Анализ динамически генерируемых с помощью JavaScript сайтов и сайтов с подгружаемым контентом (поиск ссылок на видео, изображения, на подгружаемый контент)
Примечание: ссылки на видео и на другой контент, который может быть запрещён авторскими и другими правами, не являются целью данной статьи. Поиск адресов прямых ссылок показан как часть процесса исследования веб приложения, либо сбора доказательств в рамках IT криминалистики.
На написание этой статьи меня вдохновил перевод статьи «Статический анализ исходного кода веб-сайта в браузере», которую я рекомендую прочитать первой. В ней даётся вводная информация об инструментах разработчика в веб-браузерах. Как и в предыдущей статье, я буду показывать на примере Google Chromium — в других браузерах описанный методы тоже должны работать (но может отличаться пользовательский интерфейс, название вкладок и т.д.).
Динамически генерируемые с помощью JavaScript сайты
JavaScript, а также многочисленные вспомогательные библиотеки и фреймворки (платформы) позволяют делать удивительные интерактивные сайты. При этом исходный код может содержать минимум элементов. На самом деле, вполне реально сделать веб-страницу в исходном коде которой в <body> не будет ничего, кроме одного подключённого JavaScript файла, но которая в веб браузере может показывать целый портал с видеороликами, картинками, бесконечно подгружаемыми записями и так далее. При этом у этой страницы в динамическом состоянии может быть весьма объёмный и сложный DOM. В статье, на которую выше дана ссылка, кратко описывается что такое DOM. Упрощённо говоря, о DOM можно думать как о HTML содержимом сайта, которое сформировано в процессе выполнения. Конечный DOM может быть точно таким же как исходный код — в случаях, если не используется JavaScript для добавления и удаления элементов в процессе работы веб страницы, а может кардинально отличаться от исходного HTML кода.
Для многих современных приложений, активно использующих JavaScript и многочисленные фреймворки, стало очень трудно и почти бесполезно анализировать исходный HTML код, поскольку основная функциональность для них перенесена в код JavaScript, который зачастую ещё и «сжат» в результате чего выглядит нечитаемым.
Из этой ситуации можно выйти с помощью Burp Suite или подобных программ, которые анализируют отправляемые запросы и получаемые ответы. Но в веб-браузеры встроены не менее мощные инструменты по анализу запросов! Причём, у веб-браузера есть даже свои преимущества:
- вы работаете с конкретной страницей в конкретной вкладке (если открыто несколько вкладок, то Burp Suite будет одновременно выводить активность каждой их них, в результате можно запутаться)
- работа с сайтами на HTTPS ничем не отличается от работы с сайтами на HTTP (если мы настраиваем прокси, Burp Suite и пр., то нам нужно повозиться с доверенным корневым центром сертификации)
- не нужно дополнительных программ — нужен только браузер
- не нужно вообще настраивать прокси и прочее
- множество дополнительных возможностей в виде отладчика JavaScript
- множество информации, например, сгруппированная по доменным именам активность конкретной вкладки страницы
На самом деле, для некоторых задач Инструменты разработчика веб-браузера по своей «убойности» вполне сопоставимы с некоторыми специализированными инструментами для пентестинга…
Как скачать видео с любого сайта
В этой статье нашим лучшим другом будет вкладка Network в инструментах разработчика. Кстати, чтобы отрыть инструменты разработчика в контекстном меню веб-браузера Chrome, Chromium и их производных выберите Просмотреть код, либо нажмите F12. Иногда после открытия Инструментов разработчика нужно перезагрузить вкладку веб-браузера, чтобы для анализа были доступны все данные.
Теперь для тренировки попробуем найти прямые ссылки на скачивание видео файлов с некоторых сайтов.
В целях демонстрации я в Гугле искал первые попавшиеся «киносайты». Примечание: не нарушайте авторских прав, не скачивайте контент защищённый авторскими правами. И вообще — по-настоящему насладиться фильмом можно только в кинотеатре.
Переходим на один из «киносайтов», открываем DevTools (кнопка F12), переключаемся на вкладку Network, запускаем видео и ожидаем окончания рекламы. Затем запускаем сам фильм и ждём хотя бы несколько минут.
Во вкладке Network (1) будет постоянно обновляться информация о загружаемых данных. Ищем те строки, где самое большое количество переданного трафика (чтобы было проще, можно сделать сортировку по столбцу Size) (2) и затем кликаем правой кнопкой мыши по соответствующей строке и там выбираем Copy → Copy link address (3):
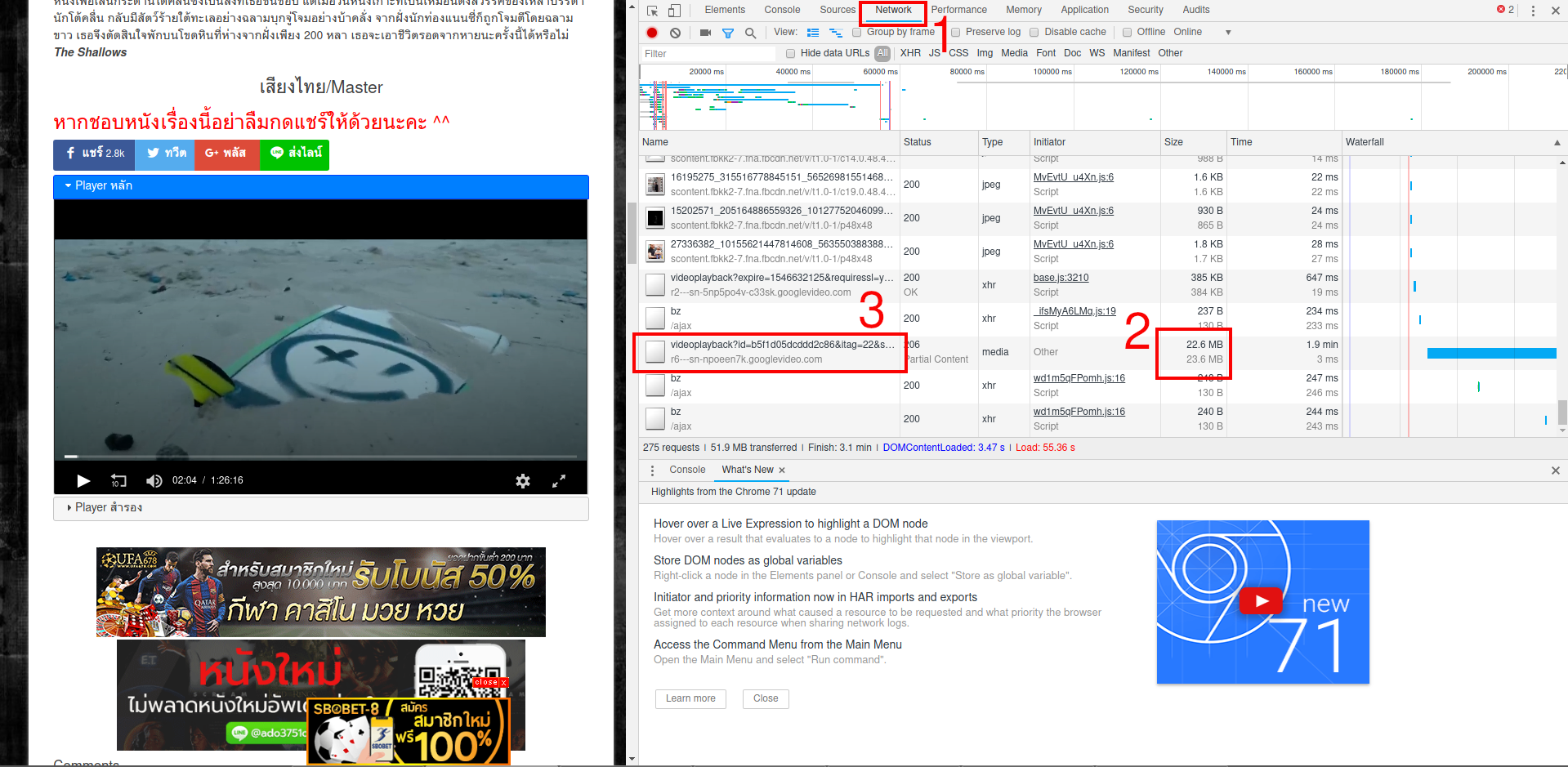
Весьма вероятно, что эта ссылка и будет прямой ссылкой на видео файл. Вот и всё! Скачать эту ссылку можно в любом менеджере закачек или прямо в браузере.
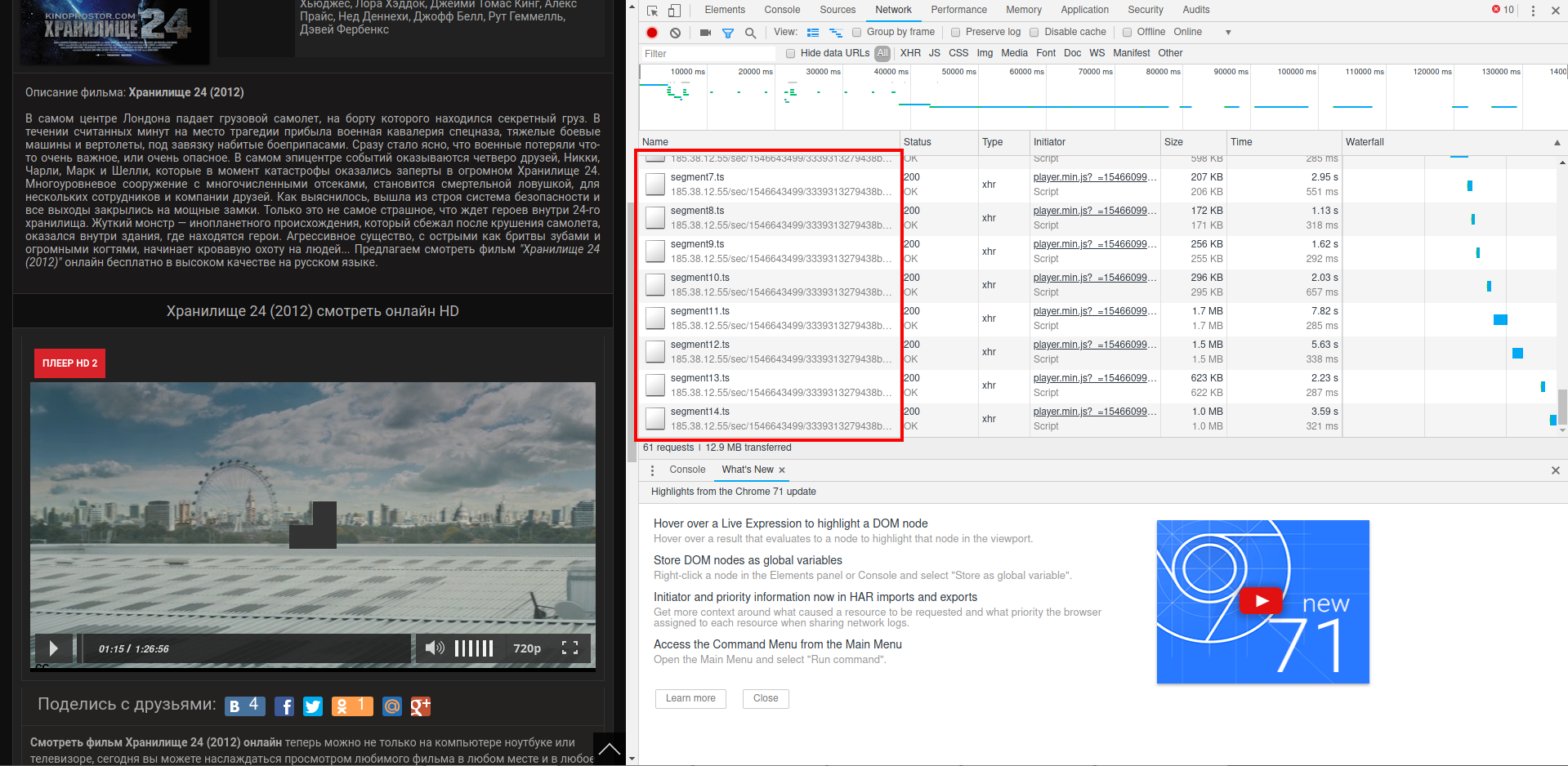
Некоторые веб-сайты в Network будут показывать постоянно скачивание небольших фрагментов:

Пример полученной ссылки (чуть сокращена): http://185.38.12.55/sec/АДРЕС/ivs/7f/ec/835368cb78be.mp4/hls/tracks-2,4/segment14.ts. Если попытаться скачать по этой ссылке, то будет скачен небольшой фрагмент в пару мегабайт.
Обратите внимание на последний сегмент /segment14.ts, если его убрать, чтобы получилась ссылка вида http://185.38.12.55/sec/АДРЕС/ivs/7f/ec/835368cb78be.mp4/hls/tracks-2,4, то будет скачен файл целиком! Вот так вот всё просто!
Ещё один пример на другом сайте, в котором этот способ также сработал:
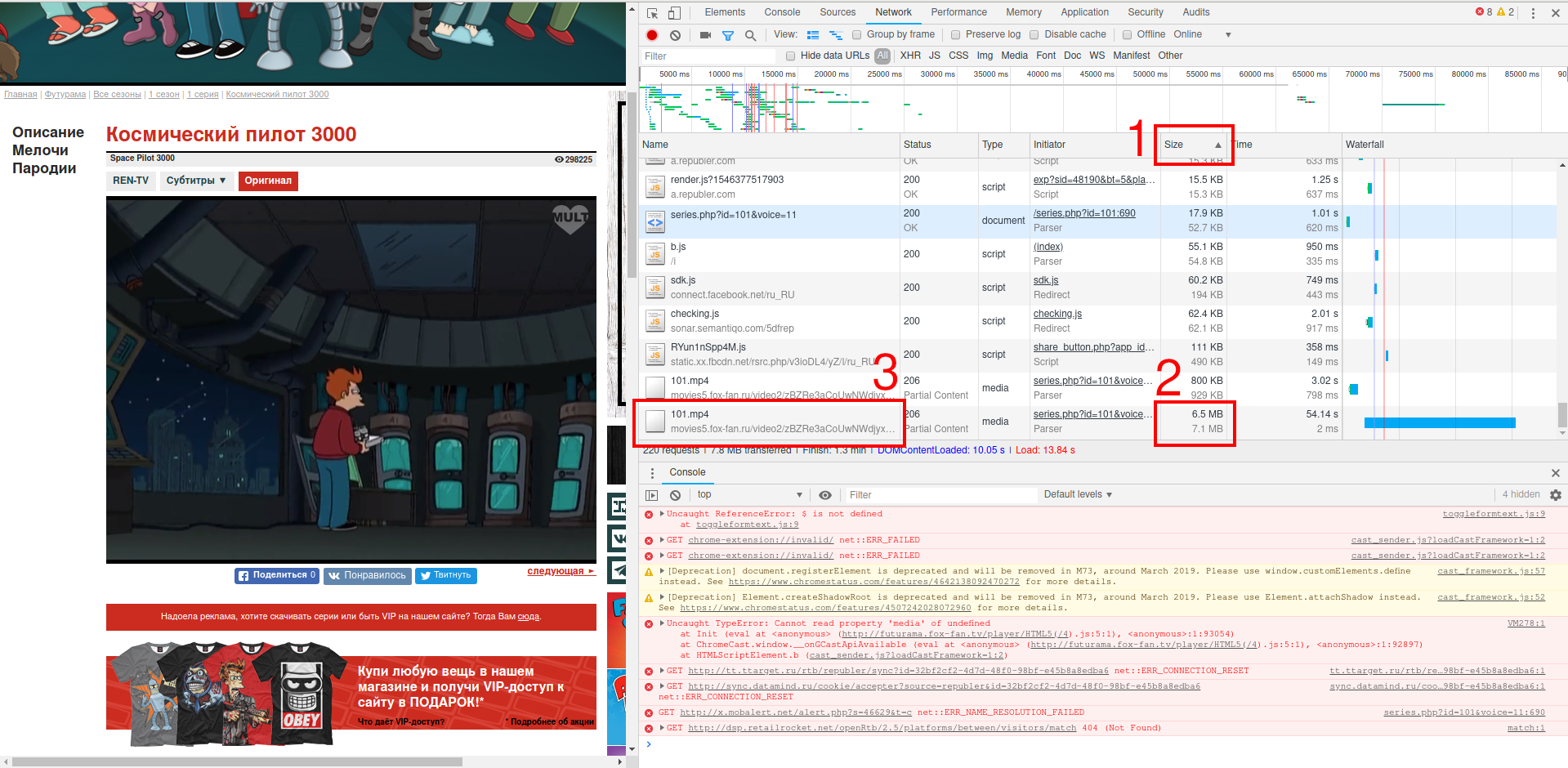
Видимо, эти киносайты используют один и тот же источник пиратских видео файлов, поскольку адрес тоже ведёт на IP 185.38.12.55. Чтобы разнообразить примеры, зайдёт на сайт мультиков. И опять, после пропуска рекламы и запуска видео с лёгкостью находим нужную ссылку (пришлось сделать сортировку по столбцу Size):
Давайте возьмём что-нибудь потруднее. Например YouTube. Я был уверен, что вот здесь то я точно обломаюсь. На скриншоте видно, что видео скачивается в браузере фрагментами:
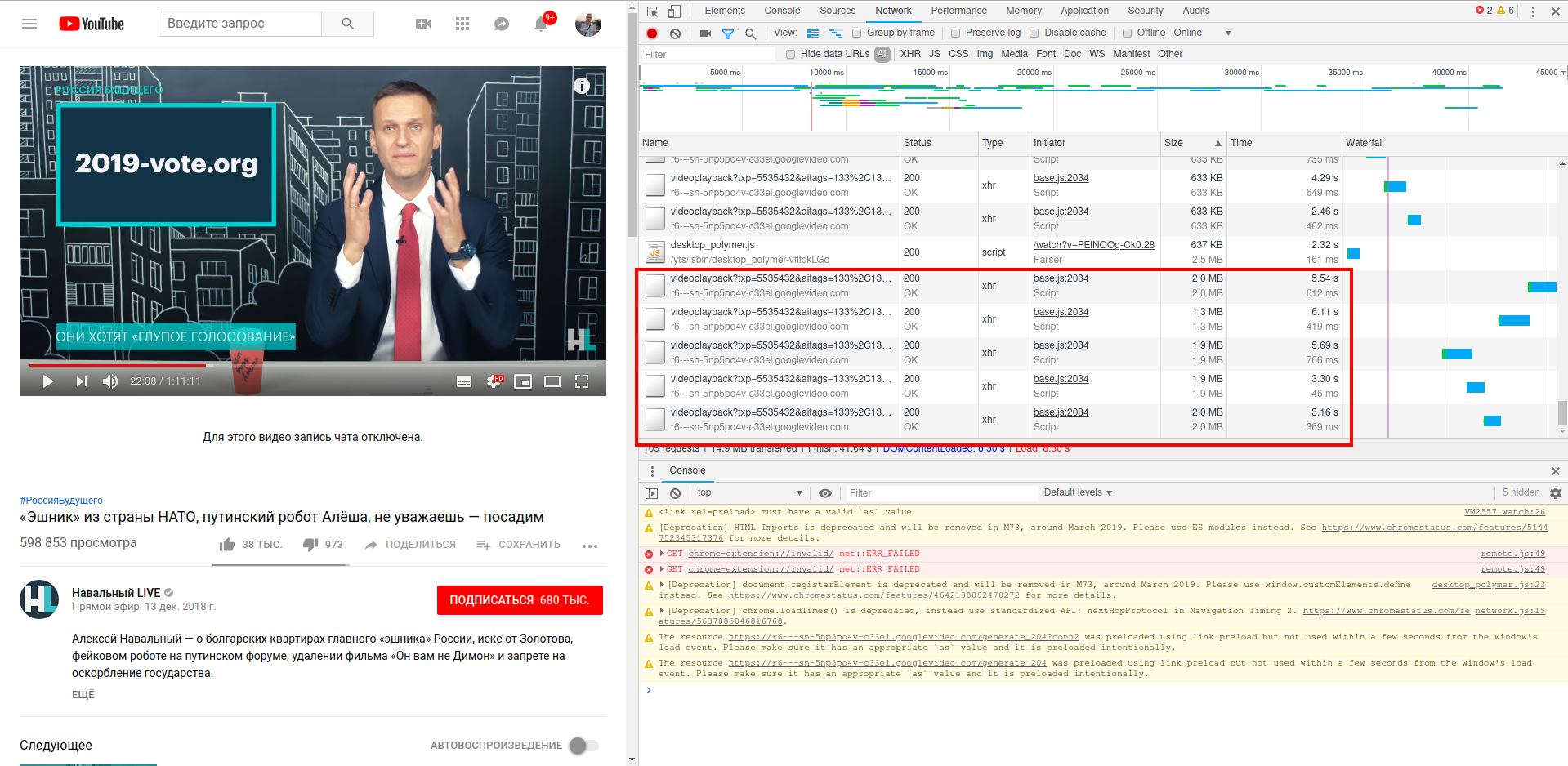
Я скопировал описанными выше способами ссылку, у меня получилось что-то вроде такого (ссылка сокращена): https://r6—sn-5np5po4v-c33el.googlevideo.com/videoplayback?ЧАСТЬ_АДРЕСА&cver=2.20181221&range=274625298-276722449&rn=23&rbuf=46746
Эта ссылка скачивает этот фрагмент в пару мегабайт. Я обратил внимание на параметр &range=. Так вот, если убрать этот параметр, а также всё, что идёт за ним, то скачивается полное видео:
И здесь всё оказалось очень просто.
На самом деле, на парочке сайтов я всё-таки обломался. Пример такого сайта rutube — там видео тоже скачивается фрагментами. Попытки определить ссылку на полный файл закончились неудачей. Есть программы которые без проблем качают с разных мест, в том числе и оттуда. Меня заинтересовало, как именно они работают? Я запустил JDownloader я запустил Wireshark — оказалось, что банально скачиваются фрагменты и затем, видимо, объединяются в один файл.
Как скачать видео с Twitter
Если вам нужно обычная GIF'ка, то её можно скачать через контекстное меню, вызываемое правой кнопкой мыши, — как и другие изображения. Но вот например в твите https://twitter.com/assortedhackery/status/1076886102466801664 встроено настоящее видео.
Описанный выше способ также помог найти ссылку: https://video.twimg.com/ext_tw_video/1076885587171463169/pu/vid/18000/21420/640×360/rqUoHq-EcuUA7dGu.ts
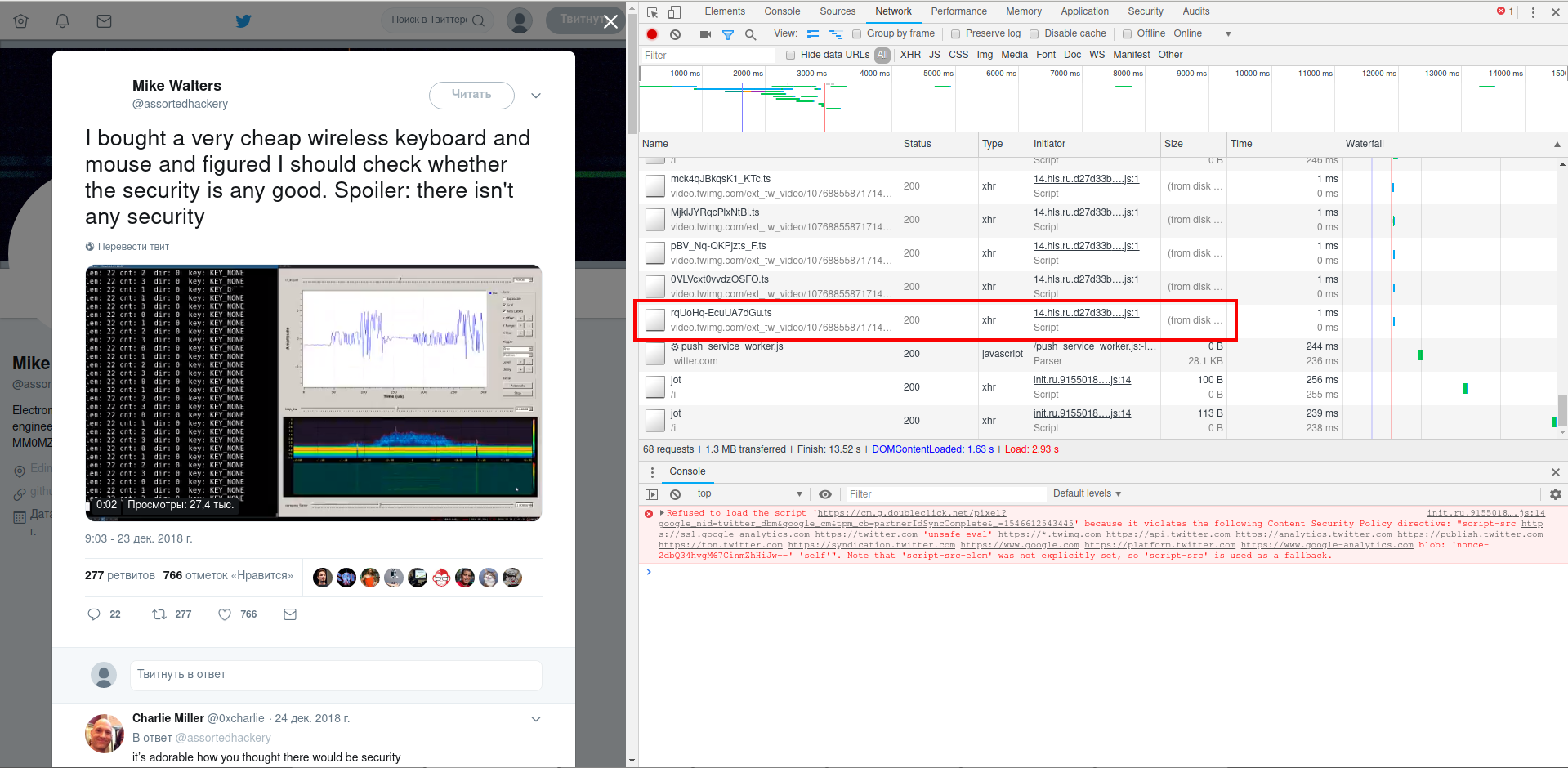
Если слишком много данных, то попробуйте выполнить поиск по слову twimg.
Как скачать фотографии с любого сайта
Некоторые сайты не дают скачать картинки. Поверх картинок могут быть наложены разные слои и прочее — просто «Сохранить как» не получится.
Чтобы скачать эти картинки, откройте инструменты разработчика (F12), перейдите во вкладку Network и просмотрите на сайте все интересующие вас картинки. Все ссылки будут собраны в привычном месте. Чтобы облегчить поиск, можно переключиться на дополнительную вкладку Img:
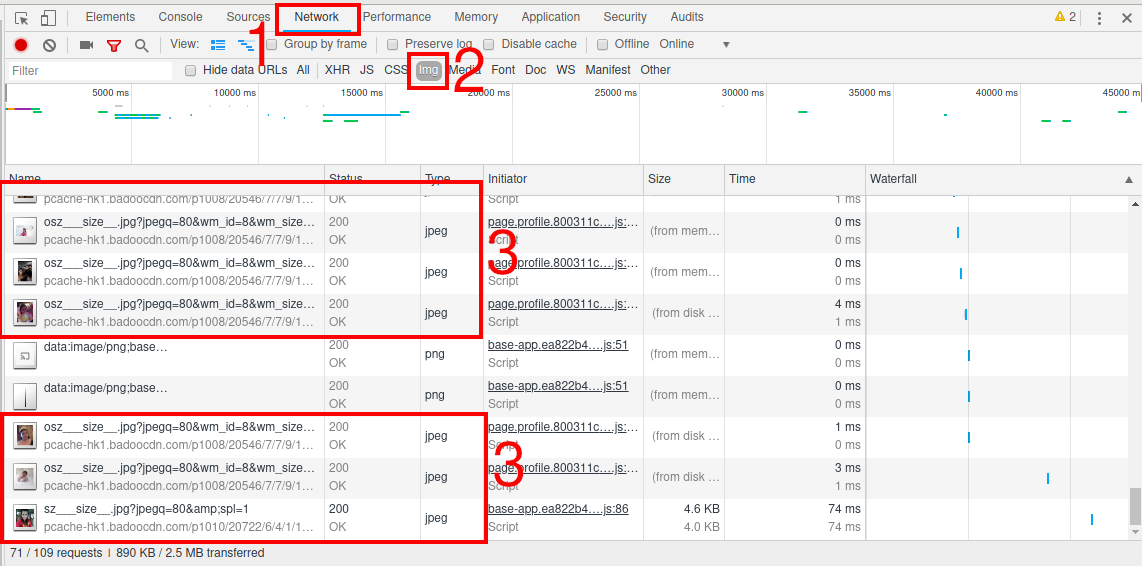
Можно копировать ссылки и открывать в браузере, можно просто дважды кликать по записям и картинки будут автоматически открываться в новых вкладках.
Если вы уже просматривали эти изображения ранее и они содержаться в кэше браузера из-за чего новые запросы не делаются, то поставьте галочку на «Disable cache», чтобы принудительно получать файлы с сервера.
Определение адресов подгружаемого контента страницы
Пример сайтов с подгружаемым контентом — это страницы с «бесконечной» прокруткой, которые создают своё продолжение, как только вы подходите ближе к концу.
При анализе сайта на WordPress с бесконечной прокруткой видно, что запрашиваются адреса страниц вида ?page=2:
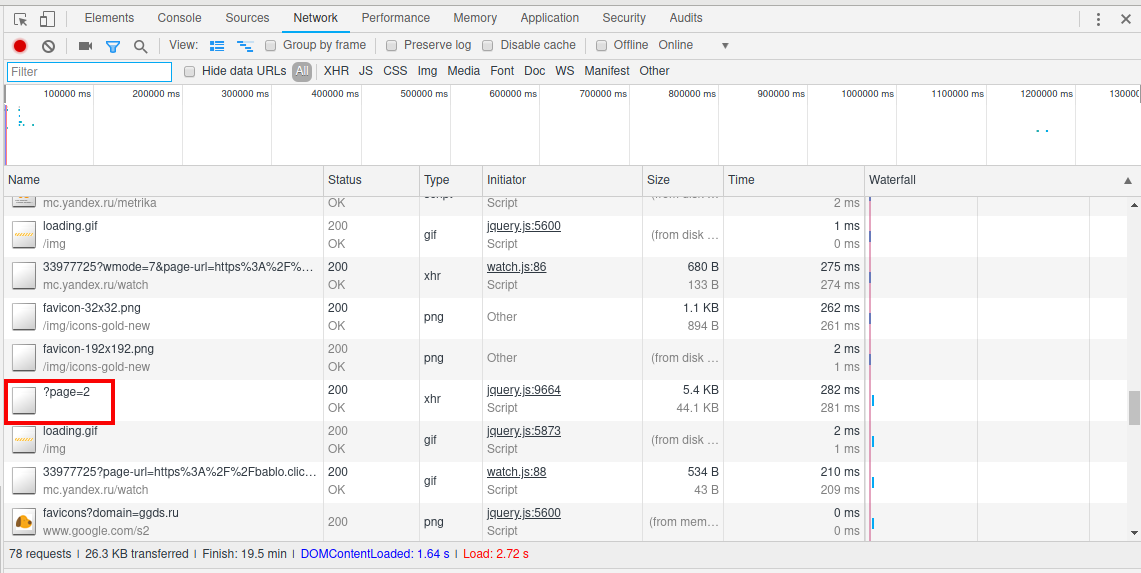
С тем же самым Твиттером чуть сложнее, судя по всему, скачивается файл в формате JSON, из которого уже с помощью JavaScript формируется продолжение страницы:
Выявление сайтов и скриптов следящих за пользователями
Некоторые сайты после загрузки продолжают передавать информацию о действиях пользователей. Если сайт заражён, то он может перехватывать и передавать, например, нажатия клавиш пользователя.
Некоторые счётчики, например, Яндекс.Метрика с включённым Вебивизором делает частые запросы на сайт, собирающий статистику.
Во вкладке Network вы можете увидеть каждый запрос, который делает сайт в том числе и после своей загрузки. Частые и регулярные такие запросы могут означать передачу данных о пользователях.
Заключение
Как и первая статья, эта рассказывает только об одном аспекте Инструментов разработчика в веб-браузерах. Причём рассказывает весьма поверхностно.
Вывод: инструменты разработчика очень полезны для пентестера, оценивающего безопасность или исследующего веб сайты и веб приложения. Время, потраченное на изучение инструментов разработчика не будет потрачено зря ни для веб-мастеров, ни для тестеров на проникновение.
Помните, что скачивание файлов с некоторых сайтов является нарушением условий использования и/или авторских прав. Скачивание контента, защищённого авторским правом, также является нарушением закона.
Связанные статьи:
- Как анализировать POST запросы в веб-браузере (87.7%)
- Статический анализ исходного кода веб-сайта в браузере (63.7%)
- Аудит безопасности роутера SKYWORTH GN542VF — взламываем пароль не выходя из веб-браузера! (63.3%)
- Как использовать User Agent для атак на сайты (61%)
- Атаки на JavaScript (56.6%)
- Брут-форс и эксплуатация скомпрометированных WordPress (RANDOM - 50.4%)
Отличные статьи. И скорость их добавления радует. Хотелось бы больше кейсов. Спасибо за труд.
youtube-dl же есть дя скачивая чего угодно
https://rg3.github.io/youtube-dl/
Да, но всегда полезно знать на уровень ниже.
Иногда смысл даже не в скачивании файлов, я ведь прямо в статье упоминаю JDownloader (универсальная качалка с графическим интерфейсом и тоже с открытым кодом). Иногда интереснее узнать, откуда именно подгружаются элементы страницы и файлы, или куда именно уходят запросы: можно увидеть субдомены (исследование периметра), увидеть, имена файлов, к которым обращается сайт и прочее.