Регулярные выражения в PHP (ч. 2)
Оглавление
Первая часть:
1. Регулярные выражения PHP для новичков
2. Особенности регулярных выражений в PHP
3. Функции для работы с регулярными выражениями в PHP
4. Функции PHP поиска по регулярным выражениям
Буквальное значение букв и цифр
( ) Группировка (последовательность из нескольких заданных символов)
Якоря — анкоры (начало и конец строки)
Внутренние (локальные) модификаторы шаблонов
9. «Жадные» и «ленивые» регулярные выражения
Вторая часть:
11. Непечатные символы в видимой форме в описании шаблона
12. Определение формальных утверждений
13. POSIX нотация для символьных классов
16. Функции PHP для поиска и замены по регулярному выражению
17. Другие функции PHP для работы с регулярными выражениями
18. Когда не нужно использовать регулярные выражения
Рекомендуется начать знакомство с регулярными выражениями в PHP с первой части.
Общие типы символов
Теперь мы опять вернёмся к синтаксису, который может использоваться при написании регулярных выражений. В отличие от ранее рассмотренных основ, описанное ниже является более сложным и применяется реже, либо может быть описано с помощью уже рассмотренного синтаксиса.
Например, далее рассмотрены способы указания общего типа символов — некоторые из этих способов записи являются альтернативным синтаксисом к уже рассмотренным. Допустим если мы хотим указать в регулярном выражении «любая цифра», то мы можем использовать [0-9]. Также имеется ещё один вариант записи с помощью экранирующих последовательностей. «Любая десятичная цифра» в них обозначается как \d.
Экранирующие последовательности — это набор символов, которые начинаются с обратного слэша \ и, следовательно, которые теряют своё буквальное значение, а начинают иметь специальное значение. Получается, что для специальных символов обратный слэш отключает их специальное значение, а для обычных букв и цифр он включает специальное значение (если оно предусмотрено).
Среди экранирующих последовательностей есть элементы синтаксиса, который невозможно передать иным способом. Примеры будут показаны далее.
Общие типы символов обозначаются так:
\d
любая десятичная цифра
\D
любой символ, кроме десятичной цифры
\h
любой горизонтальный пробельный символ
\H
любой символ, не являющийся горизонтальным пробельным символом
\s
любой пробельный символ
\S
любой непробельный символ
\v
любой вертикальный пробельный символ
\V
любой символ, не являющийся вертикальным пробельным символом
\w
Любой символ, образующий "слово"
\W
Любой символ, не образующий "слово"
Каждая пара таких специальных последовательностей делит полное множество всех символов на два непересекающихся множества. Любой символ соответствует одному и только одному множеству из пары.
Следующие символы считаются как "пробельные": HT (9), LF (10), FF (12), CR (13), и пробел (32). Тем не менее, если идет локале-зависимый поиск, и произойдет совпадение с символами в диапазоне 128-255, они также будут восприняты как пробельные, например NBSP (A0).
Символ, образующий "слово" — это произвольная цифра, буква или символ подчеркивания, проще говоря, любой символ, который может являться частью "слова" в Perl. Определение букв и цифр управляется символьными таблицами, с которыми была собрана PCRE. И, как следствие, эти наборы могут отличаться в различных локализированных дистрибутивах. Например, в локали "fr" (Франция) некоторые символы с кодом выше 128 используются для записи ударных символов и, соответственно, соответствуют маске \w.
Описанные выше типы символов могут применяться как внутри, так и вне символьных классов, и соответствуют одному символу данного типа. Если текущая точка сравнения находится в конце строки, ни один из них не сможет совпасть, так как нет символа, с которым могло бы произойти совпадение.
У этих символов может быть весьма полезное применение. Давайте вспомним (чуть переделанное) регулярное выражение для вывода HTML тэга всех заголовков вместе с конечным тегом, а также вместе с самим содержанием заголовка:
/<h[1-6]{1}( [^>]+>|>)(.*?)<\/h[1-6]{1}>/
Используя уже известный код:
$link = 'https://hackware.ru/?p=7916';
$agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36';
$ch = curl_init($link);
curl_setopt($ch, CURLOPT_USERAGENT, $agent);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$response_data = curl_exec($ch);
if (curl_errno($ch) > 0) {
die('Ошибка curl: ' . curl_error($ch));
}
curl_close($ch);
$count = preg_match_all ('/<h[1-6]{1}( [^>]+>|>)(.*?)<\/h[1-6]{1}>/', $response_data, $found);
#$count = preg_match_all ('~(http(|s))://[^"\'><\s]+~', $response_data, $found);
echo 'Всего найдено совпадений: ' . $count . "\r\n";
print_r($found);
я получил вот такой результат:
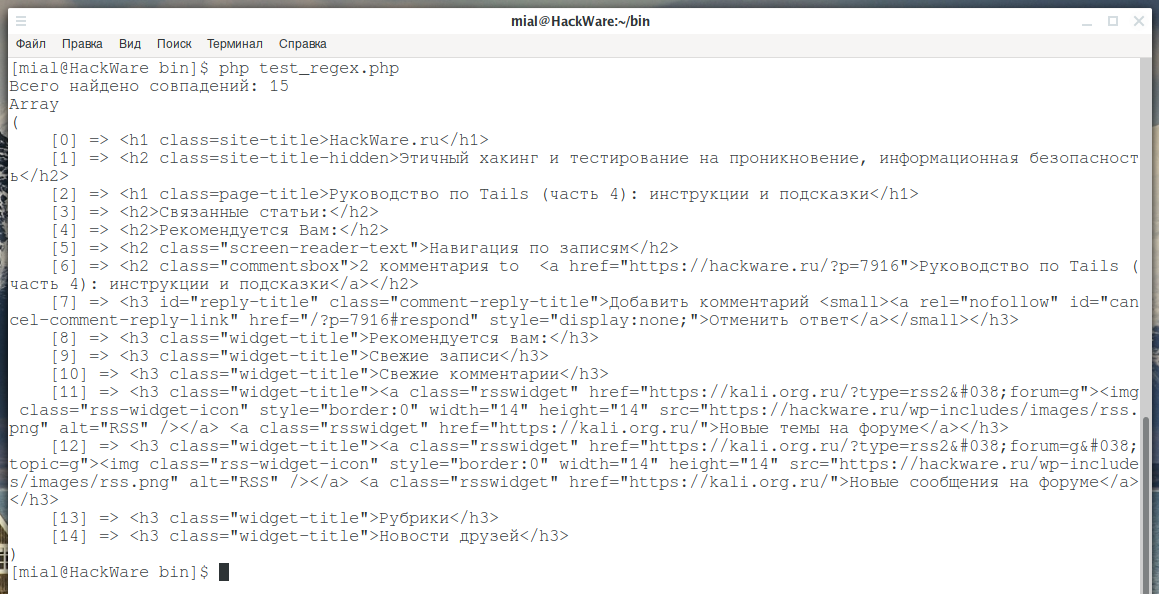
Найдено всего 15 совпадений, хотя мы помним, что на этой странице заголовков намного больше. Дело в том, что найдены только заголовки, которые в HTML коде записаны в одну строку, например так:
<h3 style="text-align: justify;"><a id="66" name="66"></a>Как смонтировать диск Tails с правами записи<br /></h3>
А если запись разбита на несколько строк, например так:
<h3 style="text-align: justify;"> <a id="66" name="66"></a>Как смонтировать диск Tails с правами записи<br /> </h3>
то такие заголовки найдены не были.
Проблема не в каких-то ограничениях регулярных выражений — в PHP анализ текста происходит именно целиком, то есть даже если текст состоит из нескольких строк, в PHP он анализируется за раз, без разбития на строки.
Проблема в нашем регулярном выражении, которое мы написали — мы не указали, что после открывающего тэга заголовка могут идти пробелы. Затем после содержимого заголовка также могут идти пробелы. Давайте составим новое регулярное выражение, с учётом этого. Любые пробельные символы обозначаются как \s. Их может не быть вовсе, а может быть несколько, поэтому в качестве квантора нужно использовать звёздочку, получаем \s*. Эту конструкцию вставляем два раза: 1) между открывающим HTML тэгом и содержимым заголовка; 2) между концом содержимого заголовка и закрывающим HTML тэгом.
Получаем такое регулярное выражение:
/<h[1-6]{1}( [^>]+>|>)\s*(.*?)\s*<\/h[1-6]{1}>/
В результате находим 51 заголовок — видимо, это все заголовки анализируемой страницы, среди них как написанный в одну строку, так и многострочные.
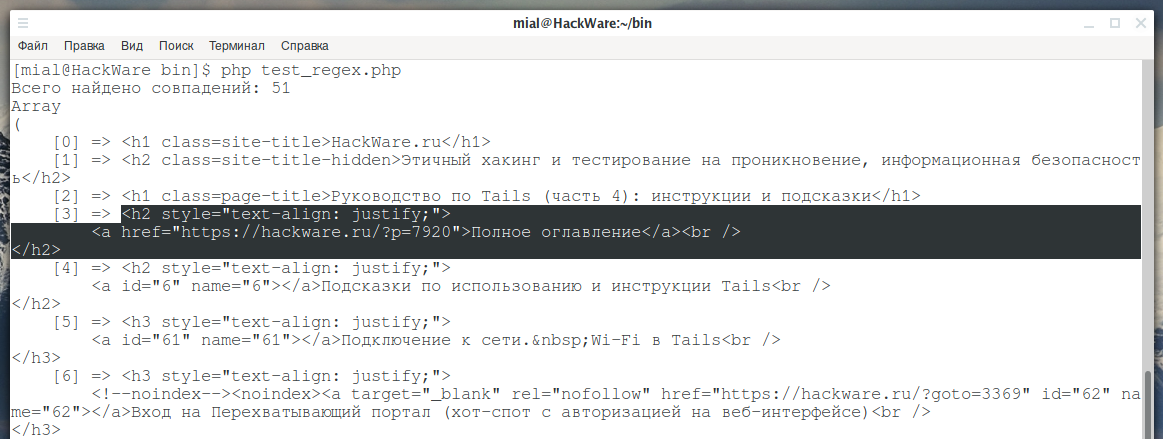
В подобных случаях также можно использовать модификатор регулярного выражения s. Подробности и примеры смотрие в статье «Поиск по нескольким строкам в PHP с функциями preg_match_all и preg_match».
Следующие два раздела (непечатные символы и определение формальных утверждений) — нечасто применимы, поэтому если вы в них не разобрались, то просто переходите к последующим параграфам.
Непечатные символы в видимой форме в описании шаблона
В PCRE нет ограничений на использование непечатных символов (исключая бинарный ноль, который интерпретируется как конец шаблона), тем не менее, при редактировании программного кода в каком-либо текстовом редакторе гораздо удобнее использовать следующие комбинации, чем реальные символы, которые они представляют:
\a
символ оповещения, сигнал, (BEL, шестнадцатеричный код 07)
\cx
"Ctrl+x", где x - произвольный символ
\e
escape (шестнадцатеричный код 1B)
\f
разрыв страницы (шестнадцатеричный код 0C)
\n
перевод строки (шестнадцатеричный код 0A)
\p{xx}
символ со свойством xx, подробнее смотрите свойства unicode
\P{xx}
символ без свойства xx, подробнее смотрите свойства unicode
\r
возврат каретки (шестнадцатеричный код 0D)
\R
разрыв строки: совпадает с \n, \r и \r\n
\t
табуляция (шестнадцатеричный код 09)
\xhh
символ с шестнадцатеричным кодом hh
\ddd
символ с восьмеричным кодом ddd, либо ссылка на подмаску
Если быть более точным, комбинация "\cx" интерпретируется следующим образом: если "x" - символ нижнего регистра, он преобразуется в верхний регистр. После этого шестой бит символа (шестнадцатеричный код 40) инвертируется. Таким образом "\cz" интерпретируется как шестнадцатеричное значение 1A, в то время как "\c{" получает шестнадцатеричное значение 3B, а "\c;" - 7B.
После "\x" считываются еще две шестнадцатеричные цифры (они могут быть записаны в нижнем или верхнем регистре). В режиме UTF-8, разрешается использование "\x{...}", где содержимое скобок является строкой из шестнадцатеричных цифр. Она интерпретируется как символ UTF-8 character с кодом, совпадающим с данным шестнадцатеричным числом. Исходная шестнадцатеричная экранирующая последовательность, \xhh, совпадает с двухбайтным UTF-8 символом, если его значение превышает 127.
После "\0" считываются две восьмеричные цифры. Если в записи менее двух цифр, будут использованы все фактически присутствующие цифры. Таким образом, последовательность "\0\x\07" будет интерпретирована как два бинарных нуля, за которыми следует символ оповещения (звонок). В случае, если вы используете представление числа в восьмеричном коде, убедитесь, что за начальным нулем следуют две значащие цифры.
Обработка обратного слеша, за которым следует ненулевая цифра, несколько сложнее. Вне символьного класса PCRE воспринимает обратный слеш и следующие за ним цифры как десятичное число. Если полученное значение меньше десяти, либо если шаблон содержит по меньшей мере такое же количество предшествующих текущей позиции подмасок, вся конструкция интерпретируется как ссылка на подмаску. Более детальное описание будет приведено ниже при обсуждении механизма работы подмасок.
Внутри символьного класса, либо если полученное значение больше 9 и соответствующее количество предшествующих подмасок отсутствует, PCRE считывает до трех восьмеричных цифр, следующих за обратным слешем, и генерирует один байт из последних 8-ми значащих битов полученного значения. Все последующие цифры обозначают себя же. Например:
\040
еще один способ записи пробела
\40
то же самое в случае, если данной записи предшествует менее сорока подмасок
\7
всегда интерпретируется как ссылка на подмаску
\11
может быть как обратной ссылкой, так и альтернативной записью символа табуляции
\011
всегда интерпретируется как символ табуляции
\0113
символ табуляции, за которым следует цифра "3"
\113
интерпретируется как символ с восьмеричным кодом 113 (так как ссылок на подмаски не может быть более чем 99)
\377
байт, всецело состоящий из единичных битов
\81
либо обратная ссылка, либо бинарный ноль, за которым следуют цифры "8" и "1"
Следует помнить, что восьмеричные значения, превышающие 100, следует писать без лидирующего нуля, так как читается не более трех восьмеричных цифр.
Все последовательности, определяющие однобайтное значение, могут встречаться как внутри, так и вне символьных классов. Кроме того, внутри символьного класса запись "\b" интерпретируется как символ возврата ('backspace', шестнадцатеричный код 08). Вне символьного класса она имеет другое значение (какое именно, описано ниже).
Определение формальных утверждений
Ещё одно использование обратного слеша - определение некоторых формальных утверждений, описывающих условия касательно месторасположения особых позиций в строке и совершенно не затрагивающих сами символы. Использование подмасок как более сложных формальных утверждений описано далее. Такими управляющими последовательностями являются:
\b
граница слова
\B
не является границей слова
\A
начало данных (независимо от многострочного режима)
\Z
конец данных либо позиция перед последним переводом строки (независимо от многострочного режима)
\z
конец данных (независимо от многострочного режима)
\G
первая совпадающая позиция в строке
Описанные выше последовательности не могут встречаться в символьных классах (исключая комбинацию "\b", которая внутри класса означает символ возврата 'backspace').
Границей слова считается такая позиция в строке, в которой из текущего и предыдущего символа только один соответствует \w или \W (т.е. один из них соответствует \w, а другой \W). Начало или конец строки также соответствуют границе слова в случае, если первый или, соответственно, последний символ совпадает с \w.
Специальные последовательности \A, \Z и \z отличаются от общеупотребляемых метасимволов начала строки '^' и конца строки '$' (описанных в разделе якоря первой части) тем, что они всегда совпадают либо в самом начале либо в самом конце строки. На них никак не влияют опции m (PCRE_MULTILINE) и D (PCRE_DOLLAR_ENDONLY). Разница между \Z и \z в том, что \Z соответствует позиции перед последним символом в случае, если последний символ - перевод строки, кроме самого конца строки. В то время, как \z соответствует исключительно концу данных.
Утверждение \G является истинным только в том случае, если текущая проверяемая позиция находится в начале совпадения, указанного параметром offset функции preg_match(). Она отличается от \A при ненулевом значении параметра offset.
\Q и \E могут быть использованы для игнорирования метасимволов регулярных выражений в шаблоне. Например: \w+\Q.$.\E$ совпадет с один или более символов, составляющих "слово",за которыми следуют символы .$. и якорь в конце строки.
Последовательность \K может быть использована для сброса начала совпадения. Например, шаблон foo\Kbar совпадет с "foobar", но сообщит о том, что совпал только с "bar". Использование \K не мешает установке подмасок. Например, если шаблон (foo)\Kbar совпадет со строкой "foobar", первой подмаской все равно будет являться "foo".
POSIX нотация для символьных классов
Perl поддерживает нотацию POSIX для символьных классов. Это включает использование имен, заключенных в [: и :], в свою очередь заключенных в квадратные скобки. PCRE также поддерживает эту запись. Например, [01[:alpha:]%] совпадет с "0", "1", любым алфавитным символом или "%". Поддерживаются следующие имена классов:
| alnum | буквы и цифры |
| alpha | буквы |
| ascii | символы с кодами 0 - 127 |
| blank | только пробел или символ табуляции |
| cntrl | управляющие символы |
| digit | десятичные цифры (то же самое, что и \d) |
| graph | печатные символы, исключая пробел |
| lower | строчные буквы |
| печатные символы, включая пробел | |
| punct | печатные символы, исключая буквы и цифры |
| space | пробельные символы(почти то же самое, что и \s) |
| upper | прописные буквы |
| word | символы "слова" (то же самое, что и \w) |
| xdigit | шестнадцатеричные цифры |
Класс пробельных символов (space) - это горизонтальная табуляция (HT, 9), перевод строки (LF, 10), вертикальная табуляция (VT, 11), разрыв страницы (FF, 12), возврат каретки (CR, 13) и пробел (32). Учтите, что этот список включает вертикальную табуляцию (VT, код 11). Это отличает "space" от \s, который не включает этот символ (для совместимости с Perl).
Название word - это расширение Perl, а blank - расширение GNU, начиная с версии Perl 5.8. Другое расширение Perl - это отрицание, которое указывается символом ^ после двоеточия. Например, [12[:^digit:]] совпадет с "1", "2", или с любой не-цифрой.
В режиме UTF-8, символы со значениями, превышающими 128, не совпадут ни с одним из символьных классов POSIX. Начиная с PHP 5.3.0 и libpcre 8.10 некоторые символьные классы изменены, чтобы использовать свойства символов Unicode, в этом случае упомянутое ограничение не применяется. Читайте руководство PCRE(3) для подробностей.
Подмаски
Подмаска — это часть регулярного выражения, которая участвует в поиске. Подмаска может выполнять несколько функций:
1) если была найдена строка, соответствующая целому регулярному выражению, то в результаты поиска будут возвращены две строки: во-первых, соответствующая всему регулярному выражению, и, во-вторых, соответствующая подмаске
2) найденная в подмаске строка может вновь использоваться в регулярном выражении в качестве обратной ссылке (о них позже)
Подмаски в регулярном выражении выделяются скобками. В регулярном выражении может быть более чем одна подмаска, в этом случае они нумеруются слева направо.
Подмаски могут быть вложенными одна в другую.
При использовании функции preg_match_all возвращается массива, где в качестве первого элемента (с индексом 0) возвращается массив с найденными значениями строк. Если указаны подмаски, то в качестве второго элемента возвращаемого массива (с индексом 1) будет массив с найденными строками, соответствующими первой подмаске. Если используется две подмаски, то будет возвращён ещё один массив и так далее для каждой последующей подмаске.
Как мы помним из первой части, описывающий синтаксис регулярных выражений, скобки имеют и другое значение: или использовании оператора | (ИЛИ) они ограничивают варианты альтернатив друг от друга. Например, шаблон cat(aract|erpillar|) соответствует одному из слов "cat", "cataract" или "caterpillar". Без использования скобок он соответствовал бы строкам "cataract", "erpillar" или пустой строке.
То есть скобки выполняют одновременно две функции.
На самом деле выполнение одновременно двух функций не всегда удобно. Бывают случаи, когда необходима группировка альтернатив без захвата строки. В случае, если после открывающей круглой скобки следует "?:", захват строки не происходит, и текущая подмаска не нумеруется. Например, если строка "the white queen" сопоставляется с шаблоном the ((?:red|white) (king|queen)), будут захвачены подстроки "white queen" и "queen", и они будут пронумерованы 1 и 2 соответственно. Максимальное количество захватывающих подмасок - 65535. Такие большие шаблоны могут не скомпилироваться, в зависимости от настроек libpcre.
В случае, если в незахватывающей подмаске необходимо указать дополнительные опции, можно воспользоваться удобным сокращением: символ, обозначающий устанавливаемую опцию помещается между "?" и ":". Таким образом, следующие два шаблона
(?i:saturday|sunday) (?:(?i)saturday|sunday)
соответствуют одному и тому же набору строк. Поскольку альтернативные версии берутся слева направо, и установленные опции сохраняют своё действие до конца подмаски, опция, установленная в одной ветке, также имеет эффект во всех последующих ветках. Поэтому приведенные выше шаблоны совпадают как с "SUNDAY", так и с "Saturday".
Также можно использовать именованные подмаски с помощью синтаксиса (?P<name>pattern). Эта подмаска будет индексирована в массиве совпадений кроме обычного числового индекса, еще и по имени name. В PHP 5.2.2 было добавлено два альтернативных синтаксиса: (?<name>pattern) и (?'name'pattern).
Иногда бывает необходимо иметь несколько совпадений, исключающих друг друга. Обычно, каждое такое совпадение получает свой собственный номер, даже если шаблон позволяет совпасть только одному из них. Синтаксис (?| позволяет обойти это поведение и убрать дублирующиеся номера. Рассмотрим следующее регулярное выражение, сопоставленное со строкой Sunday:
(?:(Sat)ur|(Sun))day
Здесь Sun сохраняется в ссылке 2, тогда как ссылка 1 пуста. Если же совпадет Sat, то она будет помещена в ссылку 1, а ссылка 2 вообще не будет существовать. Использование (?| в шаблоне решает эту проблему:
(?|(Sat)ur|(Sun))day
В этом шаблоне обе подмаски Sun и Sat будут сохранены под номером 1.
Обратные ссылки в PHP
Как мы только что выяснили, строки, найденные в подмасках, возвращаются вместе с основными найденными строками. Но их можно использовать в самих регулярных выражениях.
Вне символьного класса обратный слеш с последующей цифрой больше нуля (и, возможно, последующими цифрами) интерпретируется как ссылка на предшествующую захватывающую подмаску, предполагая, что соответствующее количество предшествующих открывающих круглых скобок присутствует.
Однако, в случае, если следующее за обратным слешем число меньше 10, оно всегда интерпретируется как обратная ссылка, и приводит к ошибке только в том случае, если нет соответствующего числа открывающих скобок. Другими словами, открывающие скобки не обязаны предшествовать ссылке для чисел меньше 10. "Упреждающая обратная ссылка" может иметь смысл, если используется повторение и более поздняя подмаска участвует в ранней итерации. Более детальную информацию об обработке цифр после обратного слеша можно найти в разделе "Обратный слеш".
Обратная ссылка сопоставляется с частью строки, захваченной соответствующей подмаской, но не с самой подмаской. Таким образом шаблон (sens|respons)e and \1ibility соответствует "sense and sensibility", "response and responsibility", но не "sense and responsibility". В случае, если обратная ссылка обнаружена во время регистрозависимого поиска, то при сопоставлении обратной ссылки регистр также учитывается. Например, ((?i)rah)\s+\1 соответствует "rah rah" и "RAH RAH", но не "RAH rah", хотя сама подмаска сопоставляется без учета регистра.
На одну и ту же подмаску может быть несколько ссылок. Если подмаска не участвовала в сопоставлении, то сопоставление со ссылкой на нее всегда терпит неудачу. Например, шаблон (a|(bc))\2 терпит неудачу, если находит соответствие с "a" раньше, чем с "bc". Поскольку может быть до 99 обратных ссылок, все цифры, следующие за обратным слешем, рассматриваются как часть потенциальной обратной ссылки. Если за ссылкой должна следовать цифра, необходимо использовать ограничитель. В случае, если указан флаг x (PCRE_EXTENDED), ограничителем может быть любой пробельный символ. В противном случае можно использовать пустой комментарий.
Ссылка на подмаску, внутри которой она расположена, всегда терпит неудачу, если это первое сопоставление текущей подмаски. Например, шаблон (a\1) не соответствует ни одной строке. Но все же такие ссылки бывают полезны в повторяющихся подмасках. Например, шаблон (a|b\1)+ совпадает с любым количеством "a", "aba", "ababaa"... При каждой итерации подмаски обратная ссылка соответствует той части строки, которая была захвачена при предыдущей итерации. Чтобы такая конструкция работала, шаблон должен быть построен так, чтобы при первой итерации сопоставление с обратной ссылкой не производилось. Этого можно достичь, используя альтернативы (как в предыдущем примере), либо квантификаторы с минимумом, равным нулю.
Начиная с PHP 5.2.2, управляющая последовательность \g может быть использована для абсолютных и относительных ссылок на подмаски. После этой последовательности должно быть указано беззнаковое или отрицательное число, при желании заключенное в фигурные скобки. Последовательности \1, \g1 и \g{1} эквивалентны друг другу. Использование этого шаблона с беззнаковым числом поможет избежать двусмысленности, присущей числам после обратного слеша. Это также помогает отличить обратные ссылки от символов в восьмеричном формате, а также упрощает запись числового литерала сразу после обратной ссылки, например, \g{2}1.
Использование отрицательных чисел с \g полезно при использовании относительных ссылок. Например, (foo)(bar)\g{-1} соответствует "foobarbar", а (foo)(bar)\g{-2} соответствует "foobarfoo". Это также может быть полезно в длинных шаблонах, в качестве альтернативы отслеживания числа подмасок, на которые можно ссылаться в последующей части шаблона.
Указать обратную ссылку на именованную подмаску можно с помощью (?P=name) или, начиная с PHP 5.2.2, \k<name> или \k'name'. Кроме того, в PHP 5.2.4 была добавлена поддержка \k{name} и \g{name}, а в PHP 5.2.7 для \g<name> и \g'name'.
К примеру, я хочу найти строки, состоящие из пяти любых, но одинаковых цифр, например, «11111», «22222» и так далее, в этом случае я могу написать следующее регулярное выражение:
/(\d)\1\1\1\1/
Как мы рассмотрели чуть выше, экранирующая последовательность \d обозначает любую цифру. Для того, чтобы найденную строку можно было использовать в качестве обратной ссылке, мы заключаем эту часть регулярного выражения в круглые скобки. То есть получается, что мы создаём подмаску в регулярном выражении. Затем идёт обратный слэш \ с цифрой 1 — это и есть обратная ссылка. То есть, что бы ни было найдено в первой подмаске, его значение будет помещено в обратную ссылку \1. Затем ещё идут три таких же обратных ссылки. Получается что регулярное выражение ищет любую цифру, за которой ещё четыре раза идёт эта же самая цифра.
Для поиска возьмём строку:
184839736944444486985688888883467948655555984-222228jhksj;ka87df9h9jgk55555ll4kjl22911110000014g
Код
<?php
$str = '184839736944444486985688888883467948655555984-222228jhksj;ka87df9h9jgk55555ll4kjl22911110000014g';
preg_match_all('/(\d)\1\1\1\1/', $str, $matches);
echo print_r($matches);
даст следующий результат:
Array
(
[0] => Array
(
[0] => 44444
[1] => 88888
[2] => 55555
[3] => 22222
[4] => 55555
[5] => 00000
)
[1] => Array
(
[0] => 4
[1] => 8
[2] => 5
[3] => 2
[4] => 5
[5] => 0
)
)
В первый элемент массива помещён массив с найденными строками из пяти цифр. Во второй элемент массив помещён массив, соответствующий подмаскам — то есть одиночным цифрам. Но взяты не любые одиночные цифры — совпавшие значения подмасок взяты только в тех случаях, когда весь шаблон совпал со строкой.
Рассмотрим более практический пример. Допустим мы хотим найти в HTML коде все пары тэгов: открывающий и закрывающий тэг, между которыми идёт какой-либо текст. Есть исключения (например, <br />, <hr /> и так далее) — но не будем их рассматривать, чтобы не усложнять пример.
Тэг абзаца выглядит примерно так:
<p>Это абзац</p>
Тэг раздела страницы:
<div>А это раздел</div>
Как мы видим, в угловые скобки помещено название тэга, которое представляет собой одну или более маленьких букв. Закрывающим тэгом является эта же самая конструкция, с этим же самым названием тэга, но перед названием добавляется слэш /.
Любая буква в угловых скобках обозначается так:
/<[a-z]+>/
Чтобы создать обратную ссылку, поместим ту часть выражения, которая обозначает буквы, в круглые скобки:
/<([a-z]+)>/
Закрывающим тэгом будет обратная ссылка, содержащая найденное название тэга, помещённая между </ и >, то есть:
</\1>
Поскольку в качестве разделителя используется слэш, то тот слэш, который означает «буквальный слэш» нужно экранировать, чтобы он потерял своё специальное значение и стал трактоваться как буквальный символ, получаем:
<\/\1>
Собираем вместе:
/<([a-z]+)><\/\1>/
Составленное регулярное выражение будет соответствовать тэгам в следующем написании:
<p></p> <div></div>
Но нужно помнить, что между тэгами почти всегда есть какой-то текст. В качестве этого тэга может быть что угодно, кроме символа <, «что угодно кроме символа < любое количество раз, в том числе и ноль» записывается следующим образом:
[^<]*
Помещаем это конструкцию в нужное место нашего регулярного выражения:
/<([a-z]+)>[^<]*<\/\1>/
Открывающий тэг может содержать атрибуты, а может их и не содержать.
Тэг абзаца без атрибутов:
<p>
Тэг абзаца с атрибутами:
<p style="text-align: justify;">
Для написания атрибутов и их свойств используется ограниченный набор символов, но в него точно не входит символ >, поскольку этот символ означает завершение открывающего тэга, поэтому значение «пусто, либо пробел а затем любые символы кроме > любое количество раз» на языке регулярных выражений записывается так:
(| [^>]*)
Помещаем эту конструкцию в ранее составленное регулярное выражение в то место, где могут быть атрибуты:
/<([a-z]+)(| [^>]*)>[^<]*<\/\1>/
Пример кода:
<?php
$link = 'https://hackware.ru/?p=7916';
$agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36';
$ch = curl_init($link);
curl_setopt($ch, CURLOPT_USERAGENT, $agent);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$response_data = curl_exec($ch);
if (curl_errno($ch) > 0) {
die('Ошибка curl: ' . curl_error($ch));
}
curl_close($ch);
$count = preg_match_all ('/<([a-z]+)(| [^>]*)>[^<]*<\/\1>/', $response_data, $found);
echo 'Всего найдено совпадений: ' . $count . "\r\n";
print_r($found[0]);
Пример результата:

Функции PHP для поиска и замены по регулярному выражению
Рассмотренные ранее функции ищут строки по регулярному выражению (preg_match_all), либо проверяют, строку на соответствие регулярному выражению (preg_match). В случае, если нужно не просто найти строку, но и заменить её, используются следующие функции:
- preg_filter — Производит поиск и замену по регулярному выражению
- preg_replace_callback_array — Выполняет поиск и замену по регулярному выражению с использованием функций обратного вызова
- preg_replace_callback — Выполняет поиск по регулярному выражению и замену с использованием callback-функции
- preg_replace — Выполняет поиск и замену по регулярному выражению
В результате работы функции preg_replace, если найдены совпадения, возвращается новая версия subject, иначе subject возвращается нетронутым. Функция preg_filter() идентична функции preg_replace() за исключением того, что возвращает только те значения (возможно, преобразованные), в которых найдено совпадение. Подробнее о работе функций читайте по приведённым выше ссылкам.
Функция preg_replace_callback позволяет делать интеллектуальную замену. Её суть заключается в том, что не просто выполняется замена найденной строки, а вызывается функция, которой передаётся совпавшая строка, и эта функция уже и возвращает строку с заменой. Вместо элементарной замены, функция может, например, делать дополнительную проверку полученных данных и уже на основе принятого решения выполнять ту или иную замену. Можно установить счётчик и делать замену в каждом n-ной совпавшей строке — например, в каждой третьей или каждой десятой. Можно пронумеровать найденные строки и делать любые другие изменения, которые не ограничиваются обычным поиском и заменой на фиксированную строку.
Пример использование функции preg_replace_callback:
<?php
$output = 'AnnJohnBobAlexJimmJaneDariaDorryRonnyRichardLeoSusyJastinRoiAntony';
$counter = 0;
$a1 = "Третье имя: ";
$a2 = "Номер этого имени кратен 10: ";
$output = preg_replace_callback(
"/[A-Z]{1}[a-z]+/",
function ($matches) use (&$counter, $a1, $a2) {
$counter++;
if($counter == 3) {
return $a1 . $matches[0] . "\r\n";
}
elseif ($counter % 10 == 0) {
return $a2 . $matches[0] . "\r\n";
}
else {
return $matches[0] . "\r\n";
}
},
$output
);
echo $output;
В этом примере из монотонной строки будут выбраны имена и каждое имя будет напечатано по отдельности. Для третьего имени будет написано, что это третье имя, для каждого десятого имени будет написано, что его номер кратен 10:
Ann John Третье имя: Bob Alex Jimm Jane Daria Dorry Ronny Номер этого имени кратен 10: Richard Leo Susy Jastin Roi Antony
Пример моего реального недавнего использования функции preg_replace_callback на практике — добавления рекламы в каждый десятый комментарий — с её помощью очень легко реализовать подобную логику.
Другие функции PHP для работы с регулярными выражениями
- preg_last_error — Возвращает код ошибки выполнения последнего регулярного выражения PCRE
- preg_quote — Экранирует символы в регулярных выражениях
- preg_split — Разбивает строку по регулярному выражению
Когда не нужно использовать регулярные выражения
Не используйте функцию preg_match(), если необходимо проверить наличие подстроки в заданной строке. Используйте для этого strpos() поскольку она выполнит эту задачу гораздо быстрее.
Если вам не нужна мощь регулярных выражений, то вместо preg_split вы можете выбрать более быстрые (хоть и простые) альтернативы наподобие explode() или str_split().
Источники
- http://php.net/manual/ru/book.pcre.php
- https://stackoverflow.com/questions/2301285/what-do-lazy-and-greedy-mean-in-the-context-of-regular-expressions
Связанные статьи:
- Регулярные выражения в PHP (ч. 1) (100%)
- Какой язык программирования выбрать для изучения (53.9%)
- Как запустить PHP скрипт без веб-сервера (53.9%)
- Списки прокси (53.9%)
- ASCII и шестнадцатеричное представление строк. Побитовые операции со строками (50%)
- Как использовать User Agent для атак на сайты (RANDOM - 3.9%)
здравствуйте! не совсем понял как работает вот такая запись (?i) в регулярном выражении, что она значит?
(?i)^([a-z0-9]([a-z0-9\-]{0,61}[a-z0-9])?\.)+[a-z]{2,6}$
Приветствую! Посмотрите раздел «Внутренние (локальные) модификаторы шаблонов».
В данном регулярном выражении фрагмент «(?i)» означает включение регистронезависимого поиска (поиск без учёта регистра).