Анализ и разбивка составных файлов (прошивки, образы дисков)
Начать рекомендуется с первой части под названием «Как узнать тип файла без расширения (в Windows и Linux)».
Файлы контейнеры (матрёшки)
Многие файлы представляют собой объединения нескольких файлов. К примеру, файлы офисных документов .docx и .odt. Вы можете заменить расширение таких файлов на .zip, открыть любым архиватором и убедиться, что на самом деле это просто контейнеры, содержащие в себе множество файлов. Например, если вы вставили картинку в документ Word, то чтобы извлечь эту картинку, необязательно открывать файл в офисном редакторе — можно поменять расширение, распаковать архив и из него забрать свою картинку обратно. Практически все прошивки (для роутеров, IP камер, телефонов) это контейнеры. ISO образы и образы файловых систем тоже контейнеры. Архивы, как можно догадаться, также содержат в себе сразу несколько файлов.
2 способа объединения файлов
С практической точки зрения, с точки зрения поиска файлов можно выделить 2 способа объединить файлы:
1. Файлы хранятся без изменения, в своём начальном виде.
Пример такого объединения файлов это файловые системы без шифрования и без сжатия. Например, EXT4, NTFS — в них файлы помещены в своём первоначальном виде. Соответственно, образы таких файловых систем также относятся к этой группе. Сюда же можно отнести некоторые прошивки, например, для роутеров и IP камер.
Понятно, что в таких больших файлах (образах) можно найти хранимые файлы. Более того, хранимые файлы можно извлечь и сохранить в виде самостоятельного файла, который будет идентичен исходному.
2. Файлы обрабатываются по определённому алгоритму.
Примеры такого способа объединения файлов это файловые системы с шифрованием или сжатием (например, Squashfs), архивы со сжатием.
Для поиска отдельных файлов по их сигнатурам необходимо выполнить обратное действие, то есть если файл был сжат, необходимо его разархивировать. Если это файловая система со сжатием, то необходимо её смонтировать.
С практической точки зрения это означает, что бесполезно искать файлы по сигнатурам в архивах, пока эти архивы не распакованы (НО: некоторые программы по анализу сырых данных поддерживают работу с архивами!). Бесполезно искать файлы по сигнатурам в файловой системе Squashfs до её монтирования. При этом можно применять поиск по сигнатурам в EXT4 и NTFS и их монтирование не требуется!
Монтирование, например, образа NTFS даст нам следующее: мы сможем получать доступ к файлам этой файловой системы тем способом, каким это предусмотрели разработчики, то есть мы увидим список файлов и сможем получить доступ к любому из них без необходимости искать файлы по сигнатурам. Но при этом мы не сможем получить или даже узнать об уже удалённых файлах.
Без монтирования образа NTFS мы сможем работать с хранящимися на нём файлами напрямую, то есть с одной стороны нам придётся искать файлы по сигнатурам, но с другой стороны мы получим доступ даже к удалённым файлам. Удалённые файлы доступны в результате того, что обычно удаление на HDD заключается в том, что информация о файле просто удаляется из «журнала» файловой системы, но сам файл остаётся там же, где и был (если его впоследствии случайно не перезаписали другим файлом). Что касается с SSD, то там обычно данные всё-таки удаляются.
Ничего не мешает комбинировать эти способы, причём криминалистические инструменты позволяют сделать поиск удалённых данных более эффективным, например, поиск удалённых файлов выполняется только на тех частях диска, которые считаются пустыми.
Как распаковать прошивку камеры
Рассмотрим пример распаковки прошивки камеры Network Surveillance DVR r80x20-pq (эту камеру я использовал в тестах, например, в статье «Аудит безопасности IP камер».
Ссылки на прошивки, которые мне удалось найти: https://download.xm030.cn/d/MDAwMDExNDI= и https://yadi.sk/d/LqvlLP-1u_z8cQ
Скачиваем и распаковываем архив. Он называется General_IPC_XM530_R80X20-PQ_WIFIXM711.711.Nat.dss.OnvifS_V5.00.R02.20210818_all.bin, для краткости последующих команд я переименую его в firmware.bin.
Проверим, что это за файл:
file firmware.bin
Вывод следующий:
firmware.bin: Zip archive data, at least v2.0 to extract, compression method=deflate
То есть это Zip архив.
Проверим с помощью Detect It Easy:
diec firmware.bin
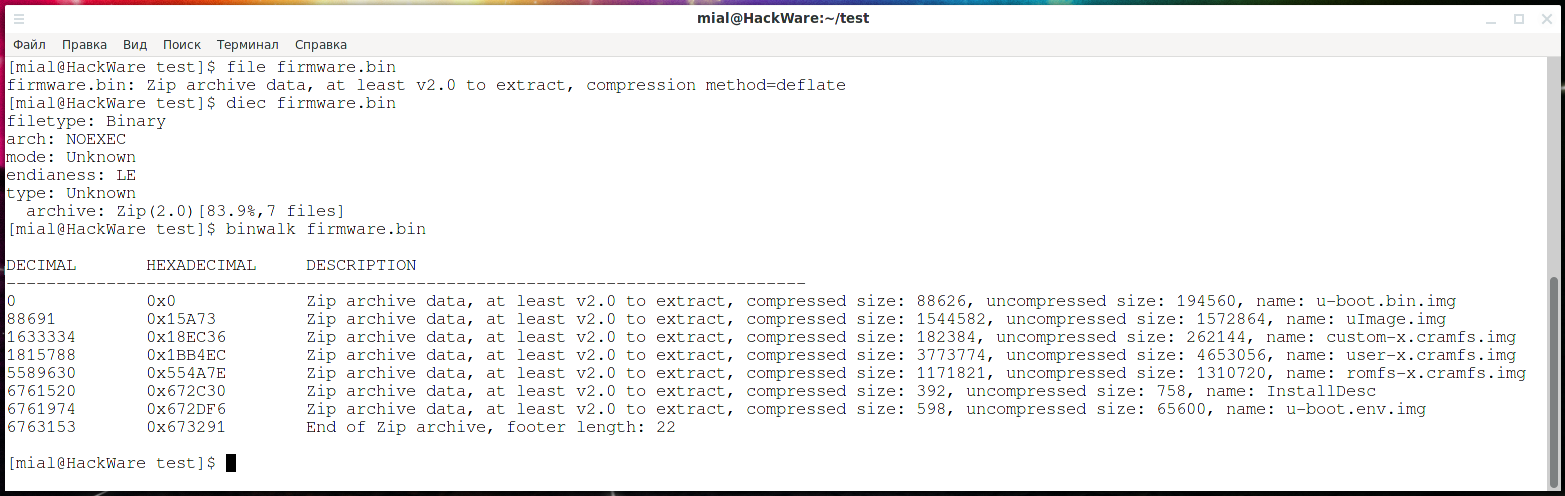
Также воспользуемся утилитой Binwalk, которая специально предназначена для анализа прошивок:
binwalk firmware.bin
Поскольку это просто архив, распакуем его:
unzip firmware.bin
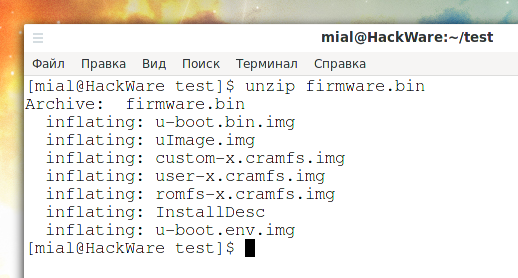
Видимо, следующие образы являются составными частями файловой системы:
- u-boot.bin.img
- uImage.img
- custom-x.cramfs.img
- user-x.cramfs.img
- romfs-x.cramfs.img
- u-boot.env.img
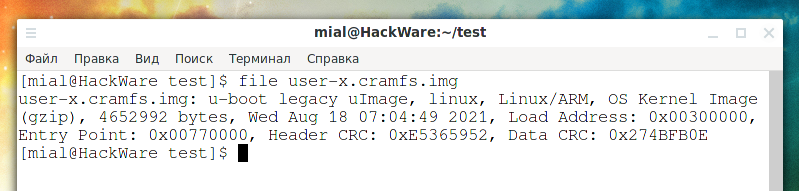
Поинтересуемся файлом user-x.cramfs.img:
file user-x.cramfs.img
Вывод:
user-x.cramfs.img: u-boot legacy uImage, linux, Linux/ARM, OS Kernel Image (gzip), 4652992 bytes, Wed Aug 18 07:04:49 2021, Load Address: 0x00300000, Entry Point: 0x00770000, Header CRC: 0xE5365952, Data CRC: 0x274BFB0E
U-Boot — это загрузчик для встроенных плат на базе PowerPC, ARM, MIPS и нескольких других процессоров, который можно установить в загрузочное ПЗУ и использовать для инициализации и тестирования оборудования или для загрузки и запуска кода приложения. В вашем Linux вы можете найти пакеты uboot-tools (Arch Linux и производные) и u-boot-tools (Debian и производные) — это инструменты и утилиты для сборки прошивок и выполнения с ними других действий.
Попробуем смонтировать образ user-x.cramfs.img:
mkdir /tmp/firmware sudo mount user-x.cramfs.img /tmp/firmware
Получаем ошибку:
mount: /tmp/firmware: wrong fs type, bad option, bad superblock on /dev/loop0, missing codepage or helper program, or other error.

Обратимся за помощью к утилите Binwalk, которая умеет находить файлы и файловые системы даже если они находятся не в начале:
binwalk -t user-x.cramfs.img
Вывод:
DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 0 0x0 uImage header, header size: 64 bytes, header CRC: 0xE5365952, created: 2021-08-18 07:04:49, image size: 4652992 bytes, Data Address: 0x300000, Entry Point: 0x770000, data CRC: 0x274BFB0E, OS: Linux, CPU: ARM, image type: OS Kernel Image, compression type: gzip, image name: "linux" 64 0x40 Squashfs filesystem, little endian, version 4.0, compression:xz, size: 3771362 bytes, 339 inodes, blocksize: 65536 bytes, created: 2021-08-18 07:04:49
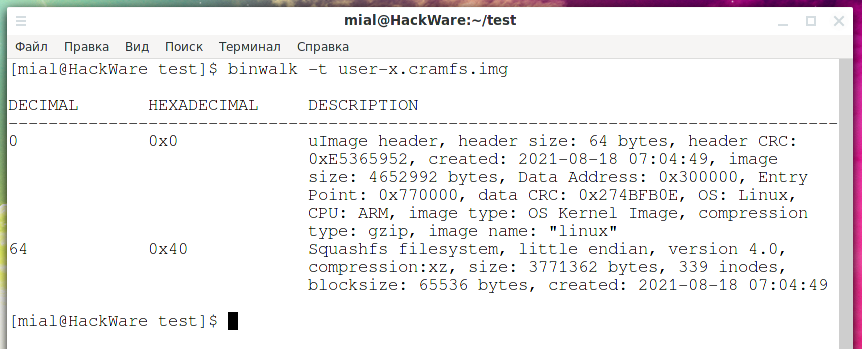
Теперь всё стало ясно — данный образ состоит из двух разделов. Первые 64 байта занимает заголовок uImage. А сама файловая система Squashfs идёт начиная с 64 байта.
Мы можем извлечь файловую систему — как это сделать сразу несколькими способами будет показано ниже, — но также по-прежнему можем её просто смонтировать, указав смещение:
sudo mount -o offset=64 user-x.cramfs.img /tmp/firmware
Посмотрим на файлы, размещённые в образе user-x.cramfs.img:
ls -l /tmp/firmware

В этом образе я не нашёл ничего интересного, размонтируем его:
sudo umount /tmp/firmware
Посмотрим, где начинается файловая система в romfs-x.cramfs.img:
binwalk romfs-x.cramfs.img
Смонтируем:
sudo mount -o offset=64 romfs-x.cramfs.img /tmp/firmware
Здесь можно найти хеш дефолтного пользователя root:
cat /tmp/firmware/etc/passwd
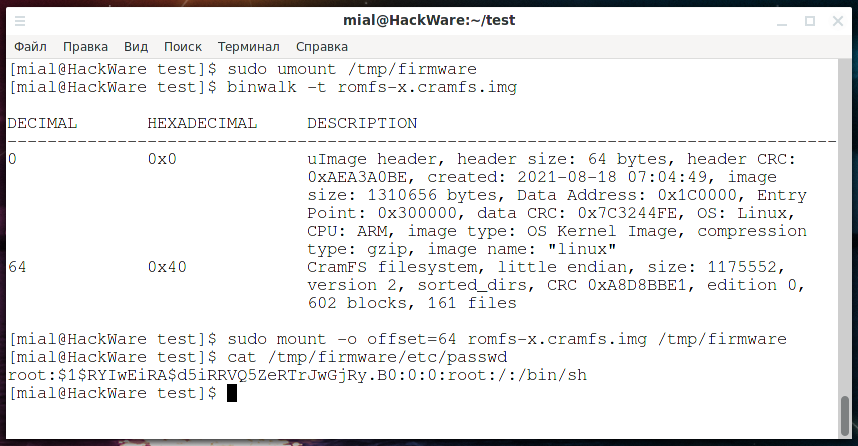
Аналогичным образом, сканируя с помощью Binwalk и монтируя разделы файловой системы, можно искать интересные файлы.
Смотрите также: Всё о монтировании: от системного администрирования до IT криминалистики
Как вырезать файловую систему из образа
1. Монтировать без извлечения
Как было показано выше, с помощью опции offset можно указать смещение и монтировать файловую систему которая является частью образа и расположена не в самом его начале:
sudo mount -o offset=СМЕЩЕНИЕ_ОБРАЗА /ТОЧКА/МОНТИРОВАНИЯ
Если образ содержит несколько файловых систем, вам может понадобиться указать ещё и опцию sizelimit — размер файловой системы:
sudo mount -o offset=СМЕЩЕНИЕ,sizelimit=РАЗМЕР_ОБРАЗА /ТОЧКА/МОНТИРОВАНИЯ
Например:
sudo mount -o offset=64,sizelimit=3771362 romfs-x.cramfs.img /tmp/firmware
2. Извлечение с помощью dd
Для примера возьмём прошивку ZyXEL Keenetic Lite II: https://help.keenetic.com/hc/article_attachments/115009890565/Keenetic-II-V2.06(AAFG.0)C3.zip
Найдём разделы в прошивке:
binwalk 'Keenetic-II-V2.06(AAFG.0)C3.bin'
Вывод:
DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 0 0x0 uImage header, header size: 64 bytes, header CRC: 0x8F18AEF5, created: 2017-10-19 13:25:49, image size: 1175311 bytes, Data Address: 0x80020000, Entry Point: 0x80020414, data CRC: 0x87BAAA6D, OS: Linux, CPU: MIPS, image type: OS Kernel Image, compression type: lzma, image name: "ZyXEL Keenetic II" 64 0x40 LZMA compressed data, properties: 0x6D, dictionary size: 8388608 bytes, uncompressed size: 3466800 bytes 1376256 0x150000 Squashfs filesystem, little endian, version 3.0, size: 6205991 bytes, 593 inodes, blocksize: 65536 bytes, created: 2017-10-19 13:25:45
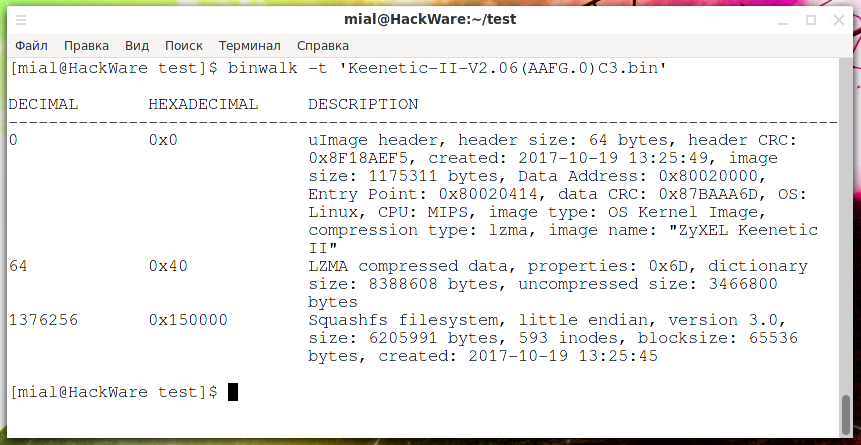
Всего имеется три области:
- с 0 по 64 байты — заголовок uImage.
- с 64 начинаются сжатые данные LZMA
- С 1376256 начинается файловая система Squashfs, её размер 6205991 байт, это следует из строки «size: 6205991 bytes».
Для извлечения каждого из этих разделов можно использовать команду вида:
dd if=ВХОД of=ВЫХОД bs=БЛОК count=ЗАПИСАТЬ skip=ПРОПУСТИТЬ
В ней:
- ВХОД — начальный образ
- ВЫХОД — извлекаемый раздел
- БЛОК — размер блока, больший размер блока ускоряет запись, но последующие значения ЗАПИСАТЬ и ПРОПУСТИТЬ указывают на количество блоков, то есть если размер блока взять за единицу, то будет проще считать
- ЗАПИСАТЬ — сколько блоков записать
- ПРОПУСТИТЬ — сколько блоков от начала файла пропустить
К примеру, из файла Keenetic-II-V2.06(AAFG.0)C3.bin я хочу извлечь первые 64 байт, тогда команда следующая:
dd if='Keenetic-II-V2.06(AAFG.0)C3.bin' of=uImage-header.bin bs=1 count=64 skip=0
Теперь я хочу извлечь второй раздел, начинающийся с 64 байта. Этот раздел заканчивается на байте 1376256, но опция count команды dd указывает сколько байт нужно прочитать (а не границу извлечения данных), поэтому значение count рассчитывается по формуле:
конец области - количество пропущенных байт
В нашем случае это 1376256 — 64 = 1376192, получаем команду:
dd if='Keenetic-II-V2.06(AAFG.0)C3.bin' of=data.lzma bs=1 count=1376192 skip=64
Файл LZMA можно распаковать, например, с помощью 7z:
7z e data.lzma
В принципе команда извлекла данные, хотя и сообщила об ошибке:
7-Zip [64] 17.04 : Copyright (c) 1999-2021 Igor Pavlov : 2017-08-28 p7zip Version 17.04 (locale=ru_RU.UTF-8,Utf16=on,HugeFiles=on,64 bits,12 CPUs x64) Scanning the drive for archives: 1 file, 1376192 bytes (1344 KiB) Extracting archive: data.lzma -- Path = data.lzma Type = lzma Method = LZMA:23:lc1:lp2 ERROR: There are some data after the end of the payload data : data Sub items Errors: 1 Archives with Errors: 1 Sub items Errors: 1
Суть ошибки в том, что после конца полезной нагрузки были обнаружены данные. Можно сказать, что это нормально (неизбежно) в данном случае, поскольку мы не знали точный размер блока и указали в качестве его конца байт, где начинается другой раздел. Другой раздел начинается с байта (в шестнадцатеричном виде) 0x150000, поэтому можно предположить, что для паддинга (padding, выравнивания) между разделами просто «набиты» нули. В этом можно убедиться, открыв файл data.lzma в шестнадцатеричном редакторе, например в Bless:
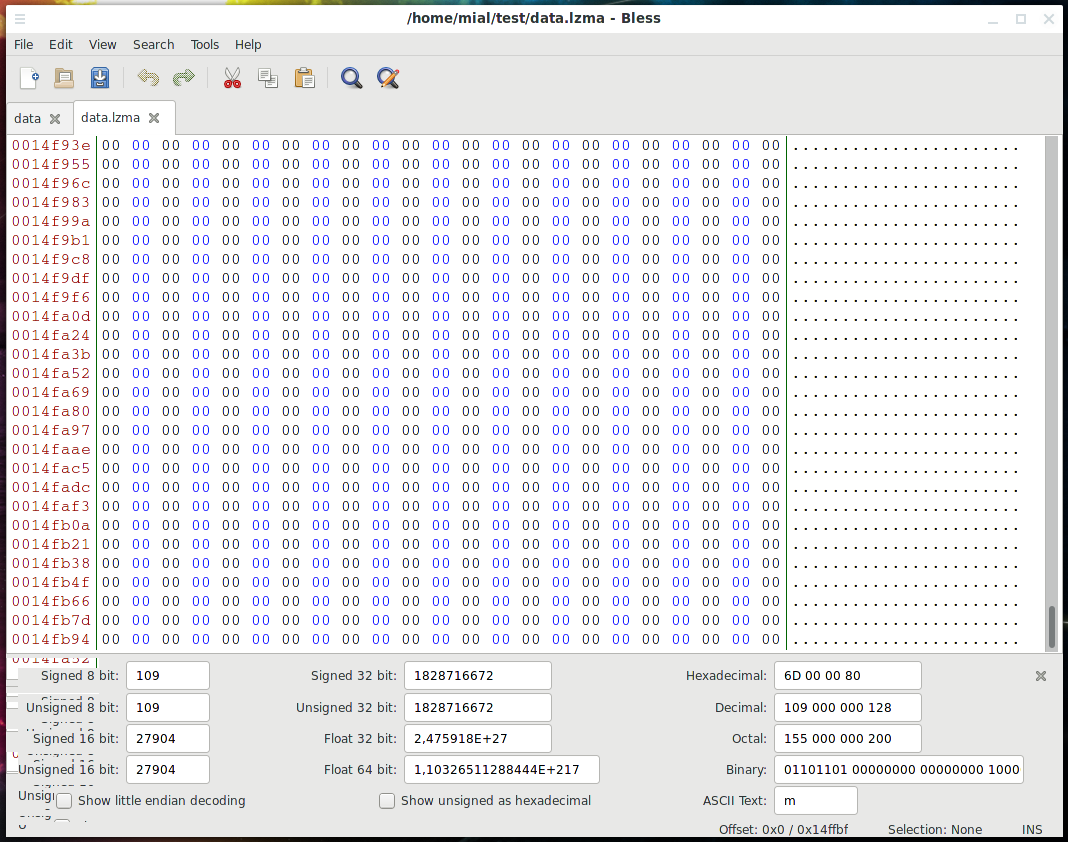
Да, в конце этого файла нули — если точный размер неизвестен, то лучше записать лишнего, чем потерять данные.
Третий блок начинается с 1376256 байта и имеет размер 6205991 об этом нам говорит строка «size: 6205991 bytes». Команда по его извлечению следующая:
dd if='Keenetic-II-V2.06(AAFG.0)C3.bin' of=filesystem.squashfs bs=1 count=6205991 skip=1376256
Но производители прошивки всё равно меня перехитрили использовав Squashfs version 3.0 из 2006 года и я не смог её открыть по техническим причинам:
sudo squashfuse -d filesystem.squashfs /tmp/firmware/ Squashfs version 3.0 detected, only version 4.0 supported.

3. Извлечение с помощью Binwalk
У программы Binwalk имеются следующие опции для извлечения:
-e, --extract Автоматически извлекать известные типы файлов
-z, --carve Вырезать данные из файлов, но не запускать утилиты извлечения
-D, --dd=ТИП[:РАСШИРЕНИЕ[:КОМАНДА]] Извлекать ТИПЫ сигнатур (регулярное выражение), дать фалу РАСШИРЕНИЕ и выполнить КОМАНДУ
Более подробное их описание вы можете прочитать в карточке программы https://kali.tools/?p=6771. Это кажется удобным — извлекать данные автоматически, но на практике результат будет не совсем тем, который вы ожидаете. Поскольку даже в ручном режиме мы не всегда точно знаем границы разделов, то это же самое относится и к указанным опциям, которые плохо работают с разделами, для которых не указан конкретный размер.
4. Извлечение с помощью dc3dd и dcfldd
У программы dd есть улучшенные версии dc3dd и dcfldd. При желании для извлечения разделов файловой системы из образа диска вы можете использовать их.
Поиск последовательности байтов в бинарном файле
Программы file, Binwalk и Detect It Easy в поиске данных используют сигнатуры. Эти сигнатуры предопределены в их базах данных (так называемые магические файлы).
Если вам нужно выполнить поиск по вашим собственным сигнатурам, то есть по строке бинарных данных, то вы можете использовать Binwalk со следующими опциями:
-R, --raw=СТРОКА Сканировать целевой файл(ы) в поисках указанной последовательности байтов
-m, --magic=ФАЙЛ Указать файл для использования в качестве источника сигнатур
Например, поиск шестнадцатеричных байтов 53EF в файле /mnt/disk_d/fs.ext4:
binwalk -R '\x53\xEF' /mnt/disk_d/fs.ext4
Программа sigfind из пакета Sleuth также позволяет искать по сигнатурам, при этом программа позволяет указать отступ от начала блока (НЕ файла). В программе прописаны несколько сигнатур для поиска файловых систем, например:
sigfind -t ext4 /mnt/disk_d/fs.ext4
В следующем примере ищется последовательность байтов 53EF (обратный порядок записи байтов) со смещением 56 от любого блока (если не указать смещение, то будут выведены только блоки, где данная последовательность байтов имеет смещение 0):
sigfind -o 56 -l EF53 /mnt/disk_d/fs.ext4
Заключение
Итак, показанные методы позволяют найти разделы файловых систем даже если они находятся не в начале образа. К примеру, попробуйте найти начало файловых систем в образах fs.ext4.xz, fs.ntfs.xz (из forensics-samples) без перечисленных здесь инструментов и вы лишний раз убедитесь, насколько облегчает анализ прошивок и составных файлов программа Binwalk и другие перечисленные в этой статье.
Связанные статьи:
- Как узнать тип файла без расширения (в Windows и Linux) (84.9%)
- Обратная инженерия сетевого трафика (54%)
- Обратный инжиниринг с использованием Radare2 (Reverse Engineering) (50%)
- Обратный инжиниринг с использованием Radare2 (Reverse Engineering) (часть 2) (50%)
- Анализ трояна Snojan (50%)
- Что делать если не загружается Linux (RANDOM - 0.2%)
Здравствуйте, Алексей. А с чего это uboot стал утилитой для сборки? Насколько мне известно, uboot является загрузчиком. Используется в router'ах, устройствах, которые используют os android и т.д. Принцип загрузки: код в rom > uboot > linux kernel > os android. Даже снимал его лог через uart у планшета. Часть лога:
U-Boot 2014.01 (Nov 17 2017 — 19:22:58)
DRAM: 512 MiB
efuse type 20020140
adie efuse read 0
wait 2
otp read blk 15 — 16
adie efuse read 15
wait 2
otp read bits 120 ++ 7 0x0000003c
Приветствую! Я говорил о пакете, который в репозитории Arch Linux называется «uboot-tools». В описании сказано «U-Boot bootloader utility tools».
Туда включены следующие инструменты:
1. mkimage, который собирает (генерирует) образ для U-Boot. Как сказано в описании mkimage: «Команда mkimage используется для создания образов для использования с загрузчиком U-Boot. Эти образы могут содержать ядро Linux, blob-объект дерева устройств, образ корневой файловой системы, образы прошивки и так далее, как по отдельности, так и вместе».
2. Инструмент mkenvimage — справки нет, но по названию можно догадаться, что генерирует раздел environment.
3. Утилита dumpimage с командами «list image header information», «extract component».
На мой взгляд, вполне себе утилиты для сборки и выполнения других действий с прошивками (с загрузчиком U-Boot), но дальше чтения справки этих команд я с ними не работал, поэтому, на самом деле, видимо, я просто не в курсе.
В статье вообще нет упоминания, что речь именно о пакете uboot-tools. Изначально я подумал, что загрузчик, поэтому и написал. Может, стоит уточнить?
Абсолютно согласен — в статье уже откорректировал. Спасибо, что поправили!