Парсинг сайтов: азы, продвинутые техники, сложные случаи
Что такое парсинг
Парсинг (parsing) – это буквально с английского «разбор», «анализ». Под парсингом обычно имеют ввиду нахождение, вычленение определённой информации.
Парсинг сайтов может использоваться при создании сервиса, а также при тестировании на проникновение. Для пентестера веб-сайтов, навык парсинга сайтов является базовыми, т.е. аудитор безопасности (хакер) должен это уметь.
Умение правильно выделить информацию зависит от мастерства владения регулярными выражениями и командой grep (очень рекомендую это освоить – потрясающее испытание для мозга!). В этой же статье будут рассмотрены проблемные моменты получения данных, поскольку все сайты разные и вас могут ждать необычные ситуации, которые при первом взгляде могут поставить в тупик.
В качестве примера парсинга сайтов, вот одна единственная команда, которая получает заголовки последних десяти статей, опубликованных на HackWare.ru:
curl -s https://hackware.ru/ | grep -E -o '<h3 class=ftitle>.*</h3>' | sed 's/<h3 class=ftitle>//' | sed 's/<\/h3>//'

Подобным образом можно автоматизировать получение и извлечение любой информации с любого сайта.
Особенности парсинга веб-сайтов
Одной из особенностей парсинга веб-сайтов является то, что как правило мы работаем с исходным кодом страницы, т.е. HTML кодом, а не тем текстом, который показывается пользователю. Т.е. при создании регулярного выражения grep нужно основываться на исходном коде, а не на результатах рендеринга. Хотя имеются инструменты и для работы с текстом, получающимся в результате рендеринга веб-страницы – об этом также будет рассказано ниже.
В этом разделе основной упор сделан на парсинг из командной строки Linux, поскольку это самая обычная (и привычная) среда работы для тестера на проникновение веб-приложений. Будут показаны примеры использования разных инструментов, доступных из консоли Linux. Тем не менее, описанные здесь приёмы можно использовать в других операционных системах (например, cURL доступна и в Windows), а также в качестве библиотеки для использования в разных языках программирования.
Подразумевается, что вы понимаете принципы работы командной строки Linux. Если это не так, то рекомендуется ознакомиться с циклом:
- Азы работы в командной строке Linux (часть 1)
- Азы работы в командной строке Linux (часть 2)
- Азы работы в командной строке Linux (часть 3)
Получение содержимого сайта в командной строке
Самым простым способом получения содержимого веб-страницы, а точнее говоря, её HTML кода, является команда вида:
curl ХОСТ
В качестве ХОСТа может быть адрес сайта (URL) или IP. На самом деле, curl поддерживает много разных протоколов – но здесь мы говорим именно о сайтах.
Пример:
curl https://hackware.ru/
Хорошей практикой является заключать URL (ссылки на сайты и на страницы) в одинарные или двойные кавычки, поскольку эти адреса могут содержать специальные символы, имеющие особое значение для Bash. К таким символам относятся амперсант (&), решётка (#) и другие.
Чтобы в командной строке присвоить полученные данные переменной, можно использовать следующую конструкцию:
HTMLCode="$(curl https://hackware.ru/)" echo "$HTMLCode"
Здесь
- HTMLCode – имя переменной (обратите внимание, что при присвоении (даже повторном) имя переменной пишется без знака доллара ($), а при использовании переменной, знак доллара всегда пишется.
- ="$(КОМАНДА)" – конструкция выполнения КОМАНДЫ без вывода результата в консоль; результат выполнения команды присваивается переменной. Обратите внимание, что ни до, ни после знака равно (=) нет пробелов – это важно, иначе возникнет ошибка.
Также полученное содержимое веб-страницы зачастую передаётся по трубе для обработке в других командах:
КОМАНДА1 | КОМАНДА2 | КОМАНДА3
Реальные примеры даны чуть ниже.
Отключение статистики при использовании cURL
Когда вы будете передавать полученное содержимое по трубе (|), то вы увидите, что команда curl показывает статистику о скорости, времени, количестве переданных данных:

Чтобы отключить вывод статистики, используйте опцию -s, например:
curl -s https://hackware.ru/
Автоматически следовать редиректам с cURL
Вы можете дать указание cURL следовать редиректам, т.е. открывать страницу, на которую делает редирект (перенаправление) та страница, которую мы в данный момент пытаемся открыть.
Например, если я попытаюсь открыть сайт следующим образом (обратите внимание на HTTP вместо HTTPS):
curl http://hackware.ru/
То я получу:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <html><head> <title>302 Found</title> </head><body> <h1>Found</h1> <p>The document has moved <a href="https://hackware.ru/">here</a>.</p> </body></html>
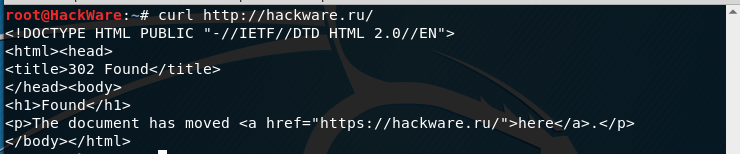
Чтобы curl переходила по перенаправлением используется опция -L:
curl -L http://hackware.ru/
Подмена User Agent при использовании cURL
Удалённый сервер видит, какая программа пытается к нему подключиться: это веб-браузер, или поисковый робот, или кто-то ещё. По умолчанию cURL передаёт в качестве User-Agent что-то вроде «curl/7.58.0». Т.е. сервер видит, что подключается не веб-браузер, а консольная утилита.
Некоторые веб-сайты не хотят ничего показывать консольным утилитам, например, если при обычном запросе вида:
curl URL
Вам не показывается содержимое веб-сайта (может выподиться сообщение о запрете доступа или о плохом боте), но при открытии в браузере вы можете видеть страницу, то используя опцию -A мы можем указать любой пользовательский агент, например:
curl -A 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' URL
Получение в cURL страниц со сжатием
Иногда при использовании cURL появляется предупреждение:
Warning: Binary output can mess up your terminal. Use "--output -" to tell Warning: curl to output it to your terminal anyway, or consider "--output Warning: <FILE>" to save to a file.
Его можно увидеть, например при попытке получить страницу с kali.org,
curl https://www.kali.org/
Суть сообщения в том, что команда curl выведет бинарные данные, которые могут навести бардак в терминале. Нам предлагают использовать опцию "—output —" (обратите внимание на дефис после слова output – он означает стандартный вывод, т.е. показ бинарных данных в терминале), либо сохранить вывод в файл следующим образом: "—output <FILE>".
Причина в том, что веб-страница передаётся с использованием компрессии (сжатия), чтобы увидеть данные достаточно использовать опцию —compressed:
curl --compressed https://www.kali.org/
В результате будет выведен обычный HTML код запрашиваемой страницы.
Неправильная кодировка при использовании cURL
В настоящее время на большинстве сайтов используется кодировка UTF-8, с которой cURL прекрасно работает.
Но, например, при открытии некоторых сайтов:
curl http://z-oleg.com/
Вместо кириллицы мы увидим крякозяблы:
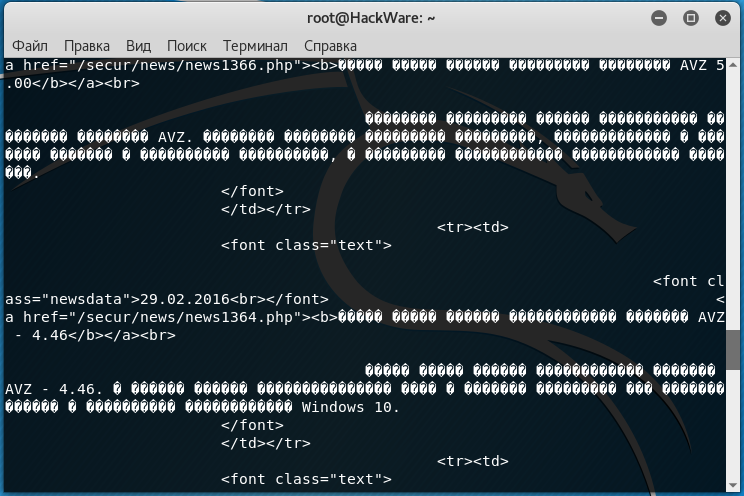
Кодировку можно преобразовать «на лету» с помощью команды iconv. Но нужно знать, какая кодировка используется на сайте. Для этого обычно достаточно заглянуть в исходный код веб-страницы и найти там строку, содержащую слово charset, например:
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
Эта строка означает, что используется кодировка windows-1251.
Для преобразования из кодировки windows-1251 в кодировку UTF-8 с помощью iconv команда выглядит так:
iconv -f windows-1251 -t UTF-8
Совместим её с командой curl:
curl http://z-oleg.com/ | iconv -f windows-1251 -t UTF-8
После этого вместо крякозяблов вы увидите русские буквы.
Изменение реферера с cURL
Реферер (Referrer URL) – это информация о странице, с которой пользователь пришёл на данную страницу, т.е. это та страница, на которой имеется ссылка, по которой кликнул пользователь, чтобы попасть на текущую страницу. Иногда веб-сайты не показывают информацию, если пользователь не содержит в качестве реферера правильную информацию (либо показывают различную информацию, в зависимости от типа реферера (поисковая система, другая страница этого же сайта, другой сайт)). Вы можете манипулировать значением реферера используя опцию -e. После которой в кавычках укажите желаемое значение. Реальный пример будет чуть ниже.
Вход на страницу с базовой аутентификацией при помощи cURL
Иногда веб-сайты требуют имя пользователя и пароль для просмотра их содержимого. С помощью опции -u вы можете передать эти учётные данные из cURL на веб-сервер как показано ниже.
curl -u username:password URL
По умолчанию curl использует базовую аутентификацию. Мы можем задать иные методы аутентификации используя —ntlm | —digest.
cURL и аутентификация в веб-формах (передача данных методом GET и POST)
Аутентификация в веб-формах – это тот случай, когда мы вводим логин и пароль в форму на сайте. Именно такая аутентификация используется при входе в почту, на форумы и т. д.
Использование curl для получения страницы после HTTP аутентификации очень сильно различается в зависимости от конкретного сайта и его движка. Обычно, схема действий следующая:
1) С помощью Burp Suite или Wireshark узнать, как именно происходит передача данных. Необходимо знать: адрес страницы, на которую происходит передача данных, метод передачи (GET или POST), передаваемая строка.
2) Когда информация собрана, то curl запускается дважды – в первый раз для аутентификации и получения кукиз, второй раз – с использованием полученных кукиз происходит обращение к странице, на которой содержаться нужные сведения.
Используя веб-браузер, для нас получение и использование кукиз происходит незаметно. При переходе на другую страницу или даже закрытии браузера, кукиз не стираются – они хранятся на компьютере и используются при заходе на сайт, для которого предназначены. Но curl по умолчанию кукиз не хранит. И поэтому после успешной аутентификации на сайте с помощью curl, если мы не позаботившись о кукиз вновь запустим curl, мы не сможем получить данные.
Для сохранения кукиз используется опция —cookie-jar, после которой нужно указать имя файла. Для передачи данных методом POST используется опция —data. Пример (пароль заменён на неверный):
curl --cookie-jar cookies.txt http://forum.ru-board.com/misc.cgi --data 'action=dologin&inmembername=f123gh4t6&inpassword=111222333&ref=http%3A%2F%2Fforum.ru-board.com%2Fmisc.cgi%3Faction%3Dlogout'
Далее для получения информации со страницы, доступ на которую имеют только зарегестрированные пользователи, нужно использовать опцию -b, после которой нужно указать путь до файла с ранее сохранёнными кукиз:
curl -b cookies.txt 'http://forum.ru-board.com/topic.cgi?forum=35&topic=80699&start=3040' | iconv -f windows-1251 -t UTF-8
Эта схема может не работать в некоторых случаях, поскольку веб-приложение может требовать указание кукиз при использовании первой команды (встречалось такое поведение на некоторых роутерах), также может понадобиться указать верного реферера, либо другие данные, чтобы аутентификация прошла успешно.
Смотрите также статью «Как использовать cURL для отправки кукиз».
Извлечение информации из заголовков при использовании cURL
Иногда необходимо извлечь информацию из заголовка, либо просто узнать, куда делается перенаправление.
Заголовки – это некоторая техническая информация, которой обмениваются клиент (веб-браузер или программа curl) с веб-приложением (веб-сервером). Обычно нам не видна эта информация, она включает в себя такие данные как кукиз, перенаправления (редиректы), данные о User Agent, кодировка, наличие сжатия, информация о рукопожатии при использовании HTTPS, версия HTTP и т.д.
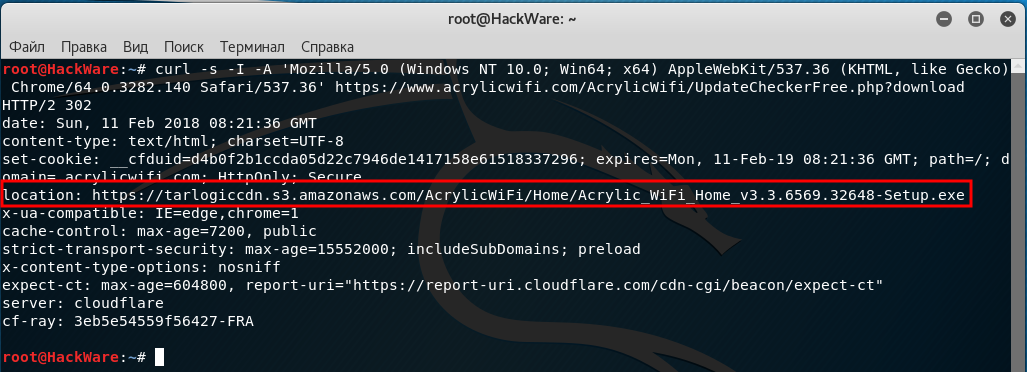
В моей практике есть реальный пример необходимости парсить заголовки. Есть программа Acrylic Wi-Fi Home, её особенностью является то, что на сайте нигде нет информации о текущей версии программы. Но номер версии содержится в скачиваемом файле, который имеет имя вида Acrylic_WiFi_Home_v3.3.6569.32648-Setup.exe. При этом имя файла также отсутствует в исходном HTML коде, поскольку при нажатии на кнопку «Скачать» идёт автоматический редирект на сторонний сайт. При подготовке парсера для softocracy, я столкнулся с ситуацией, что мне необходимо получить имя файла, причём желательно не скачивая его.
Пример команды:
curl -s -I -A 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' https://www.acrylicwifi.com/AcrylicWifi/UpdateCheckerFree.php?download | grep -i '^location'
Получаемый результат:
location: https://tarlogiccdn.s3.amazonaws.com/AcrylicWiFi/Home/Acrylic_WiFi_Home_v3.3.6569.32648-Setup.exe
В этой команде имеются уже знакомые нам опции -s (подавление вывода) и -A (для указания своего пользовательского агента).
Новой опцией является -I, которая означает показывать только заголовки. Т.е. не будет показываться HTML код, поскольку он нам не нужен.
На этом скриншоте видно, в какой именно момент отправляется информация о новой ссылке для перехода:
Аналоогичный пример для хорошо известной в определённых кругах программы Maltego (когда-то на сайте отсутствовала информация о версии и пришлось писать парсер заголовков):
curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' 2>&1 | grep -i 'Location:'
Обратите внимание, что в этой команде не использовалась опция -I, поскольку она вызывает ошибку:
Warning: You can only select one HTTP request method! You asked for both POST Warning: (-d, --data) and HEAD (-I, --head).
Суть ошибки в том, что можно выбрать только один метод запроса HTTP, а используются сразу два: POST и HEAD.
Кстати, опция -d (её псевдоним упоминался выше (—data), когда мы говорили про HTML аутентификацию через формы на веб-сайтах), передаёт данные методом POST, т.е. будто бы нажали на кнопку «Отправить» на веб-странице.
В последней команде используется новая для нас опция -v, которая увеличивает вербальность, т.е. количество показываемой информации. Но особенностью опции -v является то, что она дополнительные сведения (заголовки и прочее) выводит не в стандартный вывод (stdout), а в стандартный вывод ошибок (stderr). Хотя в консоли всё это выглядит одинаково, но команда grep перестаёт анализировать заголовки (как это происходит в случае с -I, которая выводит заголовки в стандартный вывод). В этом можно убедиться используя предыдущую команду без 2>&1:
curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' | grep -i 'Location:'
Строка с Location никогда не будет найдена, хотя на экране она явно присутствует.
Конструкция 2>&1 перенаправляет стандартный вывод ошибок в стандартный вывод, в результате внешне ничего не меняется, но теперь grep может обрабатывать эти строки.
Более сложная команда для предыдущего обработчика форм (попробуйте в ней разобраться самостоятельно):
timeout 10 curl -s -L -v http://www.paterva.com/web7/downloadPaths.php -d 'fileType=exe&client=ce&os=Windows' -e 'www.paterva.com/web7/downloads.php' 2>&1 >/dev/null | grep -E 'Location:'
Парсинг сайта, на котором текст создаётся с помощью JavaScript
Если контент веб-страницы формируется методами JavaScript, то можно найти необходимый файл с кодом JavaScript и парсить его. Но иногда код слишком сложный или даже обфусцированный. В этом случае поможет PhantomJS.
Особенностью PhantomJS ялвяется то, что это настоящий инструмент командной строки, т.е. может работать на безголовых машинах. Но при этом он может получать содержимое веб-страницы так, как будто бы вы её открыли в обычном веб-браузере, в том числе после работы JavaScript.
Можно получать веб-страницы как изображение, так и просто текст, выводимый пользователю.
К примеру, мне нужно распарсить страницу https://support.microsoft.com/en-us/help/12387/windows-10-update-history и взять с неё номер версии последней официальной сборки Windows. Для этого я создаю файл lovems.js следующего содержания:
var webPage = require('webpage');
var page = webPage.create();
page.open('https://support.microsoft.com/en-us/help/12387/windows-10-update-history', function (status) {
console.log('Stripped down page text:\n' + page.plainText);
phantom.exit();
});
Для его запуска использую PhantomJS:
phantomjs lovems.js
В консоль будет выведено в текстовом виде содержимое веб-страницы, которое показывается пользователям, открывшим страницу в обычном веб-браузере.
Чтобы отфильтровать нужные мне сведения о последней сборке:
phantomjs lovems.js | grep -E -o 'OS Build [0-9.]+\)' | head -n 1 | grep -E -o '[0-9.]+'
Будет выведено что-то вроде 15063.877.
Смотрите также пример использования PhantomJS когда нужно отправлять POST запрос перед получением страницы: «Как с помощью PhantomJS отправить POST запрос».
Парсинг в командной строке RSS, XML, JSON и других сложных форматов
RSS, XML, JSON и т.п. – это текстовые файлы, в которых данные структурированы определённым образом. Для разбора этих файлов можно, конечно, использовать средства Bash, но можно сильно упростить себе задачу, если задействовать PHP.
В PHP есть ряд готовых классов (функций), которые могут упростить задачу. Например SimpleXML для обработки RSS, XML. JSON для JavaScript Object Notation.
Если в системе установлен PHP, то необязательно использовать веб-сервер, чтобы запустить PHP скрипт. Это можно сделать прямо из командной строки. Например, имеется задача из файла по адресу https://hackware.ru/?feed=rss2 извлечь имена всех статей. Для этого создадим файл parseXML.php со следующим содержимым:
<?php
$t = $argv[1];
$str = new SimpleXMLElement($t);
foreach ($str->channel->item as $new_articles) {
echo $new_articles->title . PHP_EOL . PHP_EOL;
}
Запустить файл можно так:
php parseXML.php "`curl -s https://hackware.ru/?feed=rss2`"

В данном примере для получения файла с веб-сервера используется команда curl -s https://hackware.ru/?feed=rss2, полученный текстовый файл (строка) передаётся в качестве аргумента PHP скрипту, который обрабатывает эти данные.
Кстати, cURL можно было бы использовать прямо из PHP скрипта. Поэтому можно парсить в PHP не прибегая к услугам Bash. В качестве примера, создайте файл parseXML2.php со следующем содержимым:
<?php
$target_url = "https://hackware.ru/?feed=rss2";
$ch = curl_init($target_url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$response_data = curl_exec($ch);
if (curl_errno($ch) > 0) {
echo 'Ошибка curl: ' . curl_error($ch);
}
curl_close($ch);
$str = new SimpleXMLElement($response_data);
foreach ($str->channel->item as $new_articles) {
echo $new_articles->title . PHP_EOL . PHP_EOL;
}
И запустите его следующим образом из командной строки:
php parseXML2.php
Этот же самый файл parseXML2.php можно поместить в директорию веб-сервера и открыть в браузере.
Заключение
Здесь рассмотрены ситуации, с которыми вы можете столкнуться при парсинге веб-сайтов. Изученный материал поможет лучше понимать, что происходит в тот момент, когда вы подключаетесь к веб-сайту. Поскольку пентестер часто использует не веб-браузеры для работы с веб-сайтами: различные сканеры и инструменты, то знание о реферерах, User Agent, кукиз, заголовках, кодировках, аутентификации поможет быстрее разобраться с проблемой, если она возникнет.
Для часто встречающихся задач (сбор email адресов, ссылок) уже существует достаточно много инструментов – и часто можно взять готовое решение, а не изобретать велосипед. Но с помощью curl и других утилит командной строки вы сможете максимально гибко настроить получение данных с любого сайта.
Смотрите также: Как получить содержимое и кукиз .onion сайта в Python
Связанные статьи:
- Обход файерволов веб приложений Cloudflare, Incapsula, SUCURI (72.2%)
- Как использовать User Agent для атак на сайты (56.7%)
- Как добавить на сайт reCAPTCHA v3 для защиты от парсинга и спама (53.1%)
- Как снизить нагрузку на виртуальный хостинг (52.6%)
- Как запустить PHP скрипт без веб-сервера (52.6%)
- Анализ периметра при аудите безопасности сайтов (RANDOM - 50%)