Регулярные выражения в PHP (ч. 1)
Оглавление
Первая часть:
1. Регулярные выражения PHP для новичков
2. Особенности регулярных выражений в PHP
3. Функции для работы с регулярными выражениями в PHP
4. Функции PHP поиска по регулярным выражениям
Буквальное значение букв и цифр
( ) Группировка (последовательность из нескольких заданных символов)
Якоря — анкоры (начало и конец строки)
Внутренние (локальные) модификаторы шаблонов
9. «Жадные» и «ленивые» регулярные выражения
Вторая часть:
11. Непечатные символы в видимой форме в описании шаблона
12. Определение формальных утверждений
13. POSIX нотация для символьных классов
16. Функции PHP для поиска и замены по регулярному выражению
17. Другие функции PHP для работы с регулярными выражениями
18. Когда не нужно использовать регулярные выражения
Регулярные выражения PHP для новичков
Регулярное выражение — это шаблон, который описывает искомую строку используя специальный синтаксис.
Регулярные выражения имеют большое значение при поиске в тексте строк, точное содержание которых может быть неизвестно заранее, но которые должны соответствовать шаблону.
Например, я хочу из HTML страницы выбрать все строки, с HTML заголовками, в этом случае мне нужно написать регулярное выражение, которое найдёт все строки вида:
<h1>...</h1> <h2>...</h2> <h3>...</h3> <h4>...</h4>
и т.д.
Поиск сразу всех этих строк можно задать одним единственным регулярным выражением. При этом между тэгами заголовков может быть любой текст — заранее мы его не знаем, но, тем не менее, мы всё равно найдём все строки заголовков.
Регулярные выражения могут использоваться для валидации (проверки соответствия данных заданным условиям), например, по шаблону регулярного выражения можно проверить, является ли введённая строка верным адресом электронной почты, или является ли она верной ссылкой, или является ли она предложением какого-либо языка и так далее.
Без регулярных выражений невозможен разбор и анализ большого массива текстовой информации, например, для парсинга логов, парсинга сайтов и других аналогичных задач.
Особенности регулярных выражений в PHP
Регулярные выражения из-за истории возникновения имеют две основных ветви:
- PCRE (происходят от языка Perl)
- POSIX
К счастью, в своей основе эти группы регулярных выражений очень похожи. Имеются одиночные различия в синтаксисе или в наличии редко применимых возможностей.
С регулярными выражениями POSIX вы можете быть знакомы при использовании функции grep в системах Linux (кстати, рекомендуется прочитать статью по ссылке).
Если вы уже работали с регулярными выражениями в программе grep операционной системы Linux, то вам нужно обратить внимание на следующие отличия регулярных выражений PCRE, используемых в PHP:
1. Функции PCRE требуют, чтобы шаблон был заключён в разделители. О разделителях будет сказано ниже, но суть в том, что если в grep регулярное выражение выглядит так:
aaa
то в PHP оно будет выглядеть так:
/aaa/
То есть помещено между символами разделителя, которые не являются частью регулярного выражения. В качестве символов разделителя могут использоваться не только / (слэши), но и некоторые другие символы.
2. Если регулярное выражение POSIX (grep) совпадает с частью строки, то строка считается соответствующей регулярному выражению и возвращается полностью. Например:
echo bbbbbaaaccccccccccc | grep -E 'aaa'
Вернёт строку:
bbbbbaaaccccccccccc
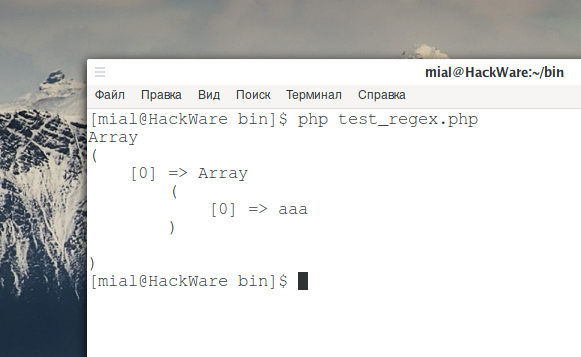
В PCRE (PHP) возвращается только совпавшая часть строки. Следующий пример:
<?php
preg_match_all ('/aaa/', 'bbbbbaaaccccccccccc', $found);
print_r($found);
вернёт
Array
(
[0] => Array
(
[0] => aaa
)
)
Такого поведения в grep можно добиться используя опцию:
-o, --only-matching показывать только совпавшие части строк
С этой опцией grep также будет выводить только ту часть строки, которая соответствует шаблону.
3. Следующее отличие уже является больше особенностью PHP, а не регулярных выражений: совпавшие части строки в PHP собираются в массив. При этом в grep совпавшие строки просто выводятся в стандартный вывод.
Это не различие в регулярных выражениях, это особенности применения регулярных выражений в различных контекстах.
4. В grep есть возможность установить опции, например, -i (для регистронезависимого поиска) -v (для поиска только тех строк, которые не соответствуют шаблону) и очень многие другие опции. У PHP функций нет возможности установить опции, но имеются модификаторы шаблона. Этих модификаторов шаблона не так много как опций у grep, но они могут выполнять важную настройку, например, включать поиск без учёта регистра. При этом модификаторы шаблонов можно применять как ко всему шаблону целиком, так и к части шаблона (например, установить часть шаблона будет искать без учёта регистра, а другая часть с учётом регистра).
5. Особенности в поддержки «символьных классов». В своей базовой функциональности символьные классы работают одинаково и в POSIX и PCRE, но имеются различия в некоторых более сложных случаях.
Кстати, регулярные выражения POSIX ранее поддерживались в PHP, но эта поддержка была удалена в 7.0.0. В следствии этого, следующие функции, которые предназначались для работы с регулярными выражениями POSIX, были удалены:
- ereg_replace — Осуществляет замену по регулярному выражению
- ereg — Совпадение с регулярным выражением
- eregi_replace — Осуществляет замену по регулярному выражению без учета регистра
- eregi — Совпадение с регулярным выражением без учёта регистра
- split — Разбиение строки на массив по регулярному выражению
- spliti — Разбивает строку в массив с помощью регулярного выражения без учета регистра
- sql_regcase — Создает регулярное выражение для регистронезависимого сравнения
Функции для работы с регулярными выражениями в PHP
Если столько удалено, то что там вообще осталось?! ![]() На самом деле, функций для поиска по регулярным выражениям и замены по регулярным выражениям в PHP достаточно:
На самом деле, функций для поиска по регулярным выражениям и замены по регулярным выражениям в PHP достаточно:
Функции PCRE:
- preg_filter — Производит поиск и замену по регулярному выражению
- preg_grep — Возвращает массив вхождений, которые соответствуют шаблону
- preg_last_error — Возвращает код ошибки выполнения последнего регулярного выражения PCRE
- preg_match_all — Выполняет глобальный поиск шаблона в строке
- preg_match — Выполняет проверку на соответствие регулярному выражению
- preg_quote — Экранирует символы в регулярных выражениях
- preg_replace_callback_array — Выполняет поиск и замену по регулярному выражению с использованием функций обратного вызова
- preg_replace_callback — Выполняет поиск по регулярному выражению и замену с использованием callback-функции
- preg_replace — Выполняет поиск и замену по регулярному выражению
- preg_split — Разбивает строку по регулярному выражению
Функции PHP поиска по регулярным выражениям
Как можно увидеть, имеется 3 функции поиска по регулярным выражениям:
- preg_grep
- preg_match_all
- preg_match
Особенность первой функции preg_grep: она ищет совпадения в переданном ей массиве (а не в одной строке). В качестве полученного результата возвращает также массив.
Функция preg_match_all ищет количество совпадений шаблону в строке. Возвращает число, соответствующее количеству найденных совпадений. Эту функцию можно использовать с разным количеством аргументов.
Например, запуск с двумя аргументами:
preg_match_all ($pattern, $subject)
Таким образом вы сможете узнать только количество найденных совпадений, но сами найденные совпадения вы не узнаете.
Если запустить с тремя аргументами:
preg_match_all ($pattern, $subject, $matches)
То в последнюю переменную в виде массива будут собраны все найденные совпадения строк.
Также можно запустить с четвёртым аргументом (флаг для установки порядки записи найденных совпадений в массив) и с пятым аргументом (сдвиг, показывающий с какой части строки искать совпадения), но это используется реже, поэтому рассмотрим это позже, чтобы не забивать сейчас голову.
Функция preg_match также может быть запущена с от двух до пяти аргументов, похожа на функцию preg_match_all. Но её особенностью является то, что она ищет хотя бы одно совпадение. Если это совпадение найдено, то другие совпадения не ищутся. Поэтому данная функция возвращает либо 0 (совпадения не найдены), либо 1 (совпадение найдено).
В случае, если указан дополнительный параметр $matches (если функция запущена с тремя или более аргументами), он будет заполнен результатами поиска. Элемент $matches[0] будет содержать часть строки, соответствующую вхождению всего шаблона, $matches[1] — часть строки, соответствующую первой подмаске и так далее.
Далее в примерах я буду использовать функцию preg_match_all.
Синтаксис регулярных выражений в PHP
Буквальное значение букв и цифр
По умолчанию цифры и буквы в регулярных выражениях имеют буквальное значение. Нужно помнить, что значение цифр и букв может иметь особый смысл, если они являются частью рассмотренных ниже конструкций. Но в остальных случаях это именно буквальная последовательность символов.
В примере выше регулярное выражение /aaa/ ищет буквальную строку aaa.
. (точка) — любой символ
Точка в регулярном выражении означает «один любой символ».
Например, регулярное выражение /<h./ будет искать строки, в которых после буквы h идёт какой-либо символ.
Рассмотрим пример анализа HTML кода. Заголовки в HTML обозначаются тэгом h1, h2, h3 и так далее. На сайте заголовки имеют вид:
<h1 style="text-align: justify;">
Или:
<h2 style="text-align: justify;">
Или:
<h3 style="text-align: justify;">
и т.д.
Задача: посчитать количество заголовков на сайте и вывести их.
Для получения страницы сайта, будет использоваться следующий код:
$link = 'https://hackware.ru/?p=7916';
$agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36';
$ch = curl_init($link);
curl_setopt($ch, CURLOPT_USERAGENT, $agent);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$response_data = curl_exec($ch);
if (curl_errno($ch) > 0) {
die('Ошибка curl: ' . curl_error($ch));
}
curl_close($ch);
Сейчас не стоит задача разбираться в нём, только запомните, что данные (загруженный HTML код страницы), сохраняется в переменную $response_data.
Регулярным выражением для поиска всех заголовков является
/<h. style="text-align: justify;">/
Итак, код целиком будет выглядеть так:
<?php
$link = 'https://hackware.ru/?p=7916';
$agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36';
$ch = curl_init($link);
curl_setopt($ch, CURLOPT_USERAGENT, $agent);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$response_data = curl_exec($ch);
if (curl_errno($ch) > 0) {
die('Ошибка curl: ' . curl_error($ch));
}
curl_close($ch);
$count = preg_match_all ('/<h. style="text-align: justify;">/', $response_data, $found);
echo 'Всего найдено совпадений: ' . $count . "\r\n";
print_r($found);
В нём мы присваиваем возвращаемое функцией preg_match_all значение переменной $count — в нём содержится количество найденных совпадений. Затем мы выводим количество найденных совпадений и массив $found, содержащий все найденные значения:
Как можно увидеть, было найдено целых 36 совпадений.

{ } — Повторения
Повторения — это специальные конструкции, которые указывают, сколько раз должен следовать подряд символ, для которого применяется это повторение.
{ } (фигурные скобки) используются для выражения минимального и максимального числа требуемых соответствий. Они могут задаваться четырьмя различными способами:
- {n} Соответствие предыдущего элемента, если он встречается ровно n раз.
- {n,m} Соответствие предыдущего элемента, если он встречается по меньшей мере n раз, но не более чем m раз.
- {n,} Соответствие предыдущего элемента, если он встречается n или более раз.
- {,m} Соответствие предыдущего элемента, если он встречается не более чем m раз.
Используя регулярное выражение /<h. style="text-align: justify;">/ мы исходили из того, что у заголовков есть стиль style="text-align: justify;". Но это свойство может быть не у всех заголовков, поэтому мы могли что-то пропустить.
Мы можем составить более гибкое регулярное выражение, например:
/<h.{1} /
Оно означает, что ищется буквальная строка <h, за которой идёт любой символ, но ровно 1 раз, а затем идёт пробел.
Получаем результат:

Совпадений нашлось намного больше, но среди них встречаются не только заголовки, но и строки, например <hr.
Следующее регулярное выражение
/abc{3}/
будет соответствовать строке abccc. Но что если мы хотим, чтобы регулярное выражение соответствовало строке abcabcabc (то есть последовательность abc повторяется три раза)?
Если нужно, чтобы повторение применялось ни к одному символу, а к группе символов, то тогда их нужно поместить в круглые скобки. Регулярное выражение
/(abc){3}/
Будет соответствовать строке abcabcabc.
Имеются частные случае обозначения количества:
- + (знак плюс) означает, что символ, который стоит перед этим символом, должен повториться один или более раз: «a+» соответствует «a», «aa», «aaa» и «Mondrian» (поскольку в этом слове a встречается хотя бы один раз). Равнозначно {1,}.
- * (символ звёздочки) означает, что символ, который стоит перед этим символом, должен повториться ноль раз или более. «a*» соответствует «a», «aa» и пустой строке («»). На самом деле, этот пример соответствует чему угодно. Равнозначно {0,}
- ? (знак вопроса) означает, что символ, который стоит перед этим символом может повторяться ноль или один раз (т.е. является необязательным). «colou?r» соответствует «color» и «colour». Равнозначно {0,1}
( ) Группировка (последовательность из нескольких заданных символов)
( ) , т.е. круглые скобки, позволяют вам группировать несколько символов, в результате модификаторы, например, повторители, будут применяться ко всему, что находится внутри скобок, а не к одному символу, который стоит перед модификатором.
/(ab)+/ соответствует ababababababab.
[] — Группы символов
В теги заголовков после h должны идти только цифры с 1 по 6, после h не может следовать буква или цифра больше 6. Для таких случаем имеются группы символов. В них перечисляются все возможные значения
Мы можем улучшить наше предыдущее регулярное выражение:
/<h.{1} /
Вместо точки мы будем использовать группу символов [123456], в которой перечислены все возможные варианты. Если буквы или цифры идут последовательно, то их можно указать через дефис, например, [1-6]
Итак, составляем регулярное выражение:
/<h[1-6]{1} /
Результат:
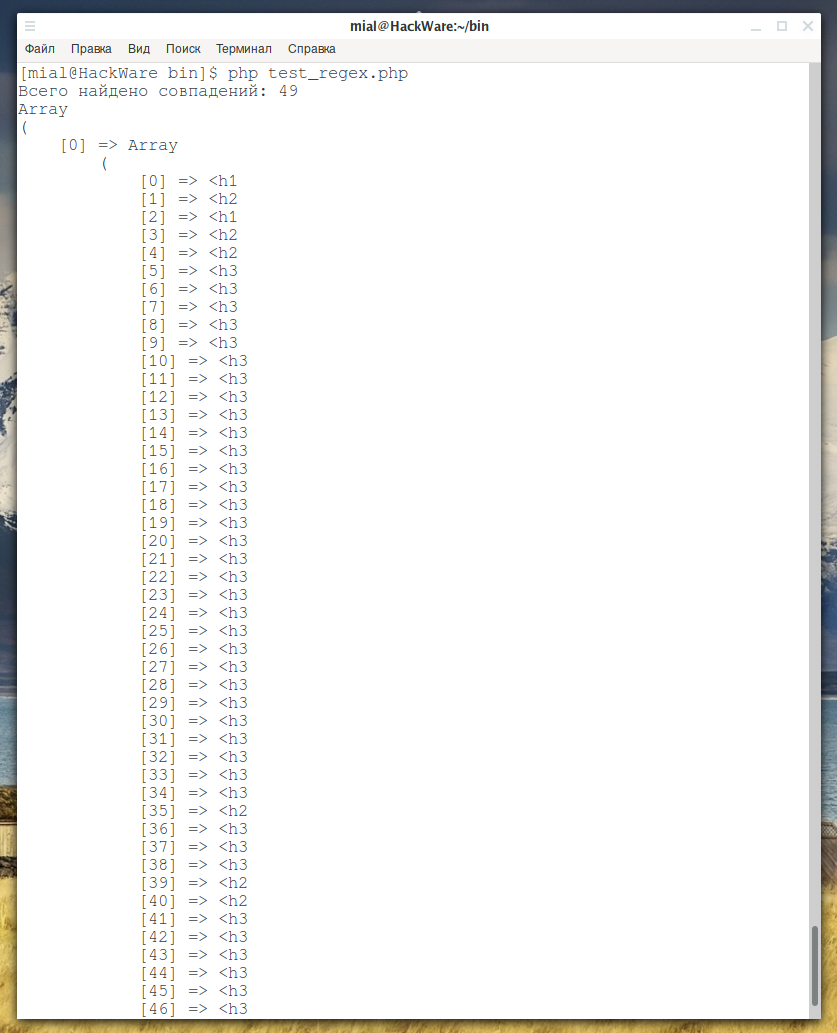
Отлично! Мы нашли больше настоящих заголовков!
Примеры диапазонов:
- [0-9] — все цифры
- [a-z] — все маленькие латинские буквы
- [a-zA-Z] — все маленькие и большие латинские буквы
- [a-zA-Z0-9] — все маленькие и большие латинские буквы, а также цифры
- [adrv018] — буквы a, d, r, v, либо цифра 0, 1, 8.
Если после диапазона не указано количество совпадений, то подразумевается одно совпадение.
| — ИЛИ (альтернатива)
| (символ «труба») означает «или», т.е. строка считается совпадающей, если в ней присутствует символ до трубы или после
/a|b/ означает a или b
С помощью скобок можно группировать символы
/(good)|(bad)/ соответствует good, bad, goods, badness, также соответствует goodbad (не смотря на то, что должно быть только что-то одно, в данной строке встречается строка good, что уже достаточно, также достаточно того, если встречается строка bad).
Заголовок в HTML коде может быть таким:
<h2>
Или иметь дополнительные атрибуты, например, таким:
<h2 style="text-align: justify;">
Составим регулярное выражение, которое это учитывает:
/<h[1-6]{1}( |>)/
Оно означает, что вначале ищется буквальная строка <h, затем идёт одна цифра в диапазоне от 1 до 6, затем идёт или пробел или символ >. Обратите внимание, что конструкция с ИЛИ (|) взята в скобки, чтобы оградить её от остальной части выражения. Если бы не было скобок, то тогда регулярное выражение искало бы совпадение с той его часть которая до символа | то есть <h[1-6]{1}( , либо после символа |, то есть >. В результате это полностью бы нарушило ожидаемую логику работы данного выражения.

Также обратите внимание на результаты. Мы уже знаем, что найденные строки собираются в массив. На самом деле, получается массив, у которого элементом под индексом 0 является другой массив — уже с теми самыми совпавшими строками. Сейчас всё также. Но у главного массива ещё появился элемент с индексом 1 — в него помещён другой массив со строками, которые совпали с выражением, помещённым в скобки. Если вы знаете, что такое обратные ссылки (в PHP их называют подмаски), так вот это они и есть. Если бы круглые скобки встречались два раза, то был бы ещё один массив в качестве элемента с индексом 2 и так далее.
НЕ (противоположность)
В классе символов, инвертирующим символом является ^.
/[^ab]/ соответствует любому символу, кроме a или b.
В предыдущем примере наши заголовки выводились в виде <h2> или в виде <h2 , если у заголовка имеется какой-либо атрибут. Давайте предположим, что мы хотим вывести тэг заголовка полностью, вместе с атрибутами (если они есть), то есть в таком виде:
<h2>
Или в таком виде:
<h2 style="text-align: justify;">
Всё начинается с символов <h, затем цифра. Потом может быть на выбор:
- тэг сразу кончается, то есть идёт >
- тэг не кончается — идёт пробел, потом самые разные символы кроме >, это обозначается так: « [^>]+», затем тэг всё таки заканчивается на >
Получаем регулярное выражение:
/<h[1-6]{1}( [^>]+>|>)/
И ещё, чтобы выводился только нулевой массив, без массивов совпадений с обратными ссылками, то мы заменим print_r($found); на print_r($found[0]);
Напомню код, которым я парсю страницу, если вы его потеряли:
<?php
$link = 'https://hackware.ru/?p=7916';
$agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36';
$ch = curl_init($link);
curl_setopt($ch, CURLOPT_USERAGENT, $agent);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$response_data = curl_exec($ch);
if (curl_errno($ch) > 0) {
die('Ошибка curl: ' . curl_error($ch));
}
curl_close($ch);
$count = preg_match_all ('/<h[1-6]{1}( [^>]+>|>)/', $response_data, $found);
echo 'Всего найдено совпадений: ' . $count . "\r\n";
print_r($found[0]);
Отлично, именно что мы и хотели:

Кстати, если мы хотим получить первый тэг заголовка, затем содержимое заголовка, а затем ещё и закрывающий тэг, то всё довольно просто
/<h[1-6]{1}( [^>]+>|>)[^<]+<\/h[1-6]{1}>/
Правда, не будут найдены заголовки разбитые на несколько строк, например:
<h3 style="text-align: justify;"> <a id="66" name="66"></a>Как смонтировать диск Tails с правами записи<br /> </h3>
Эти проблемы решаются, но пока не будет останавливаться на этом — лучше попробуйте самостоятельно разобраться с приведённым выше регулярным выражением, тем более, что представляет собой чуть изменённое предпоследнее. Правда, там встречается конструкция \/ - она означает экранированный слэш /, то есть поскольку слэш используется в качестве разделителя, то чтобы PHP не подумал, что в этом месте заканчивается маска, мы экранируем слэш, в результате он теряет своё специальное значение и начинает означать «буквальный символ /».
Якоря — анкоры (начало и конец строки)
По умолчанию заданное регулярное выражение ищется в любой части строки для анализа. Используя анкоры мы можем символически обозначить начало и (или) конец строки:
^ означает «начало строки». /^a/ соответствует «alpha» и «Arnold»
$ означает «конец строки». /a$/ соответствует «alpha» и «stella»
/^$/ соответствует пустой строке
/^ соответствует любой строке (у любой строки есть начало)
Метасимволы
Итак, в регулярном выражении буквы и цифры обычно имеют своё буквальное значение. Хотя если цифры, например, в фигурных скобках {3,5}, то это означает, что предыдущий символ или набор символов (если они ограничены круглыми скобками или квадратными скобками) встречаются указанное количество раз.
То есть некоторые символы имеют специальное значение. Если, допустим, вы хотите использовать буквальное значение метасимвола, например, искать строку, содержащую $ (знак доллара), то вам нужно закомментировать этот метасимвол обратным слэшом \, чтобы получилось так: \$. В этом случае метасимвол теряет своё специальное значение и начинает восприниматься как самый обычный символ.
Далее будут приведены все изученные метасимволы. Также помните, что символ выбранный в качестве разделителя также начинает иметь специальное значение — при следующем использовании он будет означать конец регулярного выражения. Поэтому если вы хотите использовать буквальное значение символа, выбранного в качестве разделителя, то экранируйте его. О разделителях чуть ниже.
Существуют два различных набора метасимволов: те, которые используются внутри квадратных скобок, и те, которые используются вне квадратных скобок. Вне квадратных скобок используются следующие метасимволы:
Метасимволы вне квадратных скобок
| Метасимвол | Описание |
|---|---|
| \ | общий экранирующий символ, допускающий несколько вариантов применения |
| ^ | декларирует начало данных (или строки в многострочном режиме) |
| $ | декларирует конец данных или до завершения строки (или окончание строки в многострочном режиме) |
| . | соответствует любому символу, кроме перевода строки (по умолчанию) |
| [ | начало описания символьного класса |
| ] | конец описания символьного класса |
| | | начало ветки условного выбора |
| ( | начало подмаски |
| ) | конец подмаски |
| ? | расширяет смысл метасимвола (, является также квантификатором, означающим 0 или 1 вхождение, также преобразует жадные квантификаторы в ленивые (об этом ниже)) |
| * | квантификатор, означающий 0 или более вхождений |
| + | квантификатор, означающий 1 или более вхождений |
| { | начало количественного квантификатора |
| } | конец количественного квантификатора |
Часть шаблона, заключенная в квадратные скобки называется символьным классом. В символьном классе используются следующие метасимволы:
Метасимволы внутри квадратных скобок (символьном классе)
| Метасимвол | Описание |
|---|---|
| \ | общий экранирующий символ |
| ^ | означает отрицание класса, допустим только в начале класса |
| - | означает символьный интервал |
Разделители
При использовании любой PCRE функции необходимо заключать шаблон в разделители. Разделителем может быть любой символ не являющийся буквой, цифрой, обратной косой чертой или каким-либо пробельным символом.
Часто используемыми разделителями являются косые черты (/), знаки решетки (#) и тильды (~). Ниже представлены примеры шаблонов с корректными разделителями.
/foo bar/ #^[^0-9]$# +php+ %[a-zA-Z0-9_-]%
Также можно использовать разделитель в виде скобок, где стартовый и завершающий разделители являются соответственно открывающей и закрывающей скобками. (), {}, [] и <> являются допустимыми парами разделителей.
(this [is] a (pattern))
{this [is] a (pattern)}
[this [is] a (pattern)]
<this [is] a (pattern)>
Разделители в виде скобок не нужно экранировать, если они также используются как метасимволы в шаблоне, но как и с другими разделителями их нужно экранировать, если они используются непосредственно как символы.
Если необходимо использовать разделитель внутри шаблона, его нужно проэкранировать с помощью обратной косой черты. Если разделитель часто используется в шаблоне, в целях удобочитаемости, лучше выбрать другой разделитель для этого шаблона.
/http:\/\// #http://#
Функция preg_quote() может быть использована для экранирования строки, используемой в шаблоне, а ее необязательный второй параметр позволяет указать используемый разделитель.
После закрывающего разделителями можно использовать модификаторы шаблонов. Ниже следует пример регистро-независимого поиска:
#[a-z]#i
Модификаторы шаблонов
Теперь мы дошли до тех самых модификаторов, которые выполняют роль опций.
Самый простой случай применения — это указать опцию после маски. К примеру, модификатор шаблона i означает поиск без учёта регистра. К примеру маска:
/cat/
Будет соответствовать строке «cat».
А маска:
/cat/i
Будет соответствовать строкам cat, Cat, CAT, cAt и так далее.
Итак, имеются следующие модификаторы:
i
Означает поиск без учёта регистра.
m
Если этот модификатор не используется, что метасимволы '^' и '$', на самом деле, соответствуют началу всего обрабатываемого текста и концу всего обрабатываемого текста — даже если текст разбит на несколько строк. Если же используется этот модификатор, то метасимволы '^' и '$' начинают работать как и предполагается: они означают начало строк и конец строк. В случае, если обрабатываемый текст не содержит символов перевода строки, либо шаблон не содержит метасимволов '^' или '$', данный модификатор не имеет никакого эффекта.
s
Хотя выше сказано, что . (точка) означает любой символ, на самом деле, правильнее так: «любой символ, кроме перевода строк». Если использовать данный модификатор, то метасимвол «.» действительно начинает означать «любой символ», в том числе включая перевод строк.
x
Если используется данный модификатор, неэкранированные пробелы, символы табуляции и пустой строки будут проигнорированы в шаблоне, если они не являются частью символьного класса. Также игнорируются все символы между неэкранированным символом '#' (если он не является частью символьного класса) и символом перевода строки (включая сами символы '\n' и '#').
A
Если используется данный модификатор, соответствие шаблону будет достигаться только в том случае, если он "заякорен", то есть соответствует началу строки, в которой производится поиск.
D
Если используется данный модификатор, метасимвол $ в шаблоне соответствует только окончанию обрабатываемых данных. Без этого модификатора метасимвол $ соответствует также позиции перед последним символом, в случае, если им является перевод строки (но не распространяется на любые другие переводы строк). Данный модификатор игнорируется, если используется модификатор m.
S
В случае, если планируется многократно использовать шаблон, имеет смысл потратить немного больше времени на его анализ, чтобы уменьшить время его выполнения. В случае, если данный модификатор используется, проводится дополнительный анализ шаблона. В настоящем это имеет смысл только для "незаякоренных" шаблонов, не начинающихся с какого-либо определенного символа.
U
Этот модификатор инвертирует жадность квантификаторов, таким образом они по умолчанию не жадные. Но становятся жадными, если за ними следует символ ?.
Подробнее про жадность и ленивость квантификаторов будет далее.
X
Этот модификатор включает дополнительную функциональность PCRE, которая не совместима с Perl: любой обратный слеш в шаблоне, за которым следует символ, не имеющий специального значения, приводят к ошибке. Это обусловлено тем, что подобные комбинации зарезервированы для дальнейшего развития. По умолчанию же, как и в Perl, слеш со следующим за ним символом без специального значения трактуется как опечатка. На сегодняшний день это все возможности, которые управляются данным модификатором
J
Модификатор (?J) меняет значение локальной опции PCRE_DUPNAMES - подшаблоны могут иметь одинаковые имена. Модификатор J поддерживается с версии PHP 7.2.0.
u
Этот модификатор включает дополнительную функциональность PCRE, которая не совместима с Perl: шаблон и целевая строка обрабатываются как UTF-8 строки. Недопустимая целевая строка приводит к тому, что функции preg_* ничего не находят, а неправильный шаблон приводит к ошибке уровня E_WARNING. Пятый и шестой октеты UTF-8 последовательности рассматриваются недопустимыми с PHP 5.3.4 (согласно PCRE 7.3 2007-08-28); ранее они считались допустимыми.
На мой взгляд, на практике действительно важными являются модификаторы i (поиск без учёта регистра) и U (изменение жадности операторов на противоположную).
Внутренние (локальные) модификаторы шаблонов
Модификаторы шаблонов можно указывать не только после регулярного выражения, но и локально, внутри шаблона. Для этого их помещают между символами "(?" и ")".
Это поддерживают следующие модификаторы шаблонов:
- i
- m
- s
- x
- U
- J
Например, (?im) указывает на регистронезависимый, многострочный режим поиска. Также можно сбросить опцию, поставив перед ней символ '-', либо комбинировать установку и отмену режимов. Например, (?im-sx) устанавливает флаги «i» и «m» и отменяет флаги «s» и «x». В случае, если символ расположен одновременно после и перед символом '-', опция будет отменена.
Если изменение опции происходит на самом верхнем уровне (т.е. вне подмаски), изменение будет применено к оставшейся части шаблона. Таким образом, /ab(?i)c/ совпадёт только с "abc" и "abC".
Если изменение опции происходит внутри подмаски, эффект будет другим. Изменение опции внутри подмаски повлияет только на оставшуюся часть этой подмаски, то есть (a(?i)b)c совпадёт только с 'abc' и 'aBc' и больше ни с чем (разумеется, если «i» не включён). Это означает, что в разных частях шаблона опции могут отличаться. Любые изменения, произошедшие в одной альтернативной ветке, переносятся и в другие ветки в пределах одной подмаски. Например, (a(?i)b|c) совпадёт с "ab", "aB", "c", и "C".
«Жадные» и «ленивые» регулярные выражения
Кванторы — это то, что отвечает за количество символов, например, {n,m}, + (один или более символов), * (ноль или более символов) и так далее.
Так вот кванторы бывают либо «жадные», либо «ленивые» (видимо, хороших среди них вообще нет ![]() ).
).
Это серьёзный вопрос, так как может давать неожиданный результат при поиске по регулярному выражению. Особенно это встречается когда возможны варианты интерпретации.
Допустим, в качестве регулярного выражения имеется:
/a+/
Оно означает маленькую букву a один или более раз.
А строкой, по которой производится поиск, является:
aaaaaaaaaaaabbbbbbbbbcccc
Что именно найдёт регулярное выражение? Строку «a»? Ведь это удовлетворяет условию регулярного выражения. Или строку «aaaaaaaaaaaa»? Ведь она тоже удовлетворяет указанному регулярному выражению. Или строку какой-то промежуточной длины?
Давайте проверим сами:
<?php
$count = preg_match_all ('/a+/', 'aaaaaaaaaaaabbbbbbbbbcccc', $found);
echo 'Всего найдено совпадений: ' . $count . "\r\n";
print_r($found[0]);
Получили:

Этот пример может оказаться оторванным от жизни — искусственным, давайте рассмотрим более практический случай. Имеется строка по которой нужно выполнить поиск:
<em>Hello World</em>
Мы используем регулярное выражение
/<.+>/
И ожидаем, что будут найдены только тэги <em> и </em>, которые соответствуют шаблону регулярного выражения. Но (ВНЕЗАПНО) в действительности будет найдена вся строка <em>Hello World</em> вместо того результата, который вы ожидаете.
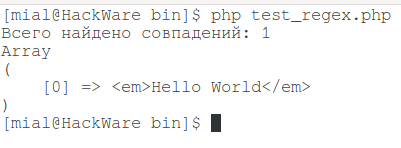
Эта строка также соответствует приведённому регулярному выражению.
Это означает, что квантор (в данном случае это +) является жадным. Или по-английски Greedy. В свою очередь ленивый квантор (от английского Lazy) означает, что будет искаться минимальная удовлетворяющая условиям поиска строка. Для переключения жадный/ленивый квантора после него нужно поставить ? (знак вопроса).
<?php
$count = preg_match_all ('/<.+?>/', '<em>Hello World</em>', $found);
echo 'Всего найдено совпадений: ' . $count . "\r\n";
print_r($found[0]);
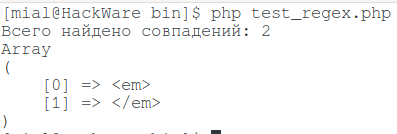
Итак:
- Жадный — будет найдена максимально возможная строка, соответствующая шаблону
- Ленивый — будет найдена минимальная строка, соответствующая шаблону
Как уже было сказано, знак вопроса является переключателем, приведём таблицу кванторов и их жадности:
| Жадный квантор | Ленивый квантор | Описание |
|---|---|---|
| * | *? | Знак звёздочки: 0 или более |
| + | +? | Знак плюс: 1 или более |
| ? | ?? | Знак вопроса: 0 или 1 |
| {n} | {n}? | ровно n |
| {n,} | {n,}? | n или более |
| {,m} | {,m}? | m или менее |
| {n,m} | {n,m}? | Между n и m |
Если вам нужно переключить сразу все кванторы в противоположную позицию, то используйте модификатор U.
Посмотрим наш предыдущий пример, но теперь добавим в регулярное выражение модификатор U:
<?php
$count = preg_match_all ('/a+/U', 'aaaaaaaaaaaabbbbbbbbbcccc', $found);
echo 'Всего найдено совпадений: ' . $count . "\r\n";
print_r($found[0]);
Результат вот такой:
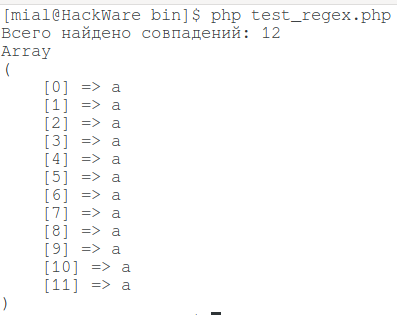
Регулярное выражение /a+/U в данном случае можно было бы записать и так: /a+?/
Продолжение во Второй части.
Связанные статьи:
- Регулярные выражения в PHP (ч. 2) (100%)
- Какой язык программирования выбрать для изучения (53.9%)
- Как запустить PHP скрипт без веб-сервера (53.9%)
- Списки прокси (53.9%)
- ASCII и шестнадцатеричное представление строк. Побитовые операции со строками (50%)
- Настройка рабочего окружения PowerShell в Windows и Linux (RANDOM - 50%)