | grep -E '.*[a-z]{1,}.*' | grep -E '.*[0-9]{1,}.*' > ~/rockyou_llud.dic
Посчитаем количество оставшихся кандидатов в пароли в новом словаре:
cat ~/rockyou_llud.dic | wc -l 124050
Посчитаем, сколько это от общего числа:
124050÷14344392×100 = 0,86%
Получилось, что осталось меньше 1 процента слов.
Зачем тогда вообще нужна Атака на основе правил?
Как пишут авторы Hashcat, Атака на основе правил работает быстрее, чем команда grep. В моих тестах с одной видеокартой на ноутбуке, узким местом всё равно остаётся видеокарта, то есть скорости работы grep хватает, чтобы Hashcat не ждала генерации/фильтрации следующего кандидата в пароли.
Атака на основе правил позволяет не только фильтровать слова, но и модифицировать их, то есть у этой атаки много других возможностей.
Связанные статьи:
- Как создать словари, соответствующие определённым политикам надёжности паролей (с помощью Атаки на основе правил) (68.9%)
- Продвинутые техники создания словарей (68.9%)
- Как ускорить создание словарей с паролями (67.2%)
- Программы для создания словарей (64.1%)
- Виды атак Hashcat (62.5%)
- Полное руководство по John the Ripper. Ч.2: утилиты для извлечения хешей (RANDOM - 50%)