Введение в Ассемблер
Источник: https://www.tutorialspoint.com/assembly_programming/assembly_quick_guide.htm
Оглавление
Руководство по программированию на Ассемблер
1.1 Для кого эти уроки по ассемблеру
1.2 Что нужно для изучения Ассемблера
1.4 Преимущества языка Ассемблер
2.1 Основные характеристики аппаратной составляющей ПК
2.2 Двоичная система счисления
2.3 Шестнадцатеричная система счисления
2.4 Отрицательные двоичные числа
3. Настройка рабочего окружения для Ассемблер
3.1 Настройка локального рабочего окружения
4. Основы синтаксиса Ассемблера
4.6 Компиляция и связывание (Linking) программы на Ассемблере в NASM
6. Ассемблер: регистры (Registers)
7. Ассемблер: Системные вызовы
8. Ассемблер: Режимы адресации
8.4 Прямая адресация со смещением
8.5 Косвенная адресация на память
9.1 Выделение пространства хранения для инициализированных данных
9.2 Выделение дискового пространства для неинициализированных данных
9.3 Множественность определений
9.4 Множественность инициализаций
11. Ассемблер: Арифметические инструкции
12. Ассемблер: Логические инструкции
21. Ассемблер: Управление файлами
21.3 Системные вызовы обработки файлов
21.4 Создание и открытие файла
21.5 Открытие существующего файла
22. Ассемблер: Управление памятью
Данный материал — это азы языка программирования Ассемблер для абсолютных новичков. Здесь говорится о том, как написать программу на Ассемблере, приводятся основные команды Ассемблера, имеются примеры программа на Ассемблер и подробно описано как скомпилировать первую программу.
В целом материал является переводом «Assembly — Introduction» — небольшого учебника, в котором рассматриваются основы языка Ассемблер, но также имеются дополнения — некоторые вопросы рассмотрены более подробно.
Если у вас есть опыт изучения или даже программирования на других языках, всё равно Ассемблер потребует понимания новых концепций.
Руководство по программированию на Ассемблер
Язык Ассемблер — это низкоуровневый язык программирования для компьютеров или других программируемых устройств, он специфичен для конкретной компьютерной архитектуры центрального процессора, что отличает его от большинства высокоуровневых языков программирования, которые обычно портативны среди разных систем. Язык Ассемблер преобразуется в исполняемый машинный код с помощью служебной программы, называемой ассемблером, такой как NASM, MASM и т. д.
Для кого эти уроки по ассемблеру
Этот учебник был разработан для тех, кто хочет изучить основы программирования на Ассемблере с нуля. Из этих уроков вы получите достаточное представление о программировании на Ассемблере, благодаря которому вы сможете продолжить обучения в данной области и подняться на высокий уровень знаний.
Что нужно для изучения Ассемблера
Прежде чем приступить к этому учебному пособию, вы должны иметь базовые знания по терминологии компьютерного программирования. Базовое понимание любого из языков программирования поможет вам понять концепции программирования на Ассемблере и быстро продвигаться в процессе обучения.
Что такое язык Ассемблер?
Каждый персональный компьютер имеет микропроцессор, который управляет арифметической, логической и контрольной активностью.
Каждая семья процессоров имеет свой собственный набор инструкций для обработки различных операций, таких как получения ввода с клавиатуры, отображение информации на экране и выполнения различных других работ. Этот набор инструкций называется «инструкции машинного языка» ('machine language instructions').
Процессор понимает только инструкции машинного языка, которые являются строками из единиц и нулей. При этом машинный язык слишком непонятный и сложный для использования его в разработки программного обеспечения. И низкоуровневый язык Ассемблер предназначен для определённый групп процессоров, он представляет различные инструкции в символическом коде и более понятной форме.
Преимущества языка Ассемблер
Знание языка ассемблера позволяет понять:
- Как программы взаимодействуют с ОС, процессором и BIOS;
- Как данные представлены в памяти и других внешних устройствах;
- Как процессор обращается к инструкции и выполняет её;
- Как инструкции получают доступ и обрабатывают данные;
- Как программа обращается к внешним устройствам.
Другие преимущества использования ассемблера:
- Программы на нём требует меньше памяти и времени выполнения;
- Это упрощает сложные аппаратные задачи;
- Подходит для работ, в которых время выполнения является критичным;
- Он наиболее подходит для написания подпрограмм обработки прерываний и других программ, полностью находящихся в оперативной памяти.
Системы счисления
Основные характеристики аппаратной составляющей ПК
Каждый компьютер содержит процессор и оперативную память. Процессор содержит регистры — компоненты, которые содержат данные и адреса. Для выполнения программы, система копирует её с устройства постоянного хранения во внутреннюю память. Процессор выполняет инструкции программы.
Фундаментальной единицей компьютерного хранилища является бит. Он может быть в состоянии Включён (1) или Выключен (0). Группа из восьми связанных битов составляет байт, из которых семь бит используются для данных, а ещё один используется для контроля чётности. Согласно правилу чётности, количество битов, которые Включены (1) в каждом байте, всегда должно быть чётным. То есть бит чётности имеет значение 1, если у соответствующего байта количество 1-х битов нечётно. 0 — если иначе (чётно).
Таким образом, бит чётности используется для того, чтобы сделать количество битов в байте чётным. Если соотношение является нечётным, система предполагает, что произошла ошибка соотношения (хотя и редко), которая могла быть вызвана неисправностью оборудования или электрическими помехами.
Выше бит чётности рассмотрен на примере "even parity", то есть «чётная чётность». Также существует "odd parity", то есть «нечётная чётность». В первом случае подгоняется под чётное количество единиц как было показано выше. А во втором случае подгоняется под нечётное количество единиц.
Процессор поддерживает следующие размеры данных —
- Word: 2-байтовый элемент данных
- Doubleword: a 4-байтовый (32 бита) элемент данных
- Quadword: 8-байтовый (64 бита) элемент данных
- Paragraph: 16-байтовая (128 бита) область
- Kilobyte: 1024 байт
- Megabyte: 1,048,576 байт
Двоичная система счисления
В каждой системе счисления используются позиционные обозначения, то есть каждая позиция, в которой записана цифра, имеет различное позиционное значение. Каждая позиция — это степень базы, которая равна 2 для двоичной системы счисления, и эти степени начинаются с 0 и увеличиваются на 1.
В следующей таблице приведены позиционные значения для 8-битного двоичного числа, где все биты установлены в положение ON (Включено).
| Значение бита | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|---|---|---|---|---|---|---|---|
| Значение позиции как степень основания 2 | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
| Номер бита | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Значение двоичного числа, как и в десятичном, зависит от составляющих его цифр и расположения этих цифр. Но в двоичном числе используются только цифры 1 и 0, и расположение цифр имеет другое значение степени. Первая цифра, как и в десятичном числе, может означать 0 или 1. Вторая цифра (смотрим число справа на лево) может означать 2 (если этот бит установлен на 1) или 0 (если бит установлен на 0). Третья цифра (смотрим число справа на лево) может означать 4 (если этот бит установлен на 1) или 0 (если бит установлен на 0). И так далее. В десятичном числе значение каждого символа нужно умножить на 10 в степени порядкового номера этой цифры за минусом единицы.
То есть число 1337 это 1 * 103 + 3 * 102 + 3 * 101 + 7 * 100 = 1337
В двоичной системе всё точно также, только вместо десятки в степени порядкового номера за минусом единицы, нужно использовать двойку — вот и всё!
Допустим число 110101 и мы хотим узнать, сколько это будет в десятичной системе счисления, для этого достаточно выполнить следующее преобразование:
1 * 25 * + 1 * 24 + 0 * 23 + 1 * 22 + 0 * 21 + 1 * 20 = 1 * 32 + 1 * 16 + 0 * 8 + 1 * 4 + 0 * 2 + 1 * 1 = 53
Итак, значение бинарного числа основывается на наличии битов 1 и их позиционном значении. Поэтому значение числа 11111111 в двоичной системе является:
1 + 2 + 4 + 8 +16 + 32 + 64 + 128 = 255
Кстати, это то же самое, что и 28 — 1.
Шестнадцатеричная система счисления
Шестнадцатеричная система счисления использует основание 16. Цифры в этой системе варьируются от 0 до 15. По соглашению, буквы от A до F используются для представления шестнадцатеричных цифр, соответствующих десятичным значениям с 10 по 15.
Шестнадцатеричные числа в вычислениях используются для сокращения длинных двоичных представлений. По сути, шестнадцатеричная система счисления представляет двоичные данные, деля каждый байт пополам и выражая значение каждого полубайта. В следующей таблице приведены десятичные, двоичные и шестнадцатеричные эквиваленты —
| Десятичное число | Двоичный вид | Шестнадцатеричный вид |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 10 | 2 |
| 3 | 11 | 3 |
| 4 | 100 | 4 |
| 5 | 101 | 5 |
| 6 | 110 | 6 |
| 7 | 111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| 10 | 1010 | A |
| 11 | 1011 | B |
| 12 | 1100 | C |
| 13 | 1101 | D |
| 14 | 1110 | E |
| 15 | 1111 | F |
Чтобы преобразовать двоичное число в его шестнадцатеричный эквивалент, разбейте его на группы по 4 последовательные группы в каждой, начиная справа, и запишите эти группы в соответствующие цифры шестнадцатеричного числа.
Пример — двоичное число 1000 1100 1101 0001 эквивалентно шестнадцатеричному — 8CD1
Чтобы преобразовать шестнадцатеричное число в двоичное, просто запишите каждую шестнадцатеричную цифру в её 4-значный двоичный эквивалент.
Пример — шестнадцатеричное число FAD8 эквивалентно двоичному — 1111 1010 1101 1000
Отрицательные двоичные числа
Компьютерные процессы действуют по своей логике и своим алгоритмам. И привычные нам операции вычитания, деления, умножения выполняются необычным для нас, но удобным для микропроцессора способом.
Удобством для арифметических действий в процессоре обусловлено то, как записываются отрицательные двоичные числа. Вы должны помнить из курса информатики, что в одном байте содержится 8 бит. Но старший бит используется для установки знака. Чтобы правильно прочесть число, а также правильно поменять его знак, нужно выполнять следующие правила:
Во-первых, нужно помнить, что если старшие биты (крайние слева), равны нулю, то их иногда не записывают. Например, восьмибитное число 10 (в десятичной системе счисления оно равно 2), также можно записать как 0000 0010. Обе эти записи означают число 2.
Если старший бит равен нулю, то это положительное число. Например, возьмём число 110. В десятичной системе счисления это 6. Данное число является положительным или отрицательным? На самом деле, однозначно на этот вопрос можно ответить только зная разрядность числа. Если это восьмиразрядное число, то его полная запись будет такой: 0000 0110. Как можно увидеть, старший бит равен нулю, следовательно, это положительное число.
Для трёхбитовых чисел было бы справедливо следующее:
| Десятичное значение |
Двоичное значение трёхбитового числа со знаком |
|---|---|
| 0 | 000 |
| 1 | 001 |
| 2 | 010 |
| 3 | 011 |
| -4 | 100 |
| -3 | 101 |
| -2 | 110 |
| -1 | 111 |
Как вы должны были понять после анализа предыдущей таблицы, для смены знака недостаточно просто поменять единицу на ноль — для преобразования числа в отрицательное, а также для чтения отрицательного числа существуют особые правила.
Отрицательные двоичные числа записываются без знака минус и для получения этого же числа со знаком минус (то есть для получения числа в Дополненном коде) нужно выполнить два действия:
- нужно переписать его полную форму с противоположным значением битов (то есть для единиц записываются нули, а для нулей записываются единицы)
- и затем добавить к этому числу 1.
Пример:
| Число 53 | 00110101 |
| Замена битов на противоположные | 11001010 |
| Добавляем 1 | 00000001 |
| Число -53 | 11001011 |
На русском языке такая форма записи называется Дополнительный код, в англоязычной литературе это называется Two's complement.
Примеры восьмибитного двоичного числа в Дополнительном коде (старший бит указывает на знак):
| Десятичное значение |
Двоичное значение трёхбитового числа со знаком (в представлении Дополнительный код) |
|---|---|
| 0 | 0000 0000 |
| 1 | 0000 0001 |
| 2 | 0000 0010 |
| 126 | 0111 1110 |
| 127 | 0111 1111 |
| −128 | 1000 0000 |
| −127 | 1000 0001 |
| −126 | 1000 0010 |
| −2 | 1111 1110 |
| −1 | 1111 1111 |
Ещё примеры:
|
Десятичное представление |
Двоичное представление (8 бит) (в виде Дополнительного кода) |
|---|---|
| 127 | 0111 1111 |
| 1 | 0000 0001 |
| 0 | 0000 0000 |
| -0 | — |
| -1 | 1111 1111 |
| -2 | 1111 1110 |
| -3 | 1111 1101 |
| -4 | 1111 1100 |
| -5 | 1111 1011 |
| -6 | 1111 1010 |
| -7 | 1111 1001 |
| -8 | 1111 1000 |
| -9 | 1111 0111 |
| -10 | 1111 0110 |
| -11 | 1111 0101 |
| -127 | 1000 0001 |
| -128 | 1000 0000 |
Числа в дополненном коде удобно применять для вычитания — это будет показано далее.
Для преобразования отрицательного числа, записанного в дополнительном коде, в положительное число, записанное в прямом коде, используется похожий алгоритм.
Рассмотрим пример с числом -5. Запись отрицательного восьмибитного числа:
1111 1011
Инвертируем все разряды отрицательного числа -5, получая таким образом:
0000 0100
Добавив к результату 1 получим положительное число 5 в прямом коде:
0000 0101
И проверим, сложив с дополнительным кодом
0000 0101 + 1111 1011 = 1 0000 0000, десятый разряд выбрасывается, то есть получается 0000 0000, то есть 0. Следовательно, преобразование выполнено правильно, так как 5 + (-5) = 0.
Двоичная арифметика
Следующая таблица иллюстрирует четыре простых правила для двоичного сложения:
| (i) | (ii) | (iii) | (iv) |
|---|---|---|---|
| 1 | |||
| 0 | 1 | 1 | 1 |
| +0 | +0 | +1 | +1 |
| =0 | =1 | =10 | =11 |
Эту таблицу нужно читать по столбцам сверху вниз. В первом столбце складываются 0 и 0 — в результате получается 0. Во втором примере складываются 1 и 0 (или 0 и 1 — без разницы), в результате получается 1. В третьем столбце складываются две единицы — в результате в текущей позиции получается 0, но на одну позицию влево добавляется единица. Если в этой позиции уже есть единица — то применяется это же правило, то есть в позиции пишется 0, и 1 передаётся влево. В четвёртом примере складываются три единицы — в результате, в текущей позиции записывается 1, и ещё одна 1 передаётся влево.
Пример:
| Десятичные | Двоичные |
|---|---|
| 60 | 00111100 |
| +42 | 00101010 |
| 102 | 01100110 |
Рассмотрим, как делается вычитание.
Для вычитания число, которое вычитается, записывается в форме Дополнительного кода, а затем эти два числа складываются.
Пример: Вычесть 42 из 53
| Число 53 | 00110101 |
| Число 42 | 00101010 |
| Инвертируем биты 42 | 11010101 |
| Добавляем 1 | 00000001 |
| Число -42 | 11010110 |
| Выполняем операцию: 53 — 42 = 11 |
00110101 + 11010110 = |
Бит который вызывает переполнение — крайней левый, девятый по счёту, просто отбрасывается.
Адресация данных в памяти
Процесс, посредством которого процессор управляет выполнением инструкций, называется циклом fetch-decode-execute (выборки-декодирования-выполнения) или циклом выполнения (execution cycle). Он состоит из трёх непрерывных шагов —
- Извлечение инструкции из памяти
- Расшифровка или идентификация инструкции
- Выполнение инструкции
Процессор может одновременно обращаться к одному или нескольким байтам памяти. Давайте рассмотрим шестнадцатеричное число 0725H (буква H означает, что перед нами шестнадцатеричное число). Для этого числа потребуется два байта памяти. Байт старшего разряда или старший значащий байт — 07, а младший байт — 25.
Процессор хранит данные в последовательности обратного байта, то есть байт младшего разряда хранится в низком адресе памяти и байт старшего разряда в старшем адресе памяти. Таким образом, если процессор переносит значение 0725H из регистра в память, он сначала перенесёт 25 на нижний адрес памяти и 07 на следующий адрес памяти.
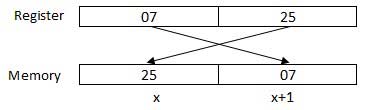
Когда процессор получает числовые данные из памяти для регистрации, он снова переворачивает байты. Есть два вида адресов памяти:
- Абсолютный адрес — прямая ссылка на конкретное место.
- Адрес сегмента (или смещение) — начальный адрес сегмента памяти со значением смещения.
Настройка рабочего окружения для Ассемблер
Настройка локального рабочего окружения
Язык ассемблера зависит от набора команд и архитектуры процессора. В этом руководстве мы сосредоточимся на процессорах Intel-32, таких как Pentium. Чтобы следовать этому уроку, вам понадобится:
- ПК IBM или любой другой совместимый компьютер
- Копия операционной системы Linux
- Копия программы ассемблера NASM
Есть много хороших ассемблерных программ, таких как:
- Microsoft Assembler (MASM)
- Borland Turbo Assembler (TASM)
- GNU ассемблер (GAS)
Мы будем использовать ассемблер NASM, так как он:
- Бесплатный
- Хорошо задокументированный — вы получите много информации в сети.
- Может использоваться как в Linux, так и в Windows.
Установка NASM
Если вы выбираете «Инструменты разработки» при установке Linux, вы можете установить NASM вместе с операционной системой Linux, и вам не нужно загружать и устанавливать его отдельно. Чтобы проверить, установлен ли у вас NASM, сделайте следующее:
Откройте терминал Linux.
Введите
whereis nasm
и нажмите клавишу ВВОД.
Если он уже установлен, появляется строка типа
nasm: /usr/bin/nasm /usr/share/man/man1/nasm.1.gz
В противном случае вы увидите просто
nasm:
значит вам нужно установить NASM.
NASM должен присутствовать в стандартных репозиториях, поэтому попробуйте поискать там этот пакет и установить его.
Например, для установки в Debian, Ubuntu, Linux Mint, Kali Linux и их производные выполните:
sudo apt install nasm
Для установки в Arch Linux, BlackArch и их производные выполните:
sudo pacman -S nasm
Чтобы установить NASM из исходного кода, сделайте следующее:
Проверьте веб-сайт ассемблера (NASM) на последнюю версию.
Загрузите исходный архив Linux nasm-X.XX.ta.gz, где X.XX — номер версии NASM в архиве.
Распакуйте архив в каталог, который создаст подкаталог nasm-X.XX.
Перейдите к nasm-X.XX
cd nasm-*
и введите
./configure
Этот скрипт оболочки найдёт лучший компилятор C для использования и сделает настройки в соответствии с Makefiles.
Введите
make
чтобы создать двоичные файлы nasm и ndisasm.
Введите
make install
чтобы установить nasm и ndisasm в /usr/local/bin и установить справочные страницы (man).
Это должно установить NASM в вашей системе. Кроме того, вы можете использовать RPM-дистрибутив для Fedora Linux. Эта версия проще в установке, просто дважды щёлкните файл RPM.
Основы синтаксиса Ассемблера
Программу на языке Ассемблер можно разделить на три раздела:
- Раздел data
- Раздел bss
- Раздел text
Раздел data
Раздел data используется для объявления инициализированных данных или констант. Эти данные не изменяются во время выполнения. В этом разделе вы можете объявить различные постоянные значения, имена файлов или размер буфера и т. д.
Синтаксис объявления раздела data:
section.data
Раздел BSS
Секция bss используется для объявления переменных. Синтаксис объявления раздела bss:
section.bss
Раздел text
Раздел text используется для хранения самого кода. Этот раздел должен начинаться с объявления global _start, которое сообщает ядру, где начинается выполнение программы.
Синтаксис объявления раздела text:
section.text global _start _start:
Комментарии
Комментарий на ассемблере начинается с точки с запятой (;). Он может содержать любой печатный символ, включая пробел. Он может появиться в строке сам по себе, например:
; Эта программа отображает сообщение на экране
или в той же строке вместе с инструкцией, например:
add eax, ebx ; добавляет ebx к eax
Операторы Ассемблера
Программы на ассемблере состоят из трёх типов операторов:
- Исполняемые инструкции или инструкции,
- Директивы ассемблера или псевдооперации (pseudo-ops), и
- Макросы.
Исполняемые инструкции или просто инструкции говорят процессору, что делать. Каждая инструкция состоит из кода операции (opcode). Каждая исполняемая инструкция генерирует одну инструкцию на машинном языке.
Директивы ассемблера или псевдооперации говорят ассемблеру о различных аспектах процесса сборки. Они не являются исполняемыми и не генерируют инструкции машинного языка.
Макросы — это в основном механизм подстановки текста.
Синтаксис операторов ассемблера
Операторы языка ассемблера вводятся по одной инструкции в каждой строке. Каждое утверждение имеет следующий формат:
[label] мнемоника [операнды] [;комментарий]
Поля в квадратных скобках являются необязательными. Основная инструкция состоит из двух частей: первая — это имя инструкции (или мнемоника), которая должна быть выполнена, а вторая — операнды или параметры команды.
Ниже приведены некоторые примеры типичных операторов языка ассемблера.
INC COUNT ; Увеличить переменную памяти COUNT
MOV TOTAL, 48 ; Перемести значение 48 в
; переменную памяти TOTAL
ADD AH, BH ; Добавить содержимое регистра
; BH в регистр AH
AND MASK1, 128 ; Выполнить операцию AND на переменной
; MASK1 и 128
ADD MARKS, 10 ; Добавить 10 к переменной MARKS
MOV AL, 10 ; Перенести значение 10 в регистр AL
Программа Hello World на Ассамблере
Следующий код на ассемблере выводит на экран строку «Hello World»:
section .text global _start ;должно быть объявлено для линкера (linker) (ld) _start: ;показывает линкеру точку входа mov edx,len ;длина сообщения mov ecx,msg ;сообщение для записи mov ebx,1 ;файловый дескриптор (stdout - стандартный вывод) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data msg db 'Hello, world!', 0xa ;строка для печати len equ $ - msg ;длина строки
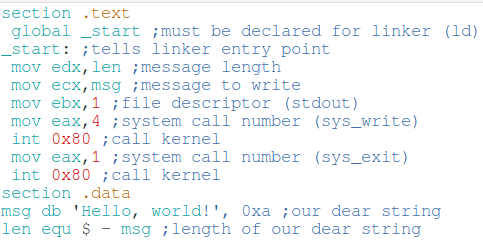
Когда приведённый выше код скомпилирован и выполнен, он даст следующий результат:
Hello, world!
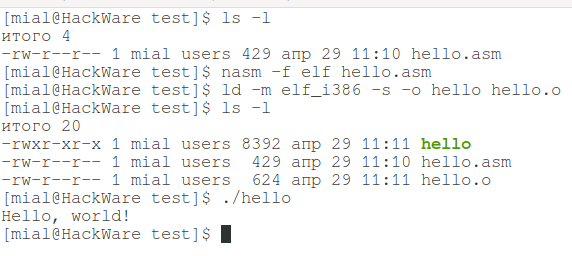
Компиляция и связывание (Linking) программы на Ассемблере в NASM
Убедитесь, что вы установили путь до исполнимых файлов nasm и ld в вашей переменной окружения PATH (в Linux это уже сделано). Теперь пройдите следующие шаги для компиляции и связывания приведённой выше программы:
- Наберите приведённый выше код используя текстовый редактор и сохраните как hello.asm.
- Убедитесь, что вы в той же самой директории, где вы сохранили hello.asm.
- Для сборки вашей программы выполните:
nasm -f elf hello.asm
- Если в коде присутствуют какие-либо ошибки, то на этом этапе вам будет выведено сообщение о них. Если ошибок нет, то будет создан объектный файл вашей программы с именем hello.o.
- Для связывания объектного файла и создания исполнимого файла с именем hello выполните:
ld -m elf_i386 -s -o hello hello.o
Выполните программу набрав:
./hello
Если вы всё сделали правильно, то она отобразит на экране 'Hello, world!'.
Возможно, вас интересует, что такое связывание (Linking) и зачем оно требуется после сборки программы. Если коротко, то на этом этапе объектные файлы (если их несколько) собираются в один исполнимый файл, также благодаря этому процессу исполнимый файл теперь может использовать библиотеки. Линкеру указывается (обычно) целевой исполнимый формат. Если совсем коротко — это просто нужно. Я не буду в этом базовом курсе по ассемблеру останавливаться на этом более подробно — если вас интересует эта тема, то вы всегда сможете найти по ней дополнительную информацию в Интернете.
Ассемблер: сегменты памяти
Мы уже рассмотрели три раздела программы на ассемблере. Эти разделы также представляют различные сегменты памяти.
Обратите внимание, что если вы замените ключевое слово section на слово segment, вы получите тот же самый результат. Попробуйте этот код:
segment .text ;сегмент кода global _start ;нужно объявить для линкера _start: ;указать линкеру точку вхоода mov edx,len ;длина сообщения mov ecx,msg ;сообщение для записи mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра segment .data ;сегмент данных msg db 'Hello, world!',0xa ;наша замечательная строка len equ $ - msg ;длина нашей замечательной строки
После компиляции и выполнения вышеприведённого кода он даст следующий результат:
Hello, world!
Сегменты памяти
Модель сегментированной памяти делит системную память на группы независимых сегментов, на которые ссылаются указатели, расположенные в регистрах сегментов. Каждый сегмент используется для хранения данных определённого типа. Один сегмент используется для хранения кодов команд, другой — для хранения элементов данных, а третий — для программного стека.
В свете вышеизложенного мы можем выделить различные сегменты памяти, такие как:
-
Сегмент Data. Он представлен разделом .data и .bss. Раздел .data используется для объявления области памяти, где хранятся элементы данных для программы. Этот раздел не может быть расширен после объявления элементов данных, и он остаётся статическим во всей программе.
Раздел .bss также является разделом статической памяти, который содержит буферы для данных, которые будут объявлены позже в программе. Эта буферная память заполнена нулями. - Сегмент Code. Он представлен разделом .text. Он определяет область в памяти, в которой хранятся коды команд. Это также фиксированная зона.
- Stack — этот сегмент содержит значения данных, передаваемые функциям и процедурам в программе.
Ассемблер: регистры (Registers)
Операции процессора в основном связаны с обработкой данных. Эти данные могут быть сохранены в памяти и доступны оттуда. Однако чтение данных из памяти и её сохранение в памяти замедляет процессор, поскольку включает сложные процессы отправки запроса данных через шину управления и в блок хранения памяти и получения данных по одному и тому же каналу.
Для ускорения работы процессора процессор включает в себя несколько мест хранения внутренней памяти, называемых регистрами (registers).
Регистры хранят элементы данных для обработки без необходимости доступа к памяти. Ограниченное количество регистров встроено в чип процессора.
Регистры процессора
В архитектуре IA-32 имеется десять 32-разрядных и шесть 16-разрядных процессорных регистров. Регистры сгруппированы в три категории:
- Общие регистры,
- Регистры управления и
- Сегментные регистры.
Общие регистры далее делятся на следующие группы:
- Регистры данных,
- Регистры указателя и
- Индексные регистры.
Регистры данных
Четыре 32-битных регистра данных используются для арифметических, логических и других операций. Эти 32-битные регистры можно использовать тремя способами:
- Как полные 32-битные регистры данных: EAX, EBX, ECX, EDX.
- Нижние половины 32-битных регистров могут использоваться как четыре 16-битных регистра данных: AX, BX, CX и DX.
- Нижняя и верхняя половины вышеупомянутых четырёх 16-битных регистров могут использоваться как восемь 8-битных регистров данных: AH, AL, BH, BL, CH, CL, DH и DL.
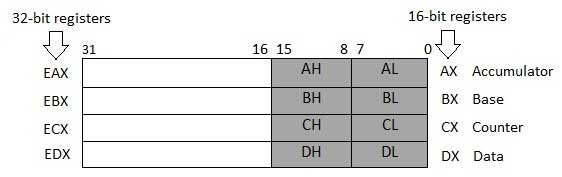
Некоторые из этих регистров данных имеют конкретное применение в арифметических операциях.
AX — основной аккумулятор; он используется во вводе/выводе и большинстве арифметических инструкций. Например, в операции умножения один операнд сохраняется в регистре EAX или AX или AL в соответствии с размером операнда.
BX известен как базовый регистр, поскольку его можно использовать при индексированной адресации.
CX известен как регистр подсчёта, так как регистры ECX, CX хранят счётчик циклов в итерационных операциях.
DX известен как регистр данных. Он также используется в операциях ввода/вывода. Он также используется с регистром AX вместе с DX для операций умножения и деления с большими значениями.
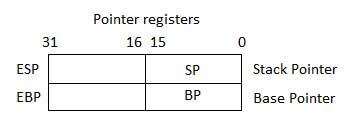
Регистры указателя
Регистры указателя являются 32-разрядными регистрами EIP, ESP и EBP и соответствующими 16-разрядными правыми частями IP, SP и BP. Есть три категории регистров указателей:
- Указатель инструкций (IP) — 16-битный регистр IP хранит адрес смещения следующей команды, которая должна быть выполнена. IP вместе с регистром CS (как CS:IP) даёт полный адрес текущей инструкции в сегменте кода.
- Указатель стека (SP) — 16-разрядный регистр SP обеспечивает значение смещения в программном стеке. SP в сочетании с регистром SS (SS:SP) относится к текущей позиции данных или адреса в программном стеке.
- Базовый указатель (BP) — 16-битный регистр BP в основном помогает ссылаться на переменные параметра, передаваемые подпрограмме. Адрес в регистре SS объединяется со смещением в BP, чтобы получить местоположение параметра. BP также можно комбинировать с DI и SI в качестве базового регистра для специальной адресации.
Индексные регистры
32-разрядные индексные регистры ESI и EDI и их 16-разрядные крайние правые части. SI и DI, используются для индексированной адресации и иногда используются для сложения и вычитания. Есть два набора указателей индекса:
- Исходный индекс (SI) — используется в качестве исходного индекса для строковых операций.
- Указатель назначения (DI) — используется как указатель назначения для строковых операций.

Регистры управления
Регистр указателя 32-битной инструкции и регистр 32-битных флагов рассматриваются как регистры управления.
Многие инструкции включают сравнения и математические вычисления и изменяют состояние флагов, а некоторые другие условные инструкции проверяют значение этих флагов состояния, чтобы перенести поток управления в другое место.
Популярные биты флага:
- Флаг переполнения (OF) — указывает на переполнение старшего бита (крайнего левого бита) данных после арифметической операции со знаком.
- Флаг направления (DF) — определяет направление влево или вправо для перемещения или сравнения строковых данных. Когда значение DF равно 0, строковая операция принимает направление слева направо, а когда значение равно 1, строковая операция принимает направление справа налево.
- Флаг прерывания (IF) — определяет, будут ли игнорироваться или обрабатываться внешние прерывания, такие как ввод с клавиатуры и т. д. Он отключает внешнее прерывание, когда значение равно 0, и разрешает прерывания, когда установлено значение 1.
- Trap Flag (TF) — позволяет настроить работу процессора в одношаговом режиме. Программа DEBUG, которую мы использовали, устанавливает флаг прерывания, чтобы мы могли пошагово пройтись по инструкциям — по одной инструкции за раз.
- Флаг знака (SF) — показывает знак результата арифметической операции. Этот флаг устанавливается в соответствии со знаком элемента данных после арифметической операции. Знак указывается старшим левым битом. Положительный результат очищает значение SF до 0, а отрицательный результат устанавливает его в 1.
- Нулевой флаг (ZF) — указывает результат арифметической операции или операции сравнения. Ненулевой результат очищает нулевой флаг до 0, а нулевой результат устанавливает его в 1.
- Вспомогательный флаг переноса (AF) — содержит перенос с бита 3 на бит 4 после арифметической операции; используется для специализированной арифметики. AF устанавливается, когда 1-байтовая арифметическая операция вызывает перенос из бита 3 в бит 4.
- Флаг чётности (PF) — указывает общее количество 1-битов в результате, полученном в результате арифметической операции. Чётное число 1-бит очищает флаг чётности до 0, а нечётное число 1-битов устанавливает флаг чётности в 1.
- Флаг переноса (CF) — содержит перенос 0 или 1 из старшего бита (крайнего слева) после арифметической операции. Он также хранит содержимое последнего бита операции shift или rotate.
В следующей таблице указано положение битов флага в 16-битном регистре флагов:
| Флаг: | O | D | I | T | S | Z | A | P | C | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Номер бита: | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Сегментные регистры
Сегменты — это специальные области, определённые в программе для хранения данных, кода и стека. Есть три основных сегмента:
- Сегмент Code — содержит все инструкции, которые должны быть выполнены. 16-битный регистр сегмента кода или регистр CS хранит начальный адрес сегмента кода.
- Сегмент Data — содержит данные, константы и рабочие области. 16-битный регистр сегмента данных или регистр DS хранит начальный адрес сегмента данных.
- Сегмент Stack — содержит данные и адреса возврата процедур или подпрограмм. Он реализован в виде структуры данных стека. Регистр сегмента стека или регистр SS хранит начальный адрес стека.
Помимо регистров DS, CS и SS существуют и другие регистры дополнительных сегментов — ES (дополнительный сегмент), FS и GS, которые предоставляют дополнительные сегменты для хранения данных.
При программировании на ассемблере программе необходим доступ к ячейкам памяти. Все области памяти в сегменте относятся к начальному адресу сегмента. Сегмент начинается с адреса, равномерно делимого на 16 или в шестнадцатеричном виде числа 10. Таким образом, крайняя правая шестнадцатеричная цифра во всех таких адресах памяти равна 0, что обычно не сохраняется в регистрах сегментов.
Сегментные регистры хранят начальные адреса сегмента. Чтобы получить точное местоположение данных или инструкции в сегменте, требуется значение смещения (или смещение). Чтобы сослаться на любую ячейку памяти в сегменте, процессор объединяет адрес сегмента в регистре сегмента со значением смещения местоположения.
Пример
Посмотрите на следующую простую программу, чтобы понять использование регистров в программировании на Ассемблере. Эта программа отображает 9 звёзд на экране вместе с простым сообщением.
section .text global _start ;нужно указать для линкера (gcc) _start: ;говорит линкеру о точке входа mov edx,len ;длина сообщения mov ecx,msg ;сообщение для записи mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov edx,9 ;длина сообщения mov ecx,s2 ;сообщение для записи mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data msg db 'Сейчас покажем 9 звёзд',0xa ;сообщение len equ $ - msg ;длина сообщения s2 times 9 db '*'
После компиляции и выполнения эта программа выведет:
Сейчас покажем 9 звёзд *********

Ассемблер: Системные вызовы
Системные вызовы — это API для интерфейса между пространством пользователя и пространством ядра. Мы уже использовали системные вызовы sys_write и sys_exit для записи на экран и выхода из программы соответственно.
Системные вызовы Linux
Вы можете использовать системные вызовы Linux в ваших ассемблерных программах. Для использования системных вызовов Linux в вашей программе необходимо выполнить следующие шаги:
- Поместите номер системного вызова в регистр EAX.
- Сохраните аргументы системного вызова в регистрах EBX, ECX и т. д.
- Вызовите соответствующее прерывание (80h).
- Результат обычно возвращается в регистр EAX.
Существует шесть регистров, в которых хранятся аргументы используемого системного вызова. Это EBX, ECX, EDX, ESI, EDI и EBP. Эти регистры принимают последовательные аргументы, начиная с регистра EBX. Если существует более шести аргументов, ячейка памяти первого аргумента сохраняется в регистре EBX.
В следующем фрагменте кода показано использование системного вызова sys_exit:
mov eax,1 ; номер системного вызова (sys_exit) int 0x80 ; вызов ядра
В следующем фрагменте кода показано использование системного вызова sys_write:
mov edx,4 ; длина сообщения mov ecx,msg ; сообщение для записи mov ebx,1 ; файловый дескриптор (stdout) mov eax,4 ; номер системного вызова (sys_write) int 0x80 ; вызов ядра
Все системные вызовы перечислены в /usr/include/asm/unistd.h вместе с их номерами (значение, которое нужно указать в EAX перед вызовом int 80h). Точнее говоря, сейчас это файлы /usr/include/asm/unistd_32.h и /usr/include/asm/unistd_64.h.
Чтобы посмотреть содержимое файла /usr/include/asm/unistd_32.h:
cat /usr/include/asm/unistd_32.h
Начало этого файла:
#ifndef _ASM_X86_UNISTD_32_H #define _ASM_X86_UNISTD_32_H 1 #define __NR_restart_syscall 0 #define __NR_exit 1 #define __NR_fork 2 #define __NR_read 3 #define __NR_write 4 #define __NR_open 5 #define __NR_close 6 #define __NR_waitpid 7 #define __NR_creat 8 #define __NR_link 9 #define __NR_unlink 10 #define __NR_execve 11 #define __NR_chdir 12 #define __NR_time 13 #define __NR_mknod 14 #define __NR_chmod 15 #define __NR_lchown 16 #define __NR_break 17 #define __NR_oldstat 18 #define __NR_lseek 19 #define __NR_getpid 20 #define __NR_mount 21 #define __NR_umount 22 #define __NR_setuid 23 #define __NR_getuid 24 #define __NR_stime 25 #define __NR_ptrace 26 #define __NR_alarm 27 #define __NR_oldfstat 28 #define __NR_pause 29 #define __NR_utime 30 #define __NR_stty 31 #define __NR_gtty 32 #define __NR_access 33 #define __NR_nice 34 #define __NR_ftime 35 #define __NR_sync 36 #define __NR_kill 37 #define __NR_rename 38 #define __NR_mkdir 39 #define __NR_rmdir 40
Чтобы получить справку по системным вызовам:
man 2 syscalls
Чтобы получить справку по конкретному вызову, укажите вначале man 2, а затем название вызова. Например, чтобы узнать о вызове read:
man 2 read
Чтобы узнать о вызове mkdir:
man 2 mkdir
В следующей таблице приведены некоторые системные вызовы, используемые в этом руководстве:
| %eax | Имя | %ebx | %ecx | %edx | %esx | %edi |
|---|---|---|---|---|---|---|
| 1 | sys_exit | int (целое число) | — | — | — | — |
| 2 | sys_fork | struct pt_regs | — | — | — | — |
| 3 | sys_read | unsigned int (целое беззнаковое число) | char * | size_t | — | — |
| 4 | sys_write | unsigned int (целое беззнаковое число) | const char * | size_t | — | — |
| 5 | sys_open | const char * | int (целое число) | int (целое число) | — | — |
| 6 | sys_close | unsigned int (целое беззнаковое число) | — | — | — | — |
Пример
Следующий пример читает число с клавиатуры и отображает его на экране:
section .data ;Сегмент Data
userMsg db 'Пожалуйста, введите любые цифры: ' ;Просим пользователя ввести число
lenUserMsg equ $-userMsg ;Длина сообщения
dispMsg db 'Вы ввели: '
lenDispMsg equ $-dispMsg
section .bss ;Неинициализированные данные
num resb 5
section .text ;Сегмент Code
global _start
_start: ;Запрос пользователю на ввод
mov eax, 4
mov ebx, 1
mov ecx, userMsg
mov edx, lenUserMsg
int 80h
;Считываем и сохраняем пользовательский ввод
mov eax, 3
mov ebx, 2
mov ecx, num
mov edx, 5 ;5 байт (числовой, 1 для знака) этой информации
int 80h
;Вывод сообщения 'Вы ввели: '
mov eax, 4
mov ebx, 1
mov ecx, dispMsg
mov edx, lenDispMsg
int 80h
;Вывод введёного числа
mov eax, 4
mov ebx, 1
mov ecx, num
mov edx, 5
int 80h
; Код выхода
mov eax, 1
mov ebx, 0
int 80h
Скомпилированный и запущенный вышеприведённый код даёт следующий результат:
Пожалуйста, введите любые цифры: 34567 Вы ввели: 34567

Ассемблер: Режимы адресации
Большинство инструкций на ассемблере требуют обработки операндов. Адрес операнда предоставляет место, где хранятся данные, подлежащие обработке. Некоторые инструкции не требуют операнда, в то время как некоторые другие инструкции могут требовать один, два или три операнда.
Когда инструкции требуется два операнда, первый операнд обычно является пунктом назначения, который содержит данные в регистре или ячейке памяти, а второй операнд является источником. Источник содержит либо данные для доставки (немедленная адресация), либо адрес (в регистре или памяти) данных. Как правило, исходные данные остаются неизменными после операции.
Три основных режима адресации:
- Адресации на регистр
- Немедленная адресация
- Адресация на память
Адресации на регистр
В этом режиме адресации регистр содержит операнд. В зависимости от инструкции регистр может быть первым операндом, вторым операндом или обоими.
Например:
MOV DX, TAX_RATE ; Регистр в первом операнде MOV COUNT, CX ; Регистр во втором операнде MOV EAX, EBX ; Оба операнда в регистрах
Поскольку обработка данных между регистрами не требует памяти, она обеспечивает самую быструю обработку данных.
Немедленная адресация
Непосредственный операнд имеет постоянное значение или выражение. Когда инструкция с двумя операндами использует немедленную адресацию, первый операнд может быть регистром или ячейкой памяти, а второй операнд является непосредственной константой. Первый операнд определяет длину данных.
Например:
BYTE_VALUE DB 150 ; Определена величина byte WORD_VALUE DW 300 ; Определена величина word ADD BYTE_VALUE, 65 ; Добавлен немедленный операнд 65 MOV AX, 45H ; Немедленная константа 45H передана на AX
Адресация на память
Когда операнды указываются в режиме адресации на память, требуется прямой доступ к основной памяти, обычно к сегменту данных. Этот способ адресации приводит к более медленной обработке данных. Чтобы найти точное местоположение данных в памяти, нам нужен начальный адрес сегмента, который обычно находится в регистре DS, и значение смещения. Это значение смещения также называется действующим адресом (effective address).
В режиме прямой адресации значение смещения указывается непосредственно как часть инструкции, обычно указывается именем переменной. Ассемблер вычисляет значение смещения и поддерживает таблицу символов, в которой хранятся значения смещения всех переменных, используемых в программе.
При прямой адресации в памяти один из операндов ссылается на ячейку памяти, а другой операнд ссылается на регистр.
Например:
ADD BYTE_VALUE, DL ; Добавляет регистр в ячейку памяти MOV BX, WORD_VALUE ; Операнд из памяти добавлен в регистр
Прямая адресация со смещением
Этот режим адресации использует арифметические операторы для изменения адреса. Например, посмотрите на следующие определения, которые определяют таблицы данных:
BYTE_TABLE DB 14, 15, 22, 45 ; Таблица bytes WORD_TABLE DW 134, 345, 564, 123 ; Таблица words
Следующие операции обращаются к данным из таблиц в памяти в регистрах:
MOV CL, BYTE_TABLE[2] ; Получает 3й элемент BYTE_TABLE MOV CL, BYTE_TABLE + 2 ; Получает 3й элемент BYTE_TABLE MOV CX, WORD_TABLE[3] ; Получает 4й элемент WORD_TABLE MOV CX, WORD_TABLE + 3 ; Получает 4й элемент WORD_TABLE
Косвенная адресация на память
В этом режиме адресации используется способность компьютера Segment:Offset (Сегмент:Смещение). Обычно для этой цели используются базовые регистры EBX, EBP (или BX, BP) и регистры индекса (DI, SI), закодированные в квадратных скобках для ссылок на память.
Косвенная адресация обычно используется для переменных, содержащих несколько элементов, таких как массивы. Начальный адрес массива хранится, скажем, в регистре EBX.
В следующем фрагменте кода показано, как получить доступ к различным элементам переменной.
MY_TABLE TIMES 10 DW 0 ; Выделено 10 words (по 2 байта) каждое инициализировано на 0 MOV EBX, [MY_TABLE] ; Эффективный адрес MY_TABLE в EBX MOV [EBX], 110 ; MY_TABLE[0] = 110 ADD EBX, 2 ; EBX = EBX +2 MOV [EBX], 123 ; MY_TABLE[1] = 123
Инструкция MOV
Мы уже задействовали инструкцию MOV, которая используется для перемещения данных из одного пространства хранения в другое. Инструкция MOV принимает два операнда.
Синтаксис
Синтаксис инструкции MOV:
MOV пункт_назначения, источник
Инструкция MOV может иметь одну из следующих пяти форм:
MOV регистр, регистр MOV регистр, непосредственное_значение MOV память, непосредственное_значение MOV регистр, память MOV память, регистр
Пожалуйста, обратите внимание, что:
- Оба операнда в операции MOV должны быть одинакового размера
- Значение исходного операнда остаётся неизменным
Инструкция MOV порой вызывает двусмысленность. Например, посмотрите на утверждения:
MOV EBX, [MY_TABLE] ; Эффективный адрес MY_TABLE в EBX MOV [EBX], 110 ; MY_TABLE[0] = 110
Не ясно, хотите ли вы переместить байтовый эквивалент или словесный эквивалент числа 110. В таких случаях целесообразно использовать спецификатор типа (type specifier).
В следующей таблице приведены некоторые общие спецификаторы типов:
| Спецификатор типа | Байты |
|---|---|
| BYTE | 1 |
| WORD | 2 |
| DWORD | 4 |
| QWORD | 8 |
| TBYTE | 10 |
Пример
Следующая программа иллюстрирует некоторые из концепций, обсуждённых выше. Он сохраняет имя «Zara Ali» в разделе данных памяти, затем программно меняет его значение на другое имя «Nuha Ali» и отображает оба имени.
section .text
global _start ;нужно объявить для линкера
_start: ;указывает компоновщику точку входа
;пишем имя 'Zara Ali'
mov edx,9 ;длина сообщения
mov ecx, name ;сообщение для записи
mov ebx,1 ;файловый дескриптор (stdout)
mov eax,4 ;номер системного вызова (sys_write)
int 0x80 ;вызов ядра
mov [name], dword 'Nuha' ; изменение имени Nuha Ali
;запись имени 'Nuha Ali'
mov edx,8 ;длина сообщения
mov ecx,name ;сообщение для записи
mov ebx,1 ;файловый дескриптор (stdout)
mov eax,4 ;номер системного вызова (sys_write)
int 0x80 ;вызов ядра
mov eax,1 ;номер системного вызова (sys_exit)
int 0x80 ;вызов ядра
section .data
name db 'Zara Ali '
Когда приведённый выше код скомпилирован и выполнен, он даёт следующий результат:
Zara Ali Nuha Ali
Ассемблер: Переменные
NASM предоставляет различные директивы определения (define directives) для резервирования места для хранения переменных. Директива определения ассемблера используется для выделения пространства хранения. Его можно использовать для резервирования, а также для инициализации одного или нескольких байтов.
Выделение пространства хранения для инициализированных данных
Синтаксис для оператора распределения памяти для инициализированных данных:
[имя-переменной] директива-определения начальное-значение [,начальное-значение]...
Где имя-переменной — это идентификатор для каждого пространства хранения. Ассемблер связывает значение смещения для каждого имени переменной, определённого в сегменте данных.
Существует пять основных форм директивы определения:
| Директива | Цель | Размер хранения |
|---|---|---|
| DB | Определить Byte | выделяет 1 байт |
| DW | Определить Word | выделяет 2 байта |
| DD | Определить Doubleword | выделяет 4 байта |
| DQ | Определить Quadword | выделяет 8 байта |
| DT | Определить Ten Bytes | выделяет 10 байта |
Ниже приведены некоторые примеры использования директив определения.
choice DB 'y' number DW 12345 neg_number DW -12345 big_number DQ 123456789 real_number1 DD 1.234 real_number2 DQ 123.456
Пожалуйста, обратите внимание, что:
- Каждый байт символа хранится как его значение ASCII в шестнадцатеричном формате.
- Каждое десятичное значение автоматически преобразуется в его 16-разрядный двоичный эквивалент и сохраняется в виде шестнадцатеричного числа.
- Процессор использует little-endian порядок байтов.
- Отрицательные числа преобразуются в его представление Дополнительный код (рассмотрен выше).
- Короткие и длинные числа с плавающей запятой представлены с использованием 32 или 64 бит соответственно.
Следующая программа показывает использование директивы определения:
section .text global _start ;нужно указать для линкера (gcc) _start: ;показывает линкеру точку входоа mov edx,1 ;длина сообщения mov ecx,choice ;сообщение для записи mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data choice DB 'y'
Когда приведённый выше код компилируется и выполняется, он даёт следующий результат:
y
Выделение дискового пространства для неинициализированных данных
Директивы резервирования используются для запаса места для неинициализированных данных. Директивы резервирования принимают один операнд, который определяет количество единиц пространства, которое будет зарезервировано. Каждая директива определения имеет связанную директиву резервирования.
Существует пять основных форм директив резервирования:
| Директива | Цель |
|---|---|
| RESB | Зарезервировать Byte |
| RESW | Зарезервировать Word |
| RESD | Зарезервировать Doubleword |
| RESQ | Зарезервировать Quadword |
| REST | Зарезервировать 10 байт |
Множественность определений
Вы можете иметь несколько операторов определения данных в программе. Например:
choice DB 'Y' ;ASCII of y = 79H number1 DW 12345 ;12345D = 3039H number2 DD 12345679 ;123456789D = 75BCD15H
Ассемблер выделяет непрерывную память для нескольких определений переменных.
Множественность инициализаций
Директива TIMES позволяет выполнить несколько инициализаций к одному и тому же значению. Например, массив с именем marks размера 9 может быть определён и инициализирован на начальное значение ноль с помощью следующего оператора:
marks TIMES 9 DW 0
Директива TIMES полезна при определении массивов и таблиц. Следующая программа отображает 9 звёздочек на экране:
section .text global _start ;нужно указать для линкера (ld) _start: ;говорит линкеру точку входа mov edx,9 ;длина сообщения mov ecx, stars ;сообщение для записи mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data stars times 9 db '*'
Результат выполнения скомпилированной программы:
*********
Ассемблер: Константы
NASM предоставляет несколько директив, определяющих константы. Мы уже использовали директиву EQU в предыдущих разделах. Особое внимание мы уделим трём директивам:
- EQU
- %assign
- %define
Директива EQU
Директива EQU используется для определения констант. Синтаксис директивы EQU следующий:
ИМЯ_КОНСТАНТЫ EQU выражение
Например:
TOTAL_STUDENTS equ 50
Затем вы можете использовать это постоянное значение в вашем коде, например:
mov ecx, TOTAL_STUDENTS cmp eax, TOTAL_STUDENTS
Операндом оператора EQU может быть выражение:
LENGTH equ 20 WIDTH equ 10 AREA equ length * width
Приведённый фрагмент кода определит AREA как 200.
Пример
Следующий пример иллюстрирует использование директивы EQU:
SYS_EXIT equ 1 SYS_WRITE equ 4 STDIN equ 0 STDOUT equ 1 section .text global _start ;нужно продекларировать чтобы использовать gcc _start: ;говорит линкеру точку входа mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg1 mov edx, len1 int 0x80 mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg2 mov edx, len2 int 0x80 mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg3 mov edx, len3 int 0x80 mov eax,SYS_EXIT ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data msg1 db 'Привет, программист!',0xA,0xD len1 equ $ - msg1 msg2 db 'Добро пожаловать в мир', 0xA,0xD len2 equ $ - msg2 msg3 db 'Программирования на Ассемблере в Linux! ' len3 equ $- msg3
Скомпилированный и выполненный код даст следующие результаты:
Привет, программист! Добро пожаловать в мир Программирования на Ассемблере в Linux!
Кстати, в коде программы мы использовали 0xA,0xD в качестве части строк. Точнее говоря, в качестве окончания строк. Как можно догадаться, это шестнадцатеричные цифры. При выводе на экран эти шестнадцатеричные цифры трактуются как коды символов ASCII. То есть, чтобы понять их значение, нужно заглянуть в таблицу ASCII символов, например в статье «ASCII и шестнадцатеричное представление строк. Побитовые операции со строками».
Там мы можем найти, что 0xA (в той таблице он обозначен как 0A) и означает он перевод строки. Во многих языках программирования символ обозначается как «\n». Нажатие на клавишу ↵ Enter при выводе текста переводит строку.
Что касается 0xD (там в таблице он обозначен как 0D) и означает enter / carriage return — возврат каретки. Во многих языках программирования — символ «CR» обозначается как «\r».
Итак, если вы программируете на каком либо языке, то последовательность из двух шестнадцатеричных чисел 0xA,0xD, соответствует последовательности «\n\r», то есть, упрощённо говоря, это универсальный способ (чтобы срабатывал и в Linux, и в Windows) перейти на новую строку.
Директива %assign
По аналогии с директивой EQU, директива %assign может использоваться для определения числовых констант. Эта директива допускает переопределение. Например, вы можете определить постоянную TOTAL следующим образом:
%assign TOTAL 10
Позже в коде вы можете переопределить её так:
%assign TOTAL 20
Эта директива чувствительна к регистру.
Директива %define
Директива %define позволяет определять как числовые, так и строковые константы. Эта директива похожа на #define в C. Например, вы можете определить постоянную PTR так:
%define PTR [EBP+4]
Приведённый выше код заменяет PTR на [EBP+4].
Эта директива также допускает переопределение и учитывает регистр.
Ассемблер: Арифметические инструкции
Инструкция INC
Инструкция INC используется для увеличения операнда на единицу. Она работает с одним операндом, который может находиться либо в регистре, либо в памяти.
Синтаксис
Инструкция INC имеет следующий синтаксис:
INC операнд
Операндом может быть 8-битный, 16-битный или 32-битный операнд.
Примеры:
INC EBX ; Увеличивает 32-битный регистр INC DL ; Увеличивает 8-битный регистр INC [count] ; Увеличивает переменную count
Инструкция DEC
Инструкция DEC используется для уменьшения операнда на единицу. Она работает с одним операндом, который может находиться либо в регистре, либо в памяти.
Синтаксис
Инструкция DEC имеет следующий синтаксис:
DEC операнд
Операндом может быть 8-битный, 16-битный или 32-битный операнд.
Примеры:
segment .data count dw 0 value db 15 segment .text inc [count] dec [value] mov ebx, count inc word [ebx] mov esi, value dec byte [esi]
Инструкции ADD и SUB
Команды ADD и SUB используются для выполнения простого сложения/вычитания двоичных данных размером в byte, word и doubleword, т.е. для сложения или вычитания 8-битных, 16-битных или 32-битных операндов соответственно.
Синтаксис
Инструкции ADD и SUB имеют следующий синтаксис:
ADD первое_слагаемое, второе_слагаемое SUB уменьшаемое, вычитаемое
Инструкция ADD/SUB может выполняться между:
- Регистр к регистру
- Память к регистру
- Регистр к памяти
- Регистр к константе
- Память к константе
Однако, как и другие инструкции, операции с память-в-память невозможны с использованием инструкций ADD/SUB. Операция ADD или SUB устанавливает или очищает флаги переполнения (overflow) и переноса (carry).
Пример
В следующем примере программа спросит у пользователя две цифры; сохранит их в регистрах EAX и EBX, соответственно; сложит эти значения; сохранит результат в ячейке памяти «res» и, наконец, отобразит результат.
SYS_EXIT equ 1 SYS_READ equ 3 SYS_WRITE equ 4 STDIN equ 0 STDOUT equ 1 segment .data msg1 db "Введите цифру ", 0xA,0xD len1 equ $- msg1 msg2 db "Введите вторую цифру ", 0xA,0xD len2 equ $- msg2 msg3 db "Сумма равна: " len3 equ $- msg3 segment .bss num1 resb 2 num2 resb 2 res resb 1 section .text global _start ;нужно объявить для использования gcc _start: ;указания точки входа для компоновщика mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg1 mov edx, len1 int 0x80 mov eax, SYS_READ mov ebx, STDIN mov ecx, num1 mov edx, 2 int 0x80 mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg2 mov edx, len2 int 0x80 mov eax, SYS_READ mov ebx, STDIN mov ecx, num2 mov edx, 2 int 0x80 mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg3 mov edx, len3 int 0x80 ; перемещаем первую цифру в регистр eax, а вторую цифру в ebx ; и вычитаем ascii '0' для конвертации её в десятичную цифру mov eax, [num1] sub eax, '0' mov ebx, [num2] sub ebx, '0' ; складываем eax и ebx add eax, ebx ; добавляем '0' для конвертации суммы из десятичного числа в ASCII add eax, '0' ; сохраняем сумму в ячейке памяти res mov [res], eax ; печатаем сумму mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, res mov edx, 1 int 0x80 exit: mov eax, SYS_EXIT xor ebx, ebx int 0x80
Скомпилированный и выполненный код даст следующие результаты:
Введите цифру 6 Введите вторую цифру 3 Сумма равна: 9
Код программы сильно упрощается, если прописать значения переменных для арифметических действий прямо в самом коде:
section .text global _start ;нужно объявить для использования gcc _start: ;говорим линкеру о точке входа mov eax,'3' sub eax, '0' mov ebx, '4' sub ebx, '0' add eax, ebx add eax, '0' mov [sum], eax mov ecx,msg mov edx, len mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov ecx,sum mov edx, 1 mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data msg db "Сумма равна:", 0xA,0xD len equ $ - msg segment .bss sum resb 1
Результат выполнения этого кода:
Сумма равна: 7
Инструкции MUL/IMUL
Есть две инструкции для умножения двоичных данных. Инструкция MUL (Multiply) обрабатывает беззнаковые данные, а IMUL (Integer Multiply) обрабатывает данные со знаком. Обе инструкции влияют на флаг переноса и переполнения.
Синтаксис
Синтаксис для инструкций MUL/IMUL следующий:
MUL/IMUL умножитель
Множимое в обоих случаях будет в аккумуляторе, в зависимости от размера множимоего и умножителя, и результат умножения также сохраняется в двух регистрах в зависимости от размера операндов. Следующий раздел объясняет инструкции MUL в трёх разных случаях:
| Номер | Сценарии |
|---|---|
| 1 |
Когда перемножаются два байта Множимое находится в регистре AL, а множитель — это байт в памяти или в другом регистре. Результат произведения находится в AX. Старшие 8 битов произведения хранятся в AH, а младшие 8 битов хранятся в AL.
|
| 2 |
Когда умножаются два значения word Множимое должно быть в регистре AX, а множитель — это word в памяти или в другом регистре. Например, для такой инструкции, как MUL DX, вы должны сохранить множитель в DX и множимое в AX. В результате получается двойное word, для которого понадобятся два регистра. Часть высшего порядка (крайняя слева) сохраняется в DX, а часть нижнего порядка (крайняя справа) сохраняется в AX.
|
|
3 |
Когда умножаются два значения doubleword Когда умножаются два значения doubleword, множимое должно быть в EAX, а множитель — это значение doubleword, хранящееся в памяти или в другом регистре. Результат умножения сохраняется в регистрах EDX:EAX, то есть 32-разрядные старшие разряды сохраняются в регистре EDX, а 32-разрядные младшие разряды сохраняются в регистре EAX.
|
Пример
MOV AL, 10 MOV DL, 25 MUL DL ... MOV DL, 0FFH ; DL= -1 MOV AL, 0BEH ; AL = -66 IMUL DL
Пример
В следующем примере 3 умножается на 2 и отображается результат:
section .text global _start ;нужно объявить для использования gcc _start: ;показываем линкеру точку входа mov al,'3' sub al, '0' mov bl, '2' sub bl, '0' mul bl add al, '0' mov [res], al mov ecx,msg mov edx, len mov ebx,1 ;дескриптор файла (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov ecx,res mov edx, 1 mov ebx,1 ;дескриптор файла (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data msg db "Результатом является:", 0xA,0xD len equ $- msg segment .bss res resb 1
Результат выполнения программы:
Результатом является: 6
Инструкции DIV/IDIV
Операция деления генерирует два элемента — частное и остаток. В случае умножения переполнение не происходит, потому что регистры двойной длины используются для хранения результата. Однако в случае деления может произойти переполнение. Процессор генерирует прерывание, если происходит переполнение.
Инструкция DIV (Divide) используется для данных без знака, а IDIV (Integer Divide) используется для данных со знаком.
Синтаксис
Формат для инструкции DIV/IDIV:
DIV/IDIV делитель
Делимое находится в аккумуляторе. Обе инструкции могут работать с 8-битными, 16-битными или 32-битными операндами. Операция влияет на все шесть флагов состояния. Следующий раздел объясняет три случая деления с различным размером операнда:
| Номер | Сценарии |
|---|---|
| 1 |
Когда делитель равен 1 байту Предполагается, что делимое находится в регистре AX (16 бит). После деления частное переходит в регистр AL, а остаток — в регистр AH.
|
| 2 |
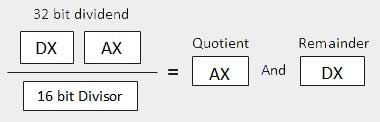
Когда делителем является 1 word Предполагается, что делимое имеют длину 32 бита и оно размещено в регистрах DX:AX. Старшие 16 битов находятся в DX, а младшие 16 битов — в AX. После деления 16-битное частное попадает в регистр AX, а 16-битное значение попадает в регистр DX.
|
|
3 |
Когда делитель doubleword Предполагается, что размер делимого составляет 64 бита и оно размещено в регистрах EDX:EAX. Старшие 32 бита находятся в EDX, а младшие 32 бита находятся в EAX. После деления 32-битное частное попадает в регистр EAX, а 32-битный остаток попадает в регистр EDX.
|


Пример
В следующем примере 8 делится на 2. Делимое 8 сохраняется в 16-битном регистре AX, а делитель 2 сохраняется в 8-битном регистре BL.
section .text global _start ;нужно продекларировать для gcc _start: ;показываем линкеру точку входа mov ax,'8' sub ax, '0' mov bl, '2' sub bl, '0' div bl add ax, '0' mov [res], ax mov ecx,msg mov edx, len mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov ecx,res mov edx, 1 mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data msg db "Результатом является:", 0xA,0xD len equ $- msg segment .bss res resb 1
Результат выполнения приведённого выше кода:
Результатом является: 4
Ассемблер: Логические инструкции
Набор команд процессора содержит инструкции логики AND, OR, XOR, TEST и NOT, которые проверяют, устанавливают и очищают биты в соответствии с потребностями программы.
Формат для этих инструкций:
| Номер | Инструкция | Формат |
|---|---|---|
| 1 | AND | AND операнд1, операнд2 |
| 2 | OR | OR операнд1, операнд2 |
| 3 | XOR | XOR операнд1, операнд2 |
| 4 | TEST | TEST операнд1, операнд2 |
| 5 | NOT | NOT операнд1 |
Первый операнд во всех случаях может быть либо в регистре, либо в памяти. Второй операнд может быть либо в регистре/памяти, либо в непосредственном (постоянном) значении. Однако операции память-и-память невозможны. Эти инструкции сравнивают или сопоставляют биты операндов и устанавливают флаги CF, OF, PF, SF и ZF.
Инструкция AND (И)
Инструкция AND используется для поддержки логических выражений путём выполнения побитовой операции AND. Побитовая операция AND возвращает 1, если совпадающие биты обоих операндов равны 1, в противном случае она возвращает 0. Например:
Операнд1: 0101
Операнд2: 0011
----------------------------
После AND -> Операнд1: 0001
Операция AND может использоваться для очистки одного или нескольких битов. Например, допустим, регистр BL содержит 0011 1010. Если вам нужно очистить старшие биты до нуля, то вы выполняете операцию AND этого регистра с 0FH.
AND BL, 0FH ; Это установит BL на 0000 1010
Давайте рассмотрим другой пример. Если вы хотите проверить, является ли данное число нечётным или чётным, простой тест будет проверять младший значащий бит числа. Если это 1, число нечётное, иначе число чётное.
Предполагая, что номер находится в регистре AL, мы можем написать:
AND AL, 01H ; Делаем AND с 0000 0001 JZ EVEN_NUMBER
Следующая программа иллюстрирует это.
Пример
section .text global _start ;должно быть объявлено для использования gcc _start: ;показываем линкеру точку входа mov ax, 8h ;устанавливаем 8 в ax and ax, 1 ;и делаем and ax с 1 jz evnn mov eax, 4 ;номер системного вызова (sys_write) mov ebx, 1 ;файловый дескриптор (stdout) mov ecx, odd_msg ;сообщение для записи mov edx, len2 ;длина сообщения int 0x80 ;вызов ядра jmp outprog evnn: mov ah, 09h mov eax, 4 ;номер системного вызова (sys_write) mov ebx, 1 ;файловый дескриптор (stdout) mov ecx, even_msg ;сообщение для записи mov edx, len1 ;длина сообщения int 0x80 ;вызов ядра outprog: mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data even_msg db 'Чётное число!' ;сообщение, которое говорит, что число чётное len1 equ $ - even_msg odd_msg db 'Нечётное число!' ;сообщение, которое говорит, что число нечётное len2 equ $ - odd_msg
Результат выполнения кода:
Чётное число!
Измените значение в регистре ax на нечётную цифру, к примеру:
mov ax, 9h ; устанавливаем 9 в ax
Программа будет отображать:
Нечётное число!
Точно так же очистить весь регистр вы можете сделав AND с 00H.
Инструкция OR
Инструкция OR (ИЛИ) используется для выполнения логической побитовой операции OR. Побитовый оператор OR возвращает 1, если совпадающие биты одного или обоих операндов равны единице. Возвращает 0, если оба бита равны нулю.
Например:
Операнд1: 0101
Операнд2: 0011
----------------------------
После OR -> Операнд1: 0111
Операция OR может использоваться для установки одного или нескольких битов. Например, предположим, что регистр AL содержит 0011 1010, вам нужно установить на единицы четыре младших бита, тогда вы можете сделать OR со значением 0000 1111, т.е.
Пример
В следующем примере демонстрируется инструкция OR. Давайте сохраним значения 5 и 3 в регистрах AL и BL, соответственно, затем
OR AL, BL
затем в регистре AL в результате выполнения операции OR получится 7
section .text
global _start ;нужно объявить для использования gcc
_start: ;показывает линкеру точку входа
mov al, 5 ;записываем 5 в al
mov bl, 3 ;записываем 3 в bl
or al, bl ;делаем or с регистрами al и bl, результатом должно быть 7
add al, byte '0' ;конвертируем десятичное число в ascii
mov [result], al
mov eax, 4
mov ebx, 1
mov ecx, result
mov edx, 1
int 0x80
outprog:
mov eax,1 ;номер системного вызова (sys_exit)
int 0x80 ;вызов ядра
section .bss
result resb 1
Результат работы программы:
7
Инструкция XOR
Инструкция XOR реализует побитовую операцию XOR. Операция XOR устанавливает результирующий бит в 1, если и только если биты из операндов отличаются. Если биты из операндов одинаковы (оба 0 или оба 1), результирующий бит сбрасывается в 0.
Например:
Операнд1: 0101
Операнд2: 0011
----------------------------
После XOR -> Операнд1: 0110
XOR операнд числа с самим собой меняет операнд на 0. Это используется для очистки регистра.
XOR EAX, EAX
Инструкция TEST
Инструкция TEST работает так же, как и операция AND, но в отличие от инструкции AND она не меняет первый операнд. Таким образом, если нам нужно проверить, является ли число в регистре чётным или нечётным, мы также можем сделать это, используя инструкцию TEST, не меняя исходного числа.
Инструкция NOT
Инструкция NOT реализует побитовую операцию NOT. Операция NOT меняет биты в операнде на противоположные. Операнд может быть либо в регистре, либо в памяти.
Например:
Операнд1: 0101 0011
После NOT -> Операнд1: 1010 1100
Ассемблер: Условия
Выполнение в зависимости от выполнения условия на ассемблере реализовано несколькими инструкциями зацикливания и ветвления. Эти инструкции могут изменить поток управления в программе. Условное исполнение рассматривается в двух сценариях:
| № | Инструкции условия |
|---|---|
| 1 |
Безусловный прыжок Он выполняется инструкцией JMP. Условное выполнение часто включает передачу управления на адрес инструкции, которая не следует за выполняемой в настоящее время инструкцией. Передача управления может быть прямой, чтобы выполнить новый набор инструкций, или обратной, чтобы повторно выполнить те же самые шаги. |
| 2 |
Условный переход Он выполняется с помощью набора инструкций перехода j<условие> и зависит от выполнения условия. Условные инструкции передают управление, прерывая последовательный поток, и делают это, изменяя значение смещения в IP. |
Давайте обсудим инструкцию CMP, прежде чем обсуждать условные инструкции.
Инструкция CMP
Инструкция CMP сравнивает два операнда. Обычно используется в условном исполнении. Эта инструкция в основном вычитает один операнд из другого для сравнения, равны ли операнды или нет. Она не мешает операндам назначения или источника. Она используется вместе с инструкцией условного перехода для принятия решения.
Синтаксис
CMP адресат, исходик
CMP сравнивает два числовых поля данных. Операнд-адресат может быть либо в регистре, либо в памяти. Исходным операндом могут быть постоянные (непосредственные) данные, регистр или память.
Пример
CMP DX, 00 ; Сравниваем значение DX с нулём JE L7 ; Если да, то переходим на метку L7 . . L7: ...
CMP часто используется для сравнения того, достигло ли значение счётчика количества раз, которое цикл должен быть выполнен. Рассмотрим следующее типичное условие:
INC EDX CMP EDX, 10 ; Сравниваем, достиг ли counter значения 10 JLE LP1 ; Если он меньше или равен 10, то переходим на LP1
Безусловный переход
Как упоминалось ранее, это выполняется инструкцией JMP. Условное выполнение часто включает передачу управления на адрес инструкции, которая не следует за выполняемой в настоящее время инструкцией. Передача управления может быть прямой, чтобы выполнить новый набор инструкций, или обратной, чтобы повторно выполнить те же самые шаги.
Синтаксис
Инструкция JMP предоставляет имя метки, куда поток управления передаётся немедленно. Синтаксис инструкции JMP:
JMP метка
Пример
Следующий фрагмент кода иллюстрирует инструкцию JMP:
MOV AX, 00 ; Инициализируем AX на 0 MOV BX, 00 ; Инициализируем BX на 0 MOV CX, 01 ; Инициализируем CX на 1 L20: ADD AX, 01 ; Увеличиваем AX ADD BX, AX ; Добавляем AX к BX SHL CX, 1 ; смещаем влево CX, это, в свою очередь, удваивает значение CX JMP L20 ; повторяем операторы
Условный переход
В условном переходе поток управления переносится в целевую инструкцию только если выполняется какое-либо указанное условие. Существует множество инструкций условного перехода в зависимости от состояния и данных.
Ниже приведены инструкции условного перехода, используемые для данных со знаком, используемых для арифметических операций.
| Инструкция | Описание | Тестируемые флаги |
|---|---|---|
| JE/JZ | Jump Equal or Jump Zero (равно или ноль) | ZF |
| JNE/JNZ | Jump not Equal or Jump Not Zero (не равно или не ноль) | ZF |
| JG/JNLE | Jump Greater or Jump Not Less/Equal (больше или не меньше/равно) | OF, SF, ZF |
| JGE/JNL | Jump Greater/Equal or Jump Not Less (больше/равно или не меньше) | OF, SF |
| JL/JNGE | Jump Less or Jump Not Greater/Equal (меньше или не больше/равно) | OF, SF |
| JLE/JNG | Jump Less/Equal or Jump Not Greater (меньше/равно или не больше) | OF, SF, ZF |
Ниже приведены инструкции условного перехода, используемые для данных без знака, используемых для логических операций.
| Инструкция | Описание | Тестируемые флаги |
|---|---|---|
| JE/JZ | Jump Equal или Jump Zero (равно или ноль) | ZF |
| JNE/JNZ | Jump not Equal или Jump Not Zero (не равно или не ноль) | ZF |
| JA/JNBE | Jump Above или Jump Not Below/Equal (больше или не меньше/равно) | CF, ZF |
| JAE/JNB | Jump Above/Equal или Jump Not Below (больше/равно или не меньше) | CF |
| JB/JNAE | Jump Below или Jump Not Above/Equal (меньше или не больше/равно) | CF |
| JBE/JNA | Jump Below/Equal или Jump Not Above (меньше/равно или не больше) | AF, CF |
Следующие инструкции условного перехода имеют специальное использование и проверяют значение флагов:
| Инструкция | Описание | Тестируемый флаг |
|---|---|---|
| JXCZ | Переход если CX равен нулю | нет |
| JC | Переход если Перенос | CF |
| JNC | Переход если нет Переноса | CF |
| JO | Переход если переполнение | OF |
| JNO | Переход если нет переполнения | OF |
| JP/JPE | Переход при наличии чётности | PF |
| JNP/JPO | Переход при отсутствии чётности | PF |
| JS | Переход при наличии знака (отрицательная величина) | SF |
| JNS | Переход при отсутствии знака (положительная величина) | SF |
Синтаксис для набора инструкций J<условие>:
Пример:
CMP AL, BL JE EQUAL CMP AL, BH JE EQUAL CMP AL, CL JE EQUAL NON_EQUAL: ... EQUAL: ...
Пример
Следующая программа отображает наибольшую из трёх переменных. Переменные являются двузначными переменными. Три переменные num1, num2 и num3 имеют значения 47, 22 и 31 соответственно:
section .text
global _start ;нужно объявить для использования gcc
_start: ;говорим линкеру о точке вхоода
mov ecx, [num1]
cmp ecx, [num2]
jg check_third_num
mov ecx, [num2]
check_third_num:
cmp ecx, [num3]
jg _exit
mov ecx, [num3]
_exit:
mov [largest], ecx
mov ecx,msg
mov edx, len
mov ebx,1 ;файловый дескриптор (stdout)
mov eax,4 ;номер системного вызова (sys_write)
int 0x80 ;вызов ядра
mov ecx,largest
mov edx, 2
mov ebx,1 ;файловый дескриптор (stdout)
mov eax,4 ;номер системного вызова (sys_write)
int 0x80 ;вызов ядра
mov eax, 1
int 80h
section .data
msg db "Самым большим числом является: ", 0xA,0xD
len equ $- msg
num1 dd '47'
num2 dd '22'
num3 dd '31'
segment .bss
largest resb 2
Результат работы программы:
Самым большим числом является: 47
Ассемблер: Петли
Инструкция JMP может использоваться для реализации циклов. Например, следующий фрагмент кода может использоваться для выполнения тела цикла 10 раз.
MOV CL, 10 L1: <LOOP-BODY> DEC CL JNZ L1
Набор инструкций процессора, однако, включает в себя группу команд цикла для реализации итерации. Основная инструкция LOOP имеет следующий синтаксис:
LOOP label
Где label — метка цели, которая идентифицирует целевую инструкцию, как в инструкциях перехода. Инструкция LOOP предполагает, что регистр ECX содержит количество циклов. Когда инструкция цикла выполняется, регистр ECX уменьшается, и управление переходит к метке назначения, пока значение регистра ECX, то есть счётчик не достигнет нуля.
Приведённый выше фрагмент кода может быть записан как:
mov ECX,10 l1: <loop body> loop l1
Пример
Следующая программа печатает цифры от 1 до 9 на экране:
section .text global _start ;нужно декларировать для использования gcc _start: ;показываем линкеру точку входа mov ecx,10 mov eax, '1' l1: mov [num], eax mov eax, 4 mov ebx, 1 push ecx mov ecx, num mov edx, 1 int 0x80 mov eax, [num] sub eax, '0' inc eax add eax, '0' pop ecx loop l1 mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .bss num resb 1
Когда приведённый выше код скомпилирован и выполнен, он даёт следующий результат:
123456789:
Ассемблер: Числа
Числовые данные обычно представлены в двоичной системе. Арифметические инструкции работают с двоичными данными. Когда числа отображаются на экране или вводятся с клавиатуры, они имеют форму ASCII (смотрите также ASCII и шестнадцатеричное представление строк. Побитовые операции со строками).
До сих пор мы преобразовывали эти входные данные в форме ASCII в двоичные для арифметических вычислений и преобразовывали результат обратно в ASCII. Следующий код показывает это:
section .text global _start ;нужно декларировать для использования gcc _start: ;показываем линкеру точку входа mov eax,'3' sub eax, '0' mov ebx, '4' sub ebx, '0' add eax, ebx add eax, '0' mov [sum], eax mov ecx,msg mov edx, len mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov ecx,sum mov edx, 1 mov ebx,1 ;айловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data msg db "Сумма равна:", 0xA,0xD len equ $ - msg segment .bss sum resb 1
После компиляции и выполнения приведённый выше код даёт следующий результат:
Сумма равна: 7
Однако такие преобразования имеют накладные расходы, и программирование на ассемблере позволяет более эффективно обрабатывать числа в двоичной форме. Десятичные числа могут быть представлены в двух формах:
- ASCII форма
- BCD или двоично-десятичная форма
ASCII представление
В представлении ASCII десятичные числа хранятся в виде строки символов ASCII. Например, десятичное значение 1234 сохраняется как:
31 32 33 34H
Где 31H — это значение ASCII для 1, 32H — это значение ASCII для 2 и т. д. Есть четыре инструкции для обработки чисел в представлении ASCII:
- AAA — ASCII настройка после добавления
- AAS — ASCII настройка после вычитания
- AAM — ASCII настройка после умножения
- AAD — ASCII настройка перед делением
Эти инструкции не принимают никаких операндов и предполагают, что требуемый операнд находится в регистре AL.
В следующем примере инструкция AAS используется для демонстрации концепции:
section .text global _start ;нужно декларировать для использования gcc _start: ;показываем линкеру точку входа sub ah, ah mov al, '9' sub al, '3' aas or al, 30h mov [res], ax mov edx,len ;длина сообщения mov ecx,msg ;сообщение для записи mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov edx,1 ;длина сообщения mov ecx,res ;сообщение для записи mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data msg db 'Результатом является:',0xa len equ $ - msg section .bss res resb 1
После компиляции и выполнения приведённый выше код даёт следующий результат:
Результатом является: 6
BCD представление
Существует два типа представления BCD:
- Распакованное BCD представление
- Упакованное представление BCD
В неупакованном представлении BCD каждый байт хранит двоичный эквивалент десятичной цифры. Например, число 1234 хранится как:
01 02 03 04H
Есть две инструкции для обработки этих чисел:
- AAM — ASCII настройка после умножения
- AAD — ASCII настройка перед делением
Четыре инструкции настройки ASCII, AAA, AAS, AAM и AAD, также могут использоваться с неупакованным представлением BCD. В упакованном представлении BCD каждая цифра сохраняется с использованием четырёх битов. Две десятичные цифры упакованы в байт. Например, число 1234 хранится как:
12 34H
Есть две инструкции для обработки этих чисел:
- DAA — десятичная корректировка после добавления
- DAS — десятичное значение после вычитания
В упакованном представлении BCD отсутствует поддержка умножения и деления.
Пример
Следующая программа складывает два пятизначных десятичных числа и отображает сумму. Он использует вышеуказанные концепции:
section .text global _start ;нужно декларировать для использования gcc _start: ;показываем линкеру точку входа mov esi, 4 ;pointing to the rightmost digit mov ecx, 5 ;количество цифр clc add_loop: mov al, [num1 + esi] adc al, [num2 + esi] aaa pushf or al, 30h popf mov [sum + esi], al dec esi loop add_loop mov edx,len ;длина сообщения mov ecx,msg ;сообщение для записи mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov edx,5 ;длина сообщения mov ecx,sum ;сообщение для записи mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data msg db 'Сумма равна:',0xa len equ $ - msg num1 db '12345' num2 db '23456' sum db ' '
Результат после компиляции и выполнения:
Сумма равна: 35801
Ассемблер: Строки
Мы уже использовали строки переменной длины в наших предыдущих примерах. Строки переменной длины могут содержать столько символов, сколько необходимо. Как правило, мы указываем длину строки одним из двух способов:
- Явно хранимая длина строки
- Использование символа стража
Мы можем хранить длину строки явно, используя символ счётчика местоположения $, который представляет текущее значение счётчика расположения. В следующем примере:
msg db 'Привет, мир!',0xa ;наша ненаглядная строка len equ $ - msg ;длина нашей ненаглядной строки
$ указывает на байт после последнего символа строковой переменной msg. Следовательно, $ — msg даёт длину строки. Мы также можем написать
msg db 'Hello, world!',0xa ;наша ненаглядная строка len equ 13 ;длина нашей ненаглядной строки
В качестве альтернативы, вы можете хранить строки с последующим символом стража, чтобы разделить строку, вместо того, чтобы явно хранить длину строки. Страдный символ должен быть специальным символом, который не появляется в строке.
Например:
message DB 'I am loving it!', 0
Строковые инструкции
Каждая строковая инструкция может требовать исходного операнда, целевого операнда или обоих. Для 32-битных сегментов строковые инструкции используют регистры ESI и EDI для указания на операнды источника и назначения соответственно.
Однако для 16-битных сегментов регистры SI и DI используются для указания на источник и пункт назначения соответственно.
Существует пять основных инструкций для обработки строк, а именно:
- MOVS — эта инструкция перемещает 1 байт, слово или двойное слово данных из ячейки памяти в другую.
- LODS — эта инструкция загружается из памяти. Если операнд имеет один байт, он загружается в регистр AL, если операнд — одно слово, он загружается в регистр AX, а двойное слово загружается в регистр EAX.
- STOS — эта инструкция сохраняет данные из регистра (AL, AX или EAX) в памяти.
- CMPS — эта инструкция сравнивает два элемента данных в памяти. Данные могут иметь размер в байтах, слово или двойное слово.
- SCAS — эта инструкция сравнивает содержимое регистра (AL, AX или EAX) с содержимым элемента в памяти.
Каждая из вышеприведённых инструкций имеет версию байта, слова и двойного слова, а строковые инструкции могут повторяться с использованием префикса повторения.
В этих инструкциях используются пары регистров ES:DI и DS:SI, где регистры DI и SI содержат действительные адреса смещения, которые относятся к байтам, хранящимся в памяти. SI обычно ассоциируется с DS (сегмент данных), а DI всегда ассоциируется с ES (дополнительный сегмент).
Регистры DS:SI (или ESI) и ES:DI (или EDI) указывают на операнды источника и назначения соответственно. Предполагается, что в памяти операндом-источником является DS:SI (или ESI), а операндом-адресатом — ES:DI (или EDI).
Для 16-битных адресов используются регистры SI и DI, а для 32-битных адресов используются регистры ESI и EDI.
В следующей таблице представлены различные версии строковых инструкций и предполагаемое пространство операндов.
| Основная инструкция | Операнды в | Операция с байтом | Операция с Word | Операция с Double |
|---|---|---|---|---|
| MOVS | ES:DI, DS:SI | MOVSB | MOVSW | MOVSD |
| LODS | AX, DS:SI | LODSB | LODSW | LODSD |
| STOS | ES:DI, AX | STOSB | STOSW | STOSD |
| CMPS | DS:SI, ES: DI | CMPSB | CMPSW | CMPSD |
| SCAS | ES:DI, AX | SCASB | SCASW | SCASD |
Префиксы повторения
Префикс REP, если он установлен перед строковой инструкцией, например — REP MOVSB, вызывает повторение инструкции на основе счётчика, размещённого в регистре CX. REP выполняет инструкцию, уменьшает CX на 1 и проверяет, равен ли CX нулю. Он повторяет обработку инструкций, пока CX не станет равным нулю.
Флаг направления (DF) определяет направление операции.
- Используйте CLD (сбросить флаг направления, DF = 0), чтобы выполнить операцию слева направо.
- Используйте STD (Установить флаг направления, DF = 1), чтобы выполнить операцию справа налево.
Префикс REP также имеет следующие варианты:
- REP: Это безусловное повторение. Он повторяет операцию, пока CX не станет равным нулю.
- REPE или REPZ: это условное повторение. Он повторяет операцию, в то время как нулевой флаг обозначает равно/ноль. Он останавливается, когда ZF указывает не равно/ноль или когда CX равен нулю.
- REPNE или REPNZ: это также условное повторение. Он повторяет операцию, в то время как нулевой флаг указывает не равно/ноль. Он останавливается, когда ZF показывает равно/ноль или когда CX уменьшается до нуля.
Ассемблер: Массивы
Мы уже обсуждали, что директивы определения данных к ассемблеру используются для выделения памяти переменным. Переменная также может быть инициализирована с определенным значением. Инициализированное значение может быть указано в шестнадцатеричной, десятичной или двоичной форме.
Например, мы можем определить переменную word 'months' любым из следующих способов:
MONTHS DW 12 MONTHS DW 0CH MONTHS DW 0110B
Директивы определения данных также могут использоваться для определения одномерного массива. Определим одномерный массив чисел.
NUMBERS DW 34, 45, 56, 67, 75, 89
Вышеприведённое определение объявляет массив из шести слов (word), каждое из которых инициализируется числами 34, 45, 56, 67, 75, 89. Это выделяет 2×6 = 12 байтов последовательного пространства памяти. Символический адрес первого числа будет NUMBERS, а второго номера — NUMBERS + 2 и т. д.
Давайте рассмотрим другой пример. Вы можете определить массив с именем inventory размером 8 и инициализировать все значения с нуля следующим образом:
INVENTORY DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
Который может быть сокращён до:
INVENTORY DW 0, 0 , 0 , 0 , 0 , 0 , 0 , 0
Директива TIMES также может использоваться для нескольких инициализаций одного и того же значения. Используя TIMES, массив INVENTORY можно определить как:
INVENTORY TIMES 8 DW 0
Пример
В следующем примере демонстрируются вышеуказанные концепции, определяя массив из трёх элементов x, в котором хранятся три значения: 2, 3 и 4. Программа добавляет значения в массив и отображает сумму 9:
section .text global _start ;должно быть объявлено для линкера (ld) _start: mov eax,3 ;число байт для суммирование mov ebx,0 ;EBX будет хранить сумму mov ecx, x ;ECX будет указывать на текущий элемент для суммирования top: add ebx, [ecx] add ecx,1 ;передвинуть указатель на следующий элемент dec eax ;счётчик уменьшения (декремент) jnz top ;если счётчик не 0, тогда выполнить ещё раз done: add ebx, '0' mov [sum], ebx ;готово, сохранить результат в "sum" display: mov edx,1 ;длина сообщения mov ecx, sum ;сообщение для записи mov ebx, 1 ;файловый дескриптор (stdout) mov eax, 4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax, 1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра section .data global x x: db 2 db 4 db 3 sum: db 0
Результат после компиляции и выполнения приведённого выше кода:
9
Ассемблер: Процедуры
Процедуры или подпрограммы очень важны для ассемблера, так как программы на ассемблере, как правило, имеют большой размер. Процедуры идентифицируются по имени. После её названия описывается тело процедуры, которая выполняет чётко определённую работу. Конец процедуры указывается оператором ret (return, возврат).
Синтаксис
Ниже приведён синтаксис для определения процедуры:
имя_процедуры: тело процедуры ... ret
Процедура вызывается из другой функции с помощью инструкции CALL. Инструкция CALL должна иметь имя вызываемой процедуры в качестве аргумента, как показано ниже:
CALL имя_процедуры
Вызываемая процедура возвращает управление вызывающей процедуре с помощью инструкции RET.
Пример
Давайте напишем очень простую процедуру с именем sum, которая складывает переменные, хранящиеся в регистре ECX и EDX, и возвращает сумму в регистр EAX:
section .text global _start ;нужно продекларировать для использования gcc _start: ;показываем линкеру точку входа mov ecx,'4' sub ecx, '0' mov edx, '5' sub edx, '0' call sum ;вызываем процедуру sum mov [res], eax mov ecx, msg mov edx, len mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov ecx, res mov edx, 1 mov ebx, 1 ;файловый дескриптор (stdout) mov eax, 4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра mov eax,1 ;номер системного вызова (sys_exit) int 0x80 ;вызов ядра sum: mov eax, ecx add eax, edx add eax, '0' ret section .data msg db "Сумма равна:", 0xA,0xD len equ $- msg segment .bss res resb 1
Скомпилированный и выполненный код даст следующий результат:
Сумма равна: 9
Структура данных стеков
Стек представляет собой массив данных в виде массива в памяти, в котором данные могут храниться и удаляться из места, называемого «вершиной» стека. Данные, которые необходимо сохранить, «помещаются» в стек, а извлекаемые данные «выталкиваются» из стека. Стек — это структура данных LIFO, то есть данные, сохранённые первыми, извлекаются последними.
Язык ассемблера предоставляет две инструкции для операций со стеком: PUSH и POP. Эти инструкции имеют следующий синтаксис:
PUSH операнд POP адрес/регистр
Пространство памяти, зарезервированное в сегменте стека, используется для реализации стека. Регистры SS и ESP (или SP) используются для реализации стека. На вершину стека, которая указывает на последний элемент данных, вставленный в стек, указывает регистр SS:ESP, где регистр SS указывает на начало сегмента стека, а SP (или ESP) даёт смещение в сегмент стека.
Реализация стека имеет следующие характеристики:
- В стек могут быть сохранены только word или doubleword, но не byte.
- Стек растёт в обратном направлении, то есть в направлении меньшего адреса памяти
- Вершина стека указывает на последний элемент, вставленный в стек; он указывает на младший байт последнего вставленного word.
Для хранения данных регистров в стеке, он может использоваться следующим образом:
; Сохраняем значение регистров AX и BX в стек PUSH AX PUSH BX ; Используем регистры для других целей MOV AX, VALUE1 MOV BX, VALUE2 ... MOV VALUE1, AX MOV VALUE2, BX ; Восстанавливаем исходные значения POP BX POP AX
Пример
Следующая программа отображает весь набор символов ASCII. Основная программа вызывает процедуру с именем display, которая отображает набор символов ASCII.
section .text global _start ;нужно продекларировать для использования gcc _start: ;говорим линкеру точку входа call display mov eax,1 ;номер системного выхова (sys_exit) int 0x80 ;выхов ядра display: mov ecx, 256 next: push ecx mov eax, 4 mov ebx, 1 mov ecx, achar mov edx, 1 int 80h pop ecx mov dx, [achar] cmp byte [achar], 0dh inc byte [achar] loop next ret section .data achar db '0'
Приведённый выше код после компиляции и выполнения даст следующий результат:
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~��������������������������������������������������������������������������������������������������������������������������������
�
Ассемблер: Рекурсия
Рекурсивная процедура — это та, которая вызывает сама себя. Существует два вида рекурсии: прямая и косвенная. При прямой рекурсии процедура вызывает себя, а при косвенной рекурсии первая процедура вызывает вторую процедуру, которая, в свою очередь, вызывает первую процедуру.
Рекурсию можно наблюдать в многочисленных математических алгоритмах. Например, рассмотрим случай вычисления факториала числа. Факториал числа задаётся уравнением:
Fact (n) = n * fact (n-1) for n > 0
Например: факториал 5 равен 1 x 2 x 3 x 4 x 5 = 5 x факториал 4, и это может быть хорошим примером демонстрации рекурсивной процедуры. Каждый рекурсивный алгоритм должен иметь конечное условие, то есть рекурсивный вызов программы должен быть остановлен при выполнении условия. В случае алгоритма факториала конечное условие достигается, когда n равно 0.
Следующая программа показывает, как факториал числа n реализован на ассемблере. Для простоты программы мы вычислим факториал 3.
section .text
global _start ;нужно декларировать для использования gcc
_start: ;говорим линкеру точку входа
mov bx, 3 ;устанавливаем число для вычисления факториала 3
call proc_fact
add ax, 30h
mov [fact], ax
mov edx,len ;длина сообщения
mov ecx,msg ;сообщение для записи
mov ebx,1 ;файловый дескриптор (stdout)
mov eax,4 ;номер системного вызова (sys_write)
int 0x80 ;вызов ядра
mov edx,1 ;длина сообщения
mov ecx,fact ;сообщение для записи
mov ebx,1 ;файловый дескриптор (stdout)
mov eax,4 ;номер системного вызова (sys_write)
int 0x80 ;вызов ядра
mov eax,1 ;номер системного вызова (sys_exit)
int 0x80 ;вызов ядра
proc_fact:
cmp bl, 1
jg do_calculation
mov ax, 1
ret
do_calculation:
dec bl
call proc_fact
inc bl
mul bl ;ax = al * bl
ret
section .data
msg db 'Факториал 3 равен:',0xa
len equ $ - msg
section .bss
fact resb 1
Скомпилированный и выполненный вышеприведённый код даст следующий результат:
Факториал 3 равен: 6
Ассемблер: Макросы
Написание макроса — это ещё один способ обеспечения модульного программирования на ассемблере.
Макрос — это последовательность инструкций, которой присвоено имя, и которая может использоваться в любом месте программы.
В NASM макросы определяются с помощью директив %macro и %endmacro.
Макрос начинается с директивы %macro и заканчивается директивой %endmacro.
Синтаксис для определения макроса:
%macro имя_макроса число_параметров <тело макроса> %endmacro
Макрос вызывается с использованием имени макроса вместе с необходимыми параметрами. Когда вам нужно многократно использовать некоторую последовательность инструкций в программе, вы можете поместить эти инструкции в макрос и использовать их вместо того, чтобы писать инструкции постоянно.
Например, очень распространённая потребность в программах заключается в написании строки символов на экране. Для отображения строки символов вам понадобится следующая последовательность инструкций:
mov edx,len ;длина сообщения mov ecx,msg ;сообщение для записи mov ebx,1 ;файловый дескриптор (stdout) mov eax,4 ;номер системного вызова (sys_write) int 0x80 ;вызов ядра
В приведённом выше примере отображения строки символов регистры EAX, EBX, ECX и EDX были использованы вызовом функции INT 80H. Таким образом, каждый раз, когда вам нужно отобразить что-то на экране, вам нужно сохранить эти регистры в стеке, вызвать INT 80H, а затем восстановить исходное значение регистров из стека. Таким образом, было бы полезно написать два макроса для сохранения и восстановления данных.
Мы заметили, что некоторые инструкции, такие как IMUL, IDIV, INT и т. д нуждаются в том, чтобы некоторая информация была сохранена в некоторых конкретных регистрах и даже возвращала значения в некоторых конкретных регистрах. Если программа уже использовала эти регистры для хранения важных данных, то существующие данные из этих регистров должны быть сохранены в стеке и восстановлены после выполнения инструкции.
Пример
Следующий пример показывает создание и использование макросов:
; Макрос с двумя параметрами
; реализует системный вызов write (вывод на экран)
%macro write_string 2
mov eax, 4
mov ebx, 1
mov ecx, %1
mov edx, %2
int 80h
%endmacro
section .text
global _start ;нужно декларировать для использования gcc
_start: ;показываем линкеру точку входа
write_string msg1, len1
write_string msg2, len2
write_string msg3, len3
mov eax,1 ;номер системного вызова (sys_exit)
int 0x80 ;вызов ядра
section .data
msg1 db 'Привет, программист!',0xA,0xD
len1 equ $ - msg1
msg2 db 'Добро пожаловать в мир,', 0xA,0xD
len2 equ $- msg2
msg3 db 'программирования на ассемблере в Linux! '
len3 equ $- msg3
Выполнение этой программы даст следующий результат:
Привет, программист! Добро пожаловать в мир, программирования на ассемблере в Linux!
Ассемблер: Управление файлами
Система рассматривает любые входные или выходные данные как поток байтов. Есть три стандартных файловых потока:
- Стандартный ввод (stdin),
- Стандартный вывод (stdout) и
- Вывод ошибок (stderr).
Файловый дескриптор
Файловый дескриптор — это 16-разрядное целое число, назначаемое файлу в качестве идентификатора файла. Когда создаётся новый файл или открывается существующий файл, дескриптор файла используется для доступа к файлу.
Файловый дескриптор стандартных файловых потоков — stdin, stdout и stderr — равны 0, 1 и 2 соответственно.
Файловый указатель
Файловый указатель определяет местоположение для последующей операции чтения/записи в файле в виде байтов. Каждый файл рассматривается как последовательность байтов. Каждый открытый файл связан с указателем файла, который задаёт смещение в байтах относительно начала файла. Когда файл открыт, указатель файла устанавливается в ноль.
Системные вызовы обработки файлов
В следующей таблице кратко описаны системные вызовы, связанные с обработкой файлов.
| %eax | Имя | %ebx | %ecx | %edx |
|---|---|---|---|---|
| 2 | sys_fork | struct pt_regs | — | — |
| 3 | sys_read | unsigned int | char * | size_t |
| 4 | sys_write | unsigned int | const char * | size_t |
| 5 | sys_open | const char * | int | int |
| 6 | sys_close | unsigned int | — | — |
| 8 | sys_creat | const char * | int | — |
| 19 | sys_lseek | unsigned int | off_t | unsigned int |
Шаги, необходимые для использования системных вызовов, такие же как мы обсуждали ранее:
- Поместите номер системного вызова в регистр EAX.
- Сохраните аргументы системного вызова в регистрах EBX, ECX и т. д.
- Вызовите соответствующее прерывание (80h).
- Результат обычно возвращается в регистр EAX.
Создание и открытие файла
Для создания и открытия файла выполните следующие задачи:
- Поместите номер 8 системного вызова sys_creat() в регистр EAX.
- Поместите имя файла в регистр EBX.
- Поместите права доступа к файлу в регистр ECX.
Системный вызов возвращает дескриптор файла созданного файла в регистр EAX, в случае ошибки код ошибки находится в регистре EAX.
Открытие существующего файла
Чтобы открыть существующий файл, выполните следующие задачи:
- Поместите номер 5 системного вызова sys_open() в регистр EAX.
- Поместите имя файла в регистр EBX.
- Поместите режим доступа к файлу в регистр ECX.
- Поместите права доступа к файлу в регистр EDX.
Системный вызов возвращает дескриптор файла созданного файла в регистре EAX, в случае ошибки код ошибки находится в регистре EAX.
Среди режимов доступа к файлам чаще всего используются: только чтение (0), только запись (1) и чтение-запись (2).
Чтение из файла
Для чтения из файла выполните следующие задачи:
- Поместите номер 3 системного вызова sys_read() в регистр EAX.
- Поместите дескриптор файла в регистр EBX.
- Поместите указатель на входной буфер в регистр ECX.
- Поместите размер буфера, то есть количество байтов для чтения, в регистр EDX.
Системный вызов возвращает количество байтов, считанных в регистре EAX, в случае ошибки код ошибки находится в регистре EAX.
Запись в файл
Для записи в файл выполните следующие задачи:
- Поместите номер 4 системного вызова sys_write() в регистр EAX.
- Поместите дескриптор файла в регистр EBX.
- Поместите указатель на выходной буфер в регистр ECX.
- Поместите размер буфера, т.е. количество байтов для записи, в регистр EDX.
Системный вызов возвращает фактическое количество байтов, записанных в регистр EAX, в случае ошибки код ошибки находится в регистре EAX.
Закрытие файла
Для закрытия файла выполните следующие задачи:
- Поместите номер 6 системного вызова sys_close() в регистр EAX.
- Поместите дескриптор файла в регистр EBX.
Системный вызов возвращает, в случае ошибки, код ошибки в регистре EAX.
Обновление файла
Для обновления файла выполните следующие задачи:
- Поместите номер 19 системного вызова sys_lseek() в регистр EAX.
- Поместите дескриптор файла в регистр EBX.
- Поместите значение смещения в регистр ECX.
- Поместите референтную позицию для смещения в регистр EDX.
Исходная позиция может быть:
- Начало файла — значение 0
- Текущая позиция — значение 1
- Конец файла — значение 2
Системный вызов возвращает, в случае ошибки, код ошибки в регистре EAX.
Пример
Следующая программа создаёт и открывает файл с именем myfile.txt и записывает текст «Привет от HackWare!» в этом файле. Далее программа читает файл и сохраняет данные в буфере с именем info. Наконец, онf отображает текст как сохранённый в info.
section .text
global _start ;нужно декларировать для использования gcc
_start: ;точка входа для линкера
; создаём файл
mov eax, 8
mov ebx, file_name
mov ecx, 0777 ;чтение, запись и выполнение всеми
int 0x80 ;выхов ядра
mov [fd_out], eax
; пишем в файл
mov edx,len ;количество байт
mov ecx, msg ;сообщение для записи
mov ebx, [fd_out] ;файловый дескриптор
mov eax,4 ;номер системного вызова (sys_write)
int 0x80 ;вызов ядра
; закрываем файл
mov eax, 6
mov ebx, [fd_out]
int 0x80 ;вызов ядра
; вывод сообщения о том, что закончена запись в файл
mov eax, 4
mov ebx, 1
mov ecx, msg_done
mov edx, len_done
int 0x80
; открываем файл для чтения
mov eax, 5
mov ebx, file_name
mov ecx, 0 ;доступ только для чтения
mov edx, 0777 ;чтение, запись и выполнение для всех
int 0x80
mov [fd_in], eax
; читаем из файла
mov eax, 3
mov ebx, [fd_in]
mov ecx, info
mov edx, 200
int 0x80
; закрываем файл
mov eax, 6
mov ebx, [fd_in]
int 0x80
; выводим info
mov eax, 4
mov ebx, 1
mov ecx, info
mov edx, 200
int 0x80
mov eax,1 ;номер системного выхова (sys_exit)
int 0x80 ;выхов ядра
section .data
msg db 'Привет от HackWare.ru!'
len equ $-msg
msg_done db 'Записано в файл', 0xa
len_done equ $-msg_done
file_name db 'myfile.txt'
section .bss
fd_out resb 1
fd_in resb 1
info resb 200
Результат выполнения программы:
Записано в файл Привет от HackWare.ru!
Ассемблер: Управление памятью
Системный вызов sys_brk() предоставляется ядром для выделения памяти без необходимости её перемещения позже. Этот вызов выделяет память прямо за изображением приложения в памяти. Эта системная функция позволяет вам установить максимальный доступный адрес в разделе данных.
Этот системный вызов принимает один параметр, который является наибольшим адресом памяти, который необходимо установить. Это значение сохраняется в регистре EBX.
В случае ошибки sys_brk() возвращает -1 или возвращает отрицательный код ошибки. В следующем примере демонстрируется динамическое распределение памяти.
Пример
Следующая программа выделяет 16 КБ памяти с помощью системного вызова sys_brk() —
section .text global _start ;нужно декларировать для использования gcc _start: ;указываем линкеру точку входа mov eax, 45 ;sys_brk xor ebx, ebx int 80h add eax, 16384 ;количество байт для резервирования mov ebx, eax mov eax, 45 ;sys_brk int 80h cmp eax, 0 jl exit ;выйи, если ошибка mov edi, eax ;EDI = самый высокий доступный адрес sub edi, 4 ;указание на последнее DWORD mov ecx, 4096 ;количество выделенных DWORD xor eax, eax ;очищаем eax std ;назад rep stosd ;повторить для всей выделенной области cld ;поместить DF флаг в нормальное состояние mov eax, 4 mov ebx, 1 mov ecx, msg mov edx, len int 80h ;печатаем сообщение exit: mov eax, 1 xor ebx, ebx int 80h section .data msg db "Выделено 16 кб памяти!", 10 len equ $ - msg
Результат работы приведённого выше кода:
Выделено 16 кб памяти!
Перевод отвратительный. Тот, кто это переводил наверно гений. Дошел до того, то в байте 9 бит??!! Неправильное понимания правила четности. Бит четности имеет значение 1, если у соотвествующего байта количество 1-х битов нечетно. 0 — если иначе (четно). Зачем так вводить людей в заблуждение?
Приветствую! Замечание абсолютно верное. Хотел сослаться на первоисточник (ссылка в самом верху), но там уже по-другому:
The main internal hardware of a PC consists of processor, memory, and registers. Registers are processor components that hold data and address. To execute a program, the system copies it from the external device into the internal memory. The processor executes the program instructions.
The fundamental unit of computer storage is a bit; it could be ON (1) or OFF (0) and a group of 8 related bits makes a byte on most of the modern computers.
So, the parity bit is used to make the number of bits in a byte odd. If the parity is even, the system assumes that there had been a parity error (though rare), which might have been caused due to hardware fault or electrical disturbance.
То есть неверную фразу просто убрали, из-за чего непонятно, почему в третьем абзаце продолжается разговор о бите чётности, хотя до этого он не упоминался.
Как говорится, «тот, кто лечится по медицинскому учебнику, рискует умереть от опечатки». Я переводил этот текст в рамках своего самообразования, то есть я тоже только осваиваю этот вопрос, поэтому я не могу исправлять чужие ошибки. Вывод: нужно читать более авторитетные источники, а не написанные энтузиастами тексты, которые переводят другие энтузиасты.
И, кстати, при критике не надо переходить на личности. Не ошибается только то, кто ничего не делает. В частности, вы написали несколько строк и тоже ошиблись.
Существует "even parity", то есть «чётная чётность» и "odd parity", то есть «нечётная чётность». В первом случае действительно подгоняется под чётное количество единиц, а во втором случае подгоняется под нечётное количество единиц. Я же не называю вас самоуверенным «гением», который не может написать две строки без фактической ошибки по вопросу, который гуглится за две секунды.
Исправлять неточности и ошибки общедоступных материалах и наработок сообщества, в том числе в open source — это здорово. Переходить на личности и пытаться кого-то зацепить, это НЕ круто.
Какой вы вежливый, прямо застыдили меня.
Про odd parity действительно не подумал.
Друзья, перевод данных основ по Ассемблеру завершён!
Если у вас возникли вопросы или проблемы с примерами, то пишите их в комментариях.
Если вам понравилось, то делитесь ссылками на данный вводный урок — если будет интерес, то будут подготовлены последующие части с интересными примерами программ на Ассемблере.
================================================================
Двоичная арифметика
Следующая таблица иллюстрирует четыре простых правила для двоичного сложения:
Эту таблицу нужно читать по столбцам сверху вниз. В первом столбце складываются 0 и 0 — в результате получается 0. Во втором примере складываются 1 и 0 (или 0 и 1 — без разницы), в результате получается 1. В третьем столбце складываются две единицы — в результате в текущей позиции получается 0, но на одну позицию влево добавляется единица. Если в этой позиции уже есть единица — то применяется это же правило, то есть в позиции пишется 0, и 1 передаётся влево. В четвёртом примере складываются три единицы — в результате, в текущей позиции записывается 1, и ещё одна 1 передаётся влево.
================================================================
ЭТО БРЕД!!!!
Ну конечно, бред.



 В двоичном счислении:
В двоичном счислении:
0+0 = 0
1+0 = 1
1+1 = 10
1+1+1 = 11
Попейте кофейку или проконсультируйтесь со своим учителем информатики, пока не поймёте эти элементарнейшие вещи, читать дальше смысла нет.
ИМХО, «ассемблер для крякера» вам пока рановато…
Как сказал наш пророк Мухаммед САВ «Цену хорошим людям знают только хорошие люди». Надеюсь вас не сильно расстраивает не очень обдуманные комменты
Спасибо за перевод!